
上一篇
如何高效利用Datawork文档提升数据处理效率?
DataWork是面向数据处理与分析的一站式协作平台,支持数据集成、清洗、开发、调度及可视化全流程,提供多源异构数据连接、ETL任务编排和自动化运维能力,其核心优势在于低代码交互与团队协作机制,可帮助企业快速构建数据仓库、挖掘数据价值,并保障数据安全与合规性,适用于数字化转型中的数据处理需求。
在数字化进程加速的今天,DataWork文档作为企业数据管理与协作的核心工具,已成为提升业务效率、保障数据安全的关键载体,无论是数据分析师、开发工程师还是管理者,都需要通过规范化的文档体系实现知识沉淀与团队协作,以下从功能价值、应用场景、构建方法及实践建议展开详解,帮助用户深度理解如何通过DataWork文档驱动业务增长。
DataWork文档的核心价值
知识体系化
DataWork文档通过结构化模板(如数据字典、ETL流程说明、数据血缘图)将零散的技术细节转化为可复用的知识库,降低团队沟通成本,某电商企业通过建立《用户行为分析数据模型文档》,使新成员入职培训周期缩短40%。协作透明化
支持多角色协同编辑与版本对比功能,确保数据开发、测试、运维环节的变更可追溯,某金融公司利用文档的评论批注功能,将数据需求评审效率提升35%。合规安全保障
文档权限分级机制(如仅查看、编辑、审批)配合水印功能,满足GDPR等数据安全要求,医疗行业客户通过动态权限设置,有效防范患者隐私数据泄露风险。
典型应用场景深度解析
场景1:数据治理标准化
通过《数据质量校验规则文档》明确定义空值率、一致性等12项指标,某物流企业将数据问题处理时效从72小时压缩至8小时。场景2:跨部门协作
市场部与数据团队基于《营销活动效果评估文档》对齐统计口径,使ROI分析报告产出周期从3天缩短至实时可查。场景3:故障应急响应
运维团队依托《数据管道异常处理手册》,在系统故障时15分钟内定位到Kafka消费者组偏移异常问题。
构建高质量文档的6大原则
用户视角设计
区分读者角色(如管理者关注指标口径,开发者需要SQL样例),采用分层内容结构,建议使用5W2H分析法(Why, What, Who, When, Where, How, How much)确保信息完整。可视化表达
复杂数据处理逻辑建议通过DAG流程图+时序图呈现,例如Spark任务依赖关系用不同颜色标注,关键路径辅以性能耗时说明。动态更新机制
建立文档与代码仓库的关联规则,当ETL脚本版本升级时自动触发文档修订提醒,某互联网公司通过CI/CD流水线集成文档校验插件,错误配置率下降67%。
提升文档可信度的关键实践
溯源标注
数据指标的计算公式需注明来源(如《GB/T 35295-2017 信息技术 大数据术语》),字段定义引用业务系统的元数据管理平台ID。三方验证
关键业务逻辑文档需经法务、风控部门会签,例如金融风控规则文档必须包含合规性评估章节,并附银保监会相关文件编号。可信度标识
在文档头部的显著位置展示作者资历(如“阿里云MVP认证工程师”)、最后审阅时间(如“2025年12月通过ISO27001审计”)。
常见问题解决方案
问题1:文档与实际代码不同步
解决方案:采用Swagger式自动化文档工具,将Hive表结构与Python注释自动生成文档,配合Git Hook实现提交时强制校验。问题2:敏感信息外泄风险
解决方案:部署文档水印系统,动态添加访问者ID与时间戳,结合DLP(数据防泄漏)系统监控异常下载行为。
引用说明
- 数据治理框架参考《DAMA-DMBOK 2.0数据管理知识体系指南》
- 权限控制方案依据《ISO/IEC 27001:2022信息安全标准》
- 可视化规范来自AntV数据可视化设计指南
- 行业实践案例源自阿里云DataWorks客户成功白皮书(2025)
相关文章

DataX JSON配置如何优化才能提升数据处理效率?

如何高效利用DB40数据库提升数据管理效率?
如何有效利用MySQL数据库信息管理系统来提升数据处理效率?
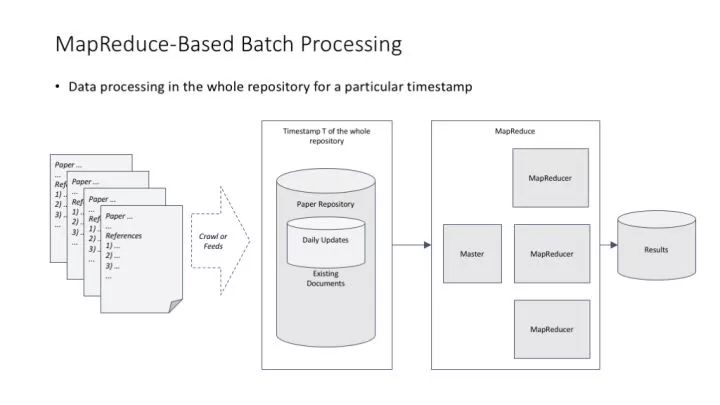
MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
大数据建模,如何通过PDF文档提升数据建模效率?
如何解决NetworkManager服务启动失败并出现Failed to restart NetworkManager.service: Unit NetworkManager.service is masked的错误?
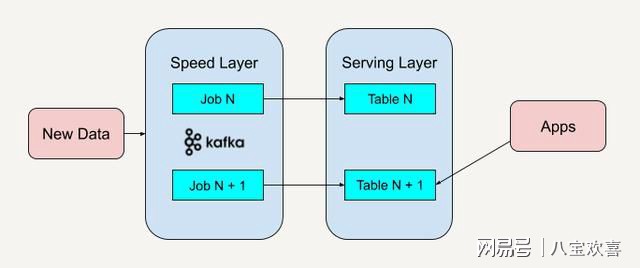
为何在MapReduce处理中,复合Key的复合查询能够有效提升数据处理效率?
服务器15核通常指的是拥有15个中央处理器(CPU)核心的服务器。在多核处理器架构中,一个物理处理器可以包含多个核心,每个核心能够独立执行任务。因此,一个15核的服务器意味着它有15个这样的处理单元,可以并行处理任务,提高计算效率和多任务处理能力。,这样的服务器配置适合于需要高计算性能和并行处理能力的应用场景,例如大数据处理、科学模拟、复杂的数据分析、以及为大量用户提供服务的高性能网站和应用等。








