上一篇
H数据库事务提交失败?如何快速解决这一难题?
数据库事务提交失败通常由网络异常、资源竞争或死锁引发,可能导致数据不一致及业务中断,建议检查连接状态、优化事务逻辑,并查看错误日志定位具体原因,必要时调整隔离级别或重试机制以确保数据完整性。
原因分析与解决方案
在使用H数据库时,事务提交失败是一个可能遇到的常见问题,它会直接影响数据的一致性和业务操作的可靠性,本文将详细解释这一问题的潜在原因,并提供可操作的解决方案,帮助用户快速排查和恢复数据库的正常运行。
事务提交失败的可能原因
网络或硬件异常
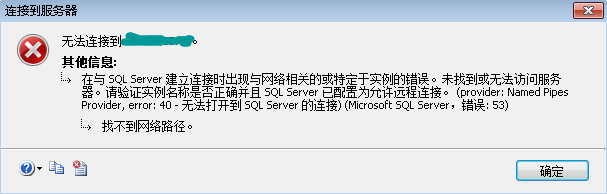
数据库服务器与客户端之间的网络波动、硬件故障(如磁盘损坏)可能导致事务提交过程中断,如果事务日志无法写入存储设备,提交操作会直接失败。
资源竞争与死锁
多个事务同时竞争同一资源(如某条记录或表)时,可能触发死锁,H数据库的锁管理器会自动终止其中一个事务以解除死锁,但被终止的事务会提交失败。资源不足
- 日志空间耗尽:事务日志文件(如Redo Log)已满,无法记录新的操作。
- 内存不足:事务处理所需的缓冲区或临时内存不足。
- 连接数超限:数据库连接池达到最大限制,新事务无法分配资源。
代码逻辑错误
- 未正确开启或关闭事务(例如忘记提交或回滚)。
- 事务嵌套层级错误,导致提交时机混乱。
- SQL语句存在语法错误或约束冲突(如唯一键重复)。
权限问题
执行事务的用户缺乏必要的权限(如对表的写入权限、事务提交权限等)。数据库配置不当
- 事务隔离级别设置过高(如“可串行化”)可能增加锁冲突概率。
- 日志文件大小或自动扩展策略不合理。
解决方法与操作步骤
步骤1:检查网络与硬件状态
- 使用
ping、telnet等工具验证数据库服务器的连通性。 - 通过数据库管理工具查看磁盘空间占用情况(如执行
df -h命令)。 - 若发现硬件问题,及时联系运维团队修复。
步骤2:排查死锁与资源竞争
- 查看死锁日志:在H数据库的管理控制台或日志文件中搜索“deadlock”关键字,定位冲突的事务。
- 优化SQL语句:通过索引优化、批量操作减少锁竞争,避免长事务或频繁更新同一行数据。
- 调整隔离级别:将事务隔离级别从“可串行化”降级为“读已提交”,降低锁冲突概率。
步骤3:释放数据库资源
- 清理日志文件:扩展事务日志的存储空间,或归档旧日志(需根据数据库版本操作)。
- 释放闲置连接:执行
SHOW PROCESSLIST命令查看活跃连接,终止长期未活动的会话。 - 优化内存配置:调整
innodb_buffer_pool_size等参数,确保内存分配合理。
步骤4:检查代码与SQL语句
- 添加异常处理机制:在代码中捕获事务异常并重试提交(需设置重试次数上限)。
try { connection.commit(); } catch (SQLException e) { // 记录日志并重试 } - 验证SQL约束:确保插入或更新的数据不违反唯一性、外键等约束条件。
- 避免长事务:拆解复杂操作为多个短事务,减少锁持有时间。
步骤5:核对用户权限
- 通过
GRANT语句为用户授予完整的事务权限:GRANT INSERT, UPDATE, DELETE ON database.table TO 'user'@'host';
步骤6:优化数据库配置
- 调整日志文件参数:增大
innodb_log_file_size以容纳更多事务日志。 - 启用自动扩展:配置日志文件自动扩展,避免突发流量导致日志写满。
预防措施
- 建立监控机制
部署数据库监控工具(如Prometheus、Zabbix),实时跟踪事务提交成功率、锁等待时间等指标。 - 定期维护
- 清理历史数据和冗余索引。
- 定期备份事务日志并测试恢复流程。
- 代码审查与测试
在开发阶段通过单元测试、压力测试提前发现事务逻辑缺陷。 - 权限最小化原则
仅授予用户必要的数据库权限,避免误操作导致事务失败。
专业建议
- 若问题反复出现,建议导出数据库日志并联系H数据库官方技术支持。
- 在高并发场景下,可考虑引入分布式事务框架(如Seata)或消息队列(如Kafka)解耦事务操作。
- 始终确保操作前备份数据,防止事务失败导致数据丢失。
引用说明
本文参考了以下资料:
- H数据库官方文档《事务管理与故障恢复》
- Stack Overflow技术社区关于数据库死锁的讨论
- 《数据库系统概念(第七版)》,Abraham Silberschatz等编著