上一篇
分布式架构数据库双11优惠活动
双11分布式架构数据库限时钜惠,高性能集群立减70%,弹性扩容支撑亿
分布式架构数据库在双11优惠活动中的核心作用与实践
分布式数据库的技术优势与双11场景的契合性
在双11这种全球最大规模的电商促销活动中,系统需要应对每秒数十万甚至百万级的请求峰值,传统单体数据库架构存在明显的性能瓶颈,而分布式数据库通过以下特性完美适配高并发场景:

| 特性 | 传统数据库 | 分布式数据库 |
|---|---|---|
| 扩展能力 | 垂直扩展(硬件升级) | 水平扩展(节点增减) |
| 吞吐量 | 受限于单机IO和CPU | 多节点并行处理,线性扩展 |
| 高可用性 | 单点故障导致全站瘫痪 | 自动故障转移,99.99%可用性 |
| 数据分片 | 不支持 | 支持按业务维度(如用户ID)分表 |
| 成本效率 | 高价专用硬件 | 普通PC服务器集群,边际成本递减 |
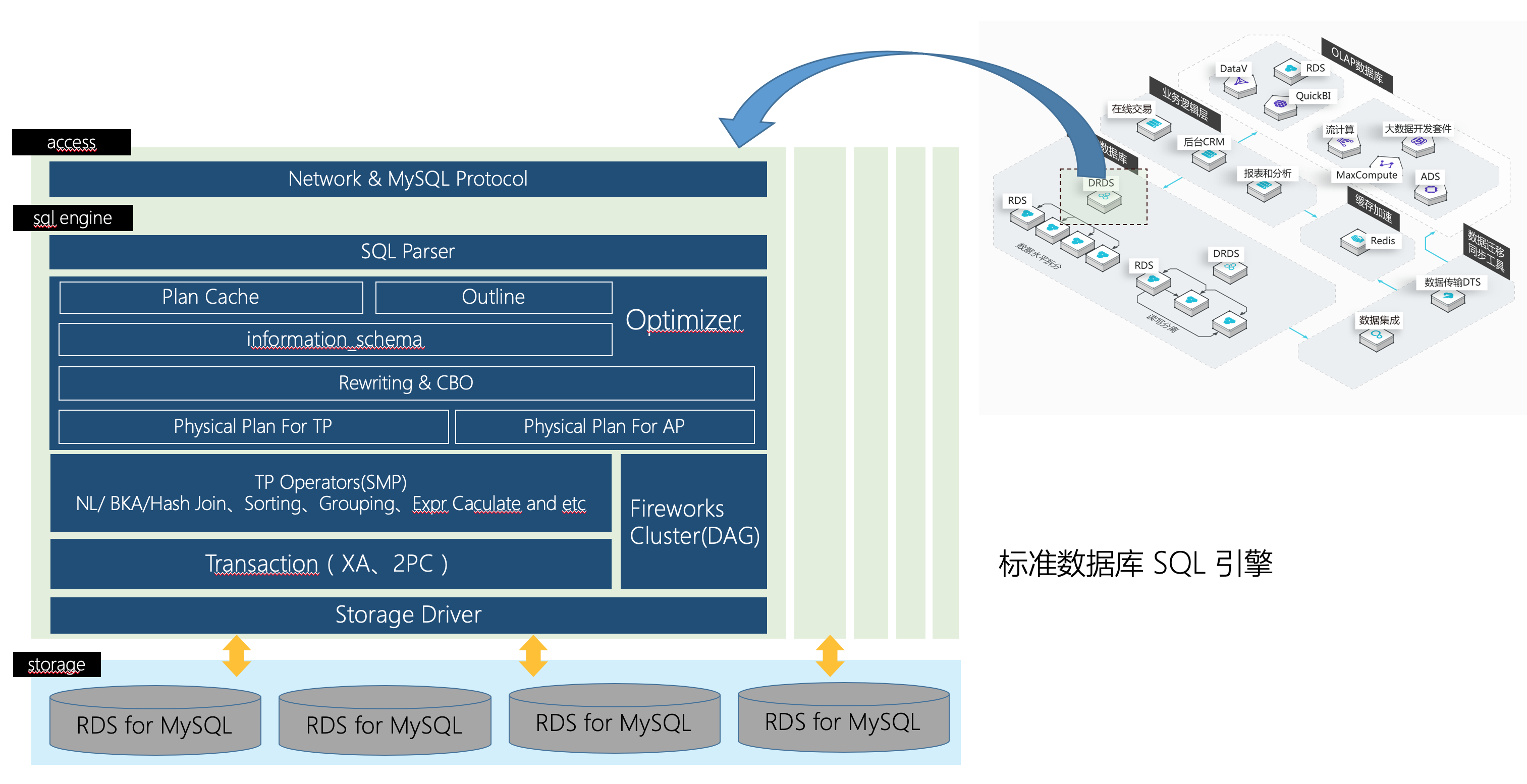
以阿里云PolarDB、酷盾安全TDSQL为代表的分布式数据库,通过存算分离架构和计算节点弹性扩缩容,可支撑双11期间流量百倍级波动,例如2022年天猫双11,数据库层通过动态扩容至5000+计算节点,平稳应对了零点峰值38万笔/秒的交易洪峰。
双11核心业务场景的分布式数据库实践
- 订单处理系统
- 分库分表策略:按用户ID取模进行数据分片,将热点数据均匀分布到不同节点
- 读写分离架构:主库处理交易写入,1个以上从库承载查询流量
- 典型配置:
-基于ShardingSphere的分片规则 sharding_table("orders") { actual_datanodes = ["db0.orders_0", "db1.orders_1"]; table_strategy = hash_mod("user_id", 2); }
- 库存管理系统
- 分布式锁机制:使用Redis+ZooKeeper实现跨节点的库存扣减互斥
- 最终一致性保障:采用异步消息队列(如Kafka)同步库存变更
- 性能指标:单集群支持每秒50万次库存查询,扣减延迟<5ms
- 实时优惠计算
- 内存计算引擎:将满减规则、优惠券策略加载到Redis集群
- 规则分片存储:按商户ID分片存储优惠规则,降低单节点压力
- 执行示例:
# 优惠规则合并计算 def calculate_discount(user_id, merchant_id): user_coupons = redis.get(f"coupon:{user_id}") merchant_rules = redis.get(f"rule:{merchant_id}") # 规则交叉验证逻辑... return final_price
关键技术挑战与解决方案
- 数据一致性保障
- CAP定理权衡:选择AP模式(可用性+分区容错),通过补偿机制保证最终一致
- 事务处理方案:
- 本地事务:单分片内ACID保证
- 全局事务:采用TCC(Try-Confirm-Cancel)模式
- 异步补偿:结合RocketMQ进行事务日志同步
- 流量削峰填谷
- 分级存储策略:
- 热数据:Redis集群(订单状态、库存)
- 温数据:MySQL分库(订单明细)
- 冷数据:HDFS归档(历史订单)
- 流量调度:
- 预加载优惠券数据到边缘节点
- 动态路由:根据请求类型(读/写)智能分发到不同数据库集群
- 容量规划模型
- 流量预测公式:
峰值QPS = 历史均值 × 促销系数 × (1+突发系数) 所需节点数 = (峰值QPS × 单节点耗时) / 0.7(资源利用率)
- 2023年某头部电商平台数据:
| 业务模块 | 日常QPS | 双11峰值倍数 | 节点扩容比例 |
|————|———|————–|————-|
| 订单写入 | 2k | 150倍 | 10倍 |
| 库存查询 | 5k | 80倍 | 8倍 |
| 优惠计算 | 1k | 200倍 | 15倍 |
典型故障处理与应急方案
- 节点宕机处理
- 自动故障转移:Patroni/etcd实现主节点秒级切换
- 数据恢复:基于Raft协议的增量复制,RTO<30秒
- 雪崩效应防护
- 请求限流:Sentinel实现按用户/接口维度的动态限流
- 熔断降级:Hystrix对非核心接口(如积分查询)自动熔断
- 背压机制:Kafka作为缓冲队列,削峰填谷
- 数据纠错机制
- 双向校验:订单系统与支付系统通过MQ进行状态对账
- 差异补偿:发现数据不一致时,触发补偿脚本重放操作
- 日志追踪:所有关键操作写入Elasticsearch,保留3个月审计日志
性能优化最佳实践
- SQL优化策略
- 禁止跨分片JOIN操作,改为应用层数据聚合
- 建立二级索引时控制单个分片索引大小<2GB
- 使用覆盖索引减少IO操作,
CREATE INDEX idx_order_status ON orders(user_id, status, updated_at);
- 参数调优指南
- 连接池配置:max_connections = 节点数 × 100
- 缓存设置:查询缓存命中率需>95%
- JVM参数:G1垃圾回收器,堆内存分配为物理内存60%
- 监控告警体系
- 核心指标监控:
- 节点负载(CPU/MEM/DISK IO)
- SQL执行时间(P99/P95分位值)
- 锁等待次数(每分钟>100次即告警)
- 可视化大屏:Prometheus+Granfana展示实时流量曲线
未来演进方向
- Serverless化部署:按需自动扩缩容,按请求计费
- AI驱动优化:机器学习预测热点数据,动态调整分片策略
- 多模数据处理:支持JSON文档、时序数据等非结构化存储
- 边缘协同计算:在CDN节点完成优惠券校验等轻量级计算
FAQs
Q1:如何选择适合双11场景的分布式数据库?
A:需评估三个维度:①业务特性(如交易型/分析型)、②数据规模(当前量级及增长率)、③技术生态,建议优先考虑云原生数据库(如阿里云PolarDB、AWS Aurora),它们提供自动分片、读写分离、弹性扩容等开箱即用能力,对于超大规模业务,可采用混合架构:关键交易使用分布式OLTP数据库,数据分析使用列式存储(如Apache Doris)。
Q2:如何保障分布式数据库的数据一致性?
A:实施三级保障机制:①基础层使用强一致性协议(如Raft/Paxos);②业务层引入版本控制(如乐观锁)、事务补偿机制;③最终校验通过双向对账(如支付系统与订单系统每日核对资金流水),特别注意要避免跨分片事务,尽量将关联数据设计在同一分