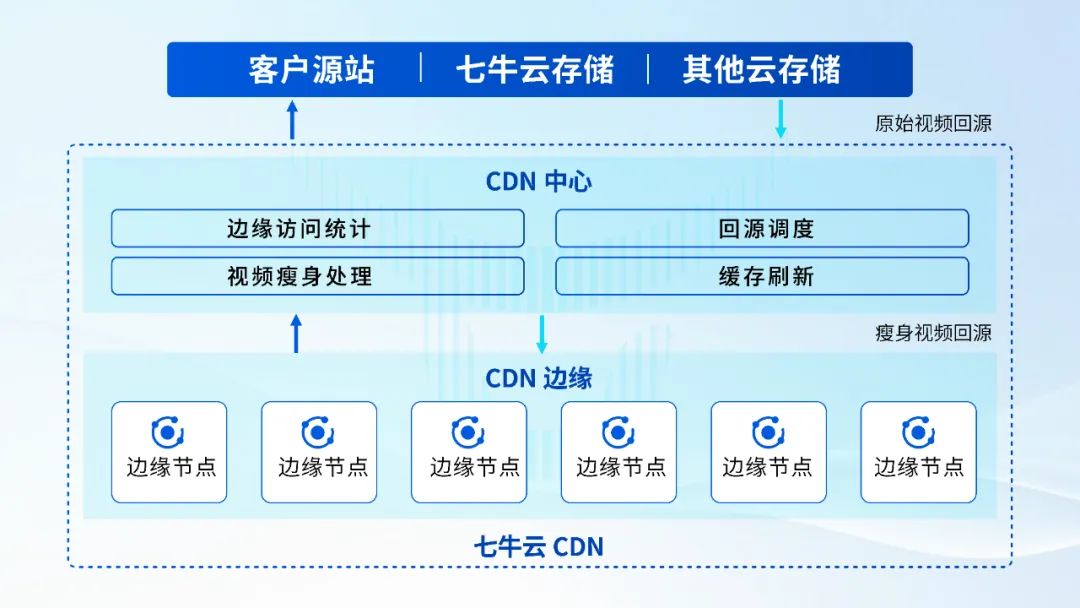
上一篇
如何让你的数据开口说话,词云与词频可视化究竟藏着哪些流量密码?
词云通过视觉化展示文本高频词汇,利用字体大小突出关键词分布;词频统计借助表格或柱状图量化词语出现频率,两者结合可直观呈现文本特征,适用于舆情分析、内容挖掘及数据报告等场景,常用Python的WordCloud、Matplotlib库实现。
在数字化信息爆炸的时代,词云(Word Cloud)和词频数据可视化成为快速洞察文本核心内容的重要工具,无论是市场调研报告、社交媒体舆情分析,还是学术论文的关键词提取,这种直观的视觉呈现方式都能帮助用户快速抓住重点,本文将详细解析如何创建词云、分析词频,并展示符合专业标准的可视化效果。
词云和词频分析的意义
词云通过字体大小或颜色差异,反映文本中高频词汇的重要性;词频统计则量化词语出现的次数,揭示文本的主题分布,两者的结合能帮助用户:
- 快速定位核心主题:例如分析用户评论中的高频词,了解产品优缺点;
- 简化复杂数据:将长篇报告浓缩为可视化图表,便于汇报或传播;
- 支持决策参考:企业可通过舆情词频调整营销策略。
工具推荐:从代码到零门槛平台
针对不同用户需求,推荐以下工具:
编程工具(适合开发者)

- Python:使用
WordCloud库生成自定义词云,结合jieba(中文分词)或nltk(英文分词)统计词频。 - R语言:通过
tm包进行文本挖掘,wordcloud2生成动态词云。
- Python:使用
在线平台(零代码)
- WordArt:支持自定义形状、颜色和字体,导出高清图片。
- Tableau Public:连接Excel或CSV数据,制作交互式词频仪表盘。
- 微词云(中文友好):内置热门模板,可直接导入微信文章或电商评论。
四步生成专业词云
以Python为例,手把手演示流程:
第一步:数据准备与清洗
import jieba
from wordcloud import WordCloud
text = "需要分析的文本(如用户评论、新闻内容)"
# 去除停用词(如“的”“了”)
stopwords = set(open("stopwords.txt").read().split())
words = jieba.lcut(text)
cleaned_text = " ".join([word for word in words if word not in stopwords])第二步:生成词频统计
from collections import Counter word_freq = Counter(cleaned_text.split()) top20_words = word_freq.most_common(20) # 输出前20高频词
第三步:设计词云样式
wc = WordCloud(
font_path="SimHei.ttf", # 中文字体路径
background_color="white",
max_words=100,
mask=自定义形状图片 # 可选心形、地图等轮廓
)
wc.generate_from_frequencies(word_freq)第四步:保存与导出
wc.to_file("wordcloud.png")提升可视化专业性的技巧
避免常见误区
- 停用词未过滤干净 → 干扰核心主题;
- 颜色对比度不足 → 重要词汇不突出。
增强可读性
- 英文文本优先使用
sans-serif字体(如Arial); - 中文推荐使用思源黑体或阿里巴巴普惠体。
- 英文文本优先使用
高级应用场景
- 时间序列词云:对比不同时段的关键词演变;
- 情感分析结合词频:用颜色区分正面(绿色)/负面(红色)词汇。
数据可信度的关键
- 数据源标注:注明文本采集范围(如“2025年1-6月微博评论”);
- 算法透明度:公开分词工具和停用词表版本(如“jieba-0.42.1”);
- 引用规范:若使用科研数据,需注明出处(如“CNKI数据库”)。
参考文献
- WordCloud官方文档. https://github.com/amueller/word_cloud
- NLTK文本处理指南. https://www.nltk.org/book/
- 阿里巴巴普惠体下载. https://alibabafont.taobao.com/