上一篇
分布式数据挖掘
分布式数据挖掘通过分布式计算框架实现海量数据高效处理,依托多节点协同完成特征提取、模式识别及算法优化,支撑大规模集群
核心原理与技术架构
分布式数据挖掘的核心在于将数据和计算任务分解到多个节点并行处理,最终整合结果,其技术架构通常包含以下层次:
| 层级 | 功能描述 |
|---|---|
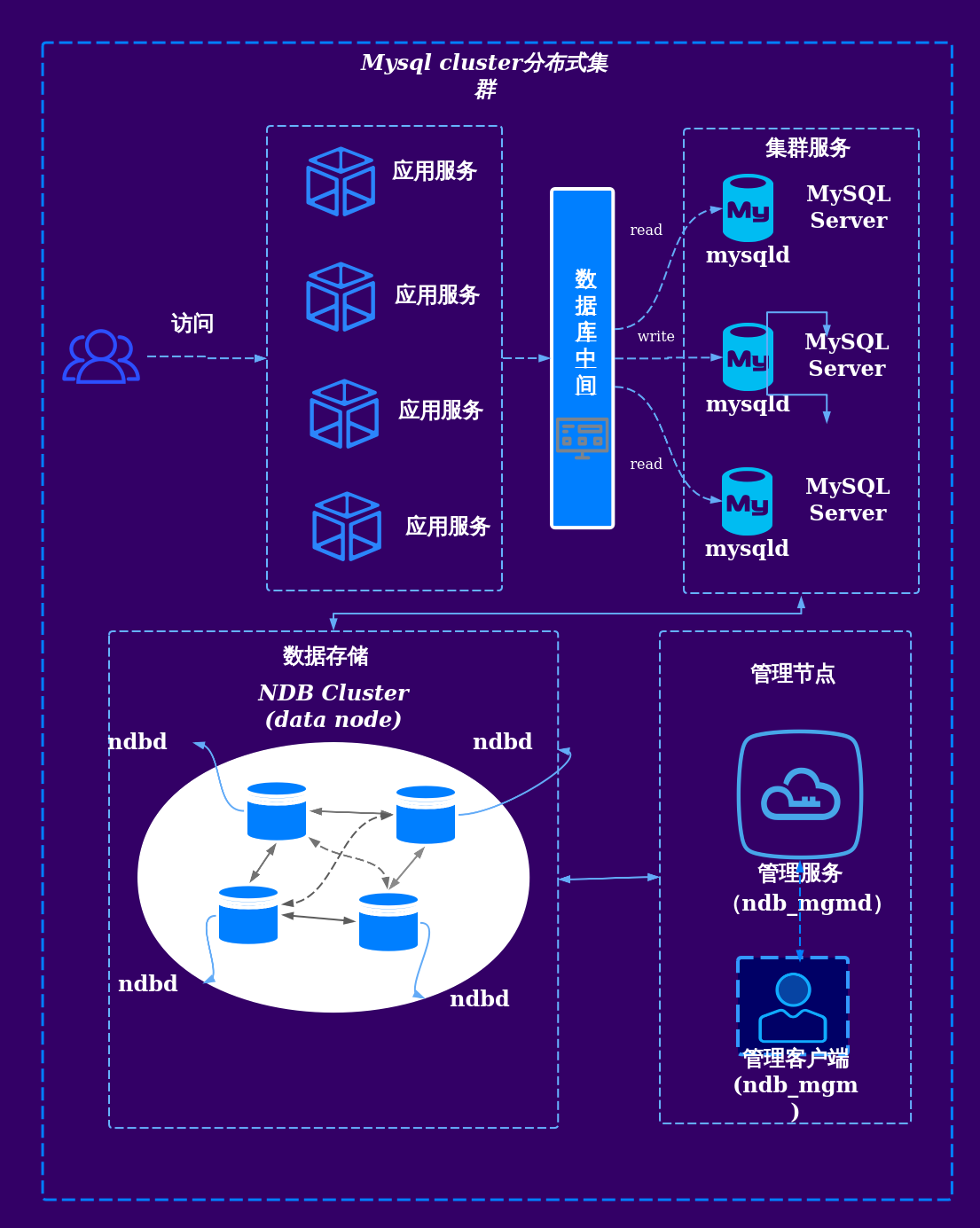
| 数据存储层 | 采用分布式文件系统(如HDFS、Ceph)或数据库(如HBase、Cassandra)存储海量数据,支持水平扩展。 |
| 计算调度层 | 通过分布式计算框架(如Spark、Flink)协调任务分配,管理节点间的通信与资源调度。 |
| 算法执行层 | 实现分布式版本的数据挖掘算法(如分布式聚类、分类、关联规则挖掘),支持参数同步与结果合并。 |
| 服务接口层 | 提供API或可视化工具,方便用户提交任务并获取分析结果。 |
关键技术解析
分布式存储技术
- 分片与副本机制:数据按块分割后存储在不同节点,并通过副本保证容错性(如HDFS的3副本策略)。
- 数据局部性优化:计算任务优先分配到存储数据的节点,减少网络传输开销(如Spark的RDD设计)。
并行计算模型
- MapReduce:将任务拆分为Map(数据分片处理)和Reduce(结果汇总)阶段,适用于批处理场景。
- BSP模型:通过超步(Superstep)同步节点状态,适合迭代型算法(如PageRank、K-Means)。
- 流式计算:基于时间窗口的实时处理(如Flink的窗口操作),用于动态数据流挖掘。
算法分布式改造

- 模型并行:将模型参数分布到不同节点(如深度学习中的参数服务器架构)。
- 数据并行:每个节点处理不同数据分片,最后聚合结果(如分布式决策树的投票机制)。
- 通信优化:采用AllReduce、参数广播等技术减少节点间通信延迟(如Horovod框架)。
容错与一致性
- 任务重试机制:节点故障时自动重新分配任务(如YARN的ResourceManager)。
- 检查点(Checkpoint):定期保存中间状态,避免从头计算(如Spark Streaming的Stateful操作)。
- 一致性协议:通过Paxos或Raft算法保证分布式环境下的数据一致性(如分布式事务处理)。
典型应用场景
| 场景 | 需求特点 | 技术方案 |
|---|---|---|
| 电商推荐系统 | 高并发、实时更新用户画像 | Spark+Kafka流式处理,ALS算法分布式训练 |
| 金融风控预警 | 低延迟、高准确率检测欺诈行为 | Flink实时特征计算,XGBoost分布式版本 |
| 社交网络分析 | 大规模图数据处理 | GraphX(Spark子库)或Pregel模型 |
| 物联网设备监控 | 边缘节点数据采集与中心化分析 | Edge-Cloud协同架构,轻量级模型(如TinyML) |
挑战与解决方案
数据倾斜问题
- 现象:部分节点负载过高,导致任务延迟。
- 解决:预处理阶段采样均衡数据,或采用Rebalanced分区策略(如Spark的自定义Partioner)。
通信瓶颈
- 现象:节点间频繁数据传输导致带宽占用。
- 解决:压缩传输数据(如Snappy编码),或使用参数服务器减少同步频率。
模型一致性保障
- 挑战:分布式训练中参数更新冲突。
- 方案:异步更新(容忍短期不一致)或同步更新(牺牲部分性能保证一致性)。
系统扩展性
- 难点:新增节点时数据迁移与负载均衡。
- 优化:采用一致性哈希分配数据,或使用容器化技术(如Kubernetes)动态扩缩容。
未来发展趋势
- 混合云与边缘计算结合:通过分布式架构实现云-边-端协同,降低中心节点压力。
- 联邦学习集成:在保护隐私的前提下,联合多个节点训练模型(如TensorFlow Federated)。
- AI编排优化:利用强化学习动态调整任务分配策略,提升资源利用率。
FAQs
问题1:分布式数据挖掘与集中式数据挖掘的核心区别是什么?
答:集中式数据挖掘依赖单机资源,受限于内存、CPU和存储容量,难以处理PB级数据;而分布式数据挖掘通过多节点协同,突破硬件瓶颈,支持横向扩展,适合大规模、高并发场景,分布式系统需额外解决节点通信、数据一致性等问题。
问题2:如何选择适合的分布式计算框架?
答:需根据业务需求权衡以下几点:
- 实时性要求:批处理选Spark/Hadoop,流处理选Flink/Storm。
- 开发成本:Spark生态成熟且易用,Flink适合复杂事件处理。
- 数据规模:小规模可选本地模式,大规模需集群部署。
- 硬件环境:容器化框架(如Kubernetes)适配云原生环境,而YARN适合传统Hadoop集群。