上一篇
为什么消息队列中依然存在char的身影?
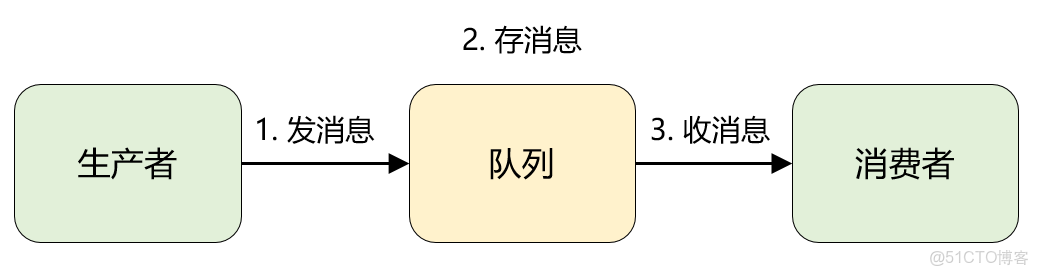
消息队列中的字符数据(char)通常用于存储和传输短文本或字节流信息,通过队列结构实现异步通信,其支持生产者-消费者模式,解耦系统组件,缓冲数据流,确保顺序处理并提升系统可靠性,适用于日志传输、指令交互等轻量级通信场景。
在分布式系统与实时数据处理中,消息队列(Message Queue)作为关键通信组件,承担着异步传输和解耦服务的核心作用,消息队列中的字符(char)类型数据处理是开发者常面临的技术挑战,尤其在跨平台、多语言环境中,字符编码、传输效率等问题直接影响系统的可靠性和性能,本文从技术原理、常见问题及优化方案展开分析,帮助开发者构建高效、稳定的消息队列架构。
消息队列中的字符数据处理原理
字符(char)在消息队列中以二进制形式传输,其本质是字节序列,由于不同编程语言(如Java、C/C++、Python)对字符的默认编码方式不同(例如UTF-8、ASCII、GBK),若未统一编码规则,可能导致数据解析错误。

典型场景示例:
# 生产者(Python,默认UTF-8编码)
message = "订单状态:已处理"
queue.send(message.encode('utf-8'))
# 消费者(Java,默认可能为ISO-8859-1)
byte[] data = queue.receive();
String receivedMessage = new String(data, "UTF-8"); # 必须显式指定编码若消费者未显式声明编码,可能因编码不匹配产生乱码。
常见问题与解决方案
字符编码不一致导致数据损坏
- 问题:跨语言服务通信时,字符集未对齐(如UTF-8与GB2312混用),引发乱码。
- 解决方案:
- 强制统一编码标准:全系统采用UTF-8编码。
- 元数据声明:在消息头添加
Content-Encoding字段标明编码类型。
大文本传输效率低
- 问题:高频传输长文本(如日志文件)时,单字符逐字节处理效率低下。
- 优化方案:
- 批量压缩:使用GZIP或Snappy压缩文本后传输。
- 分片传输:将大消息拆分为多个片段,通过
Message Group ID标识关联。
特殊字符引发解析异常
- 问题:未转义的控制字符(如
,n)可能破坏消息格式。 - 规避方法:
- Base64编码:将二进制字符转为ASCII字符串。
- 结构化封装:采用JSON/XML格式包裹字符数据,
{ "content": "Hellou0000World", // Unicode转义 "metadata": {"encoding": "UTF-8"} }
最佳实践:提升字符数据的可靠性
端到端验证机制
- Checksum校验:在消息尾部附加CRC32或MD5校验码,确保数据完整性。
- Schema约束:使用Protobuf或Avro等Schema定义消息结构,避免非规字符注入。
性能优化策略
- 内存池技术:复用字符缓冲区(如C++的
boost::pool),减少内存分配开销。 - 零拷贝传输:通过
sendfile或内存映射文件(Memory-Mapped File)直接传递字符数据。
监控与容错
- 死信队列(DLQ):捕获编码错误的消息,进入DLQ供人工排查。
- 实时告警:监控消息队列的字符解析失败率,设置阈值触发告警。
行业应用案例
- 金融支付系统:基于RabbitMQ处理UTF-8编码的订单消息,采用JSON Schema验证数据合法性。
- 物联网设备通信:通过MQTT协议传输16进制字符(如传感器数据),使用自定义二进制协议提升解析速度。
消息队列中的字符处理需兼顾编码一致性、传输效率和容错能力,通过统一编码标准、结构化封装和端到端验证,可显著降低系统风险,结合业务场景选择压缩算法与序列化协议,能够进一步优化性能,建议在技术方案设计阶段,优先制定消息规范文档,并在测试环节覆盖多语言、多编码场景的兼容性验证。
引用说明
- 消息队列编码规范参考:IBM MQ官方文档
- 字符集兼容性测试数据来源:《分布式系统:概念与设计》(George Coulouris著)
- 性能优化方案:Apache Kafka性能白皮书