
上一篇
GPU服务器真的是深度学习的加速神器吗?
GPU服务器通过并行计算加速深度学习训练,其强大的图形处理能力可高效执行矩阵运算等复杂操作,配备NVIDIA Tesla等专业显卡及CUDA加速架构,支持TensorFlow/PyTorch框架,可将训练时间从数周缩短至数小时,适用于图像识别、自然语言处理等场景,显著提升研发效率。
为什么GPU服务器是深度学习的核心引擎?
深度学习作为人工智能领域的重要分支,其模型训练对计算资源的要求远超传统算法,GPU(图形处理器)服务器因其并行计算能力成为深度学习的“加速器”,以下是其核心原理及应用的全面解析。
GPU服务器的核心优势
并行计算能力
GPU拥有数千个核心(如NVIDIA A100的6912个CUDA核心),可同时处理数万个线程,而CPU通常仅有数十个核心,这种架构让GPU在矩阵运算(如卷积、梯度计算)中效率提升10-100倍。专用硬件加速
- Tensor Core(NVIDIA):专为混合精度计算设计,加速Transformer、BERT等大模型训练。
- RT Core:在推理任务中优化光线追踪,用于自动驾驶仿真、3D建模。
显存带宽与容量
高端GPU(如H100)提供80GB HBM2e显存,带宽达3TB/s,可支撑数十亿参数模型的批量数据处理,避免频繁的CPU-GPU数据传输瓶颈。
GPU服务器的关键配置指南
| 组件 | 推荐配置 | 适用场景 |
|---|---|---|
| GPU型号 | NVIDIA A100/A800、H100;AMD MI250 | 大规模训练、多机分布式计算 |
| CPU | AMD EPYC 7xx3/Intel Xeon Scalable | 避免数据预处理成为瓶颈 |
| 内存 | ≥512GB DDR4 ECC | 支持GPU显存交换 |
| 存储 | NVMe SSD RAID阵列(≥10TB) | 高速读取百万级图像数据集 |
| 网络 | 100Gbps InfiniBand/NVLink | 多GPU卡间低延迟通信 |
典型应用场景与性能对比
计算机视觉
- 案例:训练ResNet-50
- CPU(28核):约30天
- 单卡A100:6小时
- 8卡集群:<1小时
- 案例:训练ResNet-50
自然语言处理
- GPT-3训练:使用1024颗A100 GPU,耗时1个月;若用CPU需数年。
科学计算
分子动力学模拟(如GROMACS):GPU加速后效率提升50倍。
如何选择GPU服务器?
按需求选型
- 入门级:1-2颗RTX 4090(24GB显存),适合小模型与算法验证。
- 企业级:8颗A100/H100组成的DGX系统,支持千亿参数模型训练。
云计算 vs 本地部署
- 云服务(AWS EC2 P4d、阿里云GN7):按需付费,适合弹性需求。
- 本地集群:长期高负载场景下成本更低,但需专业运维。
软件生态支持
优先选择兼容CUDA、ROCm的平台,确保PyTorch、TensorFlow等框架的版本匹配。
优化技巧与常见问题
显存不足的解决方案
- 梯度累积:减小batch size,多次前向传播后统一更新权重。
- 混合精度训练:使用FP16/FP32混合模式(需GPU支持)。
多卡并行策略
- 数据并行:每张GPU载入完整模型,拆分数据批次(推荐NCCL后端)。
- 模型并行:将大型网络层拆分到不同GPU(如Megatron-LM)。
监控工具
- DCGM:实时查看GPU利用率、显存占用。
- Prometheus+Grafana:集群级性能仪表盘。
常见问题解答
Q1:是否需要购买物理服务器?
- 中小团队建议优先采用云服务,避免硬件迭代风险,谷歌Colab Pro每月$10即可使用V100 GPU。
Q2:为什么训练时GPU利用率低?
- 可能瓶颈:数据加载慢(换用NVMe SSD)、CPU预处理延迟(增加并行线程)、小批量数据(增大batch size)。
Q3:如何估算所需算力?
- 参考公式:总计算量(FLOPs)= 模型参数量 × 每参数前向计算次数 × 2(反向传播),训练ResNet-50约需3.8×10¹⁸ FLOPs。
参考文献
- NVIDIA官方白皮书:《A100 Tensor Core GPU Architecture》
- MLPerf Training Benchmark (mlcommons.org)
- 《Deep Learning》by Ian Goodfellow et al., MIT Press
- PyTorch官方文档:Distributed Data Parallel
通过科学配置与优化,GPU服务器可释放深度学习的全部潜力,无论是学术研究还是工业落地,合理利用计算资源已成为AI项目的成败关键。
相关文章

腾讯云gpu服务器,腾讯云GPU服务器(腾讯云gpu服务器,腾讯云gpu服务器区别)
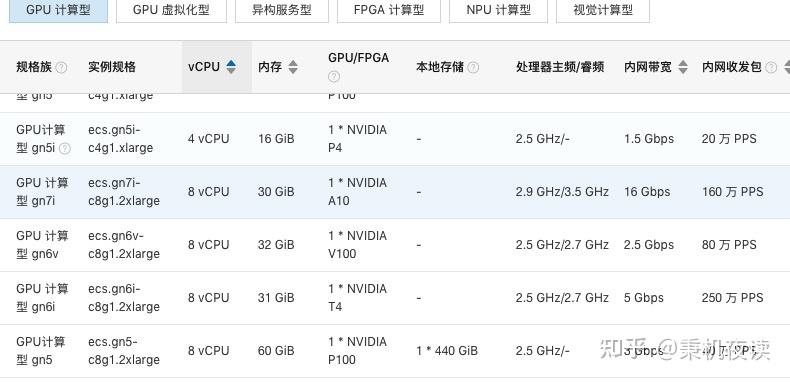
腾讯云gpu服务器(阿里云 GPU服务器)(腾讯云gpu服务器价格)

gpu服务器租用,阿里云gpu服务器租用2022年更新(阿里云gpu服务器租用价格表)
gpu服务器怎么用,GPU服务器搭建2022年更新(gpu服务器怎么使用)
常用深度学习的软件_深度学习模型预测

Contabo:GPU服务器(Nvidia Tesla T4 16 GB)(conda gpu)(gpu服务器使用教程)
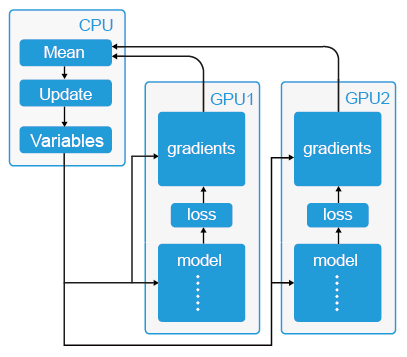
大数据计算MaxCompute的机器学习深度学习上gpu服务器资源怎么使用和配置?
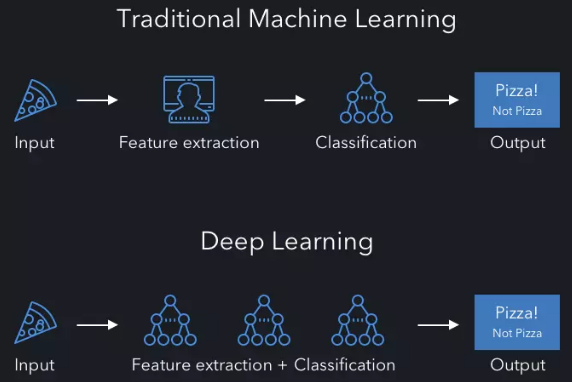
ai机器学习深度学习_深度学习模型预测








