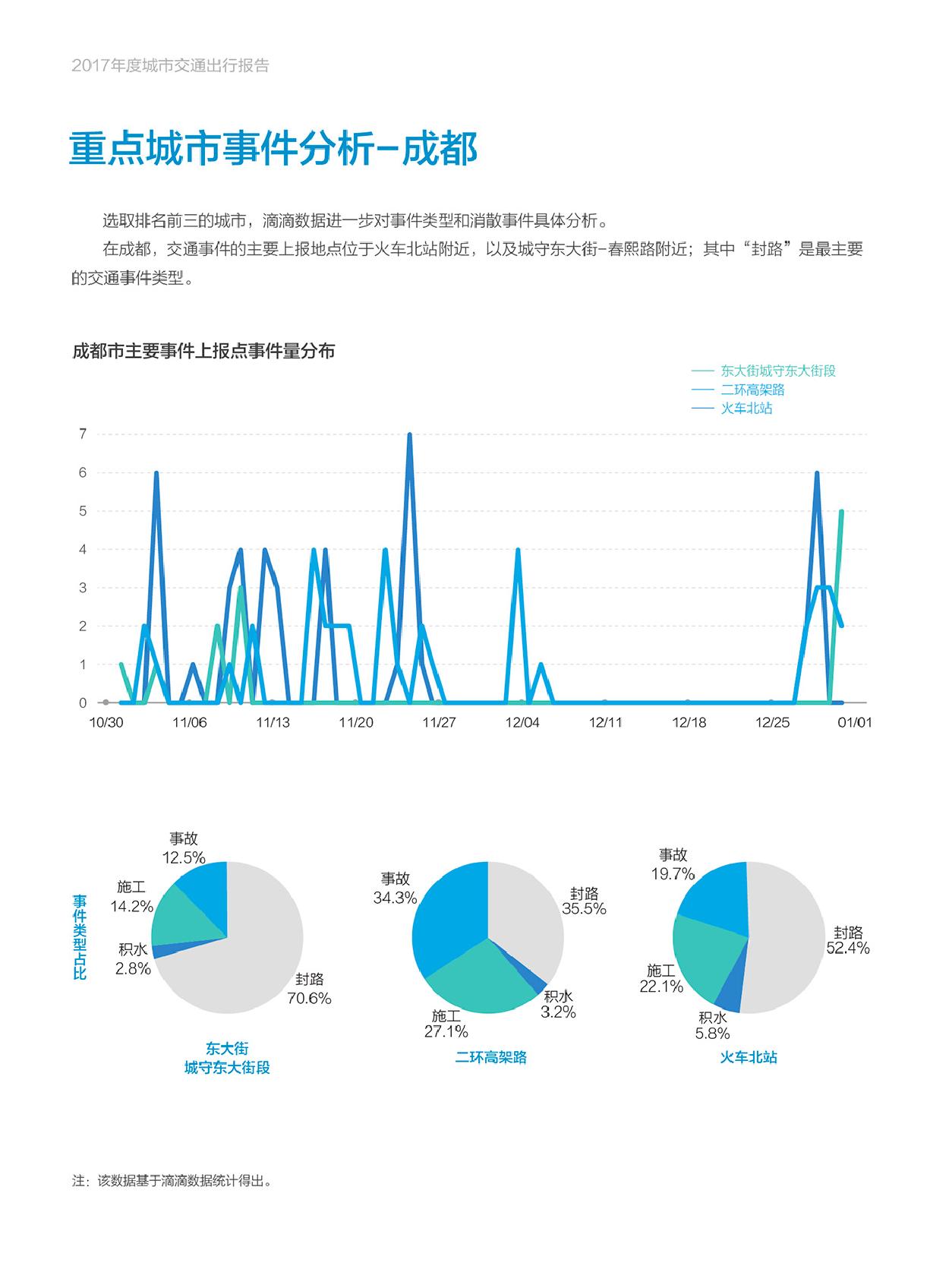
上一篇
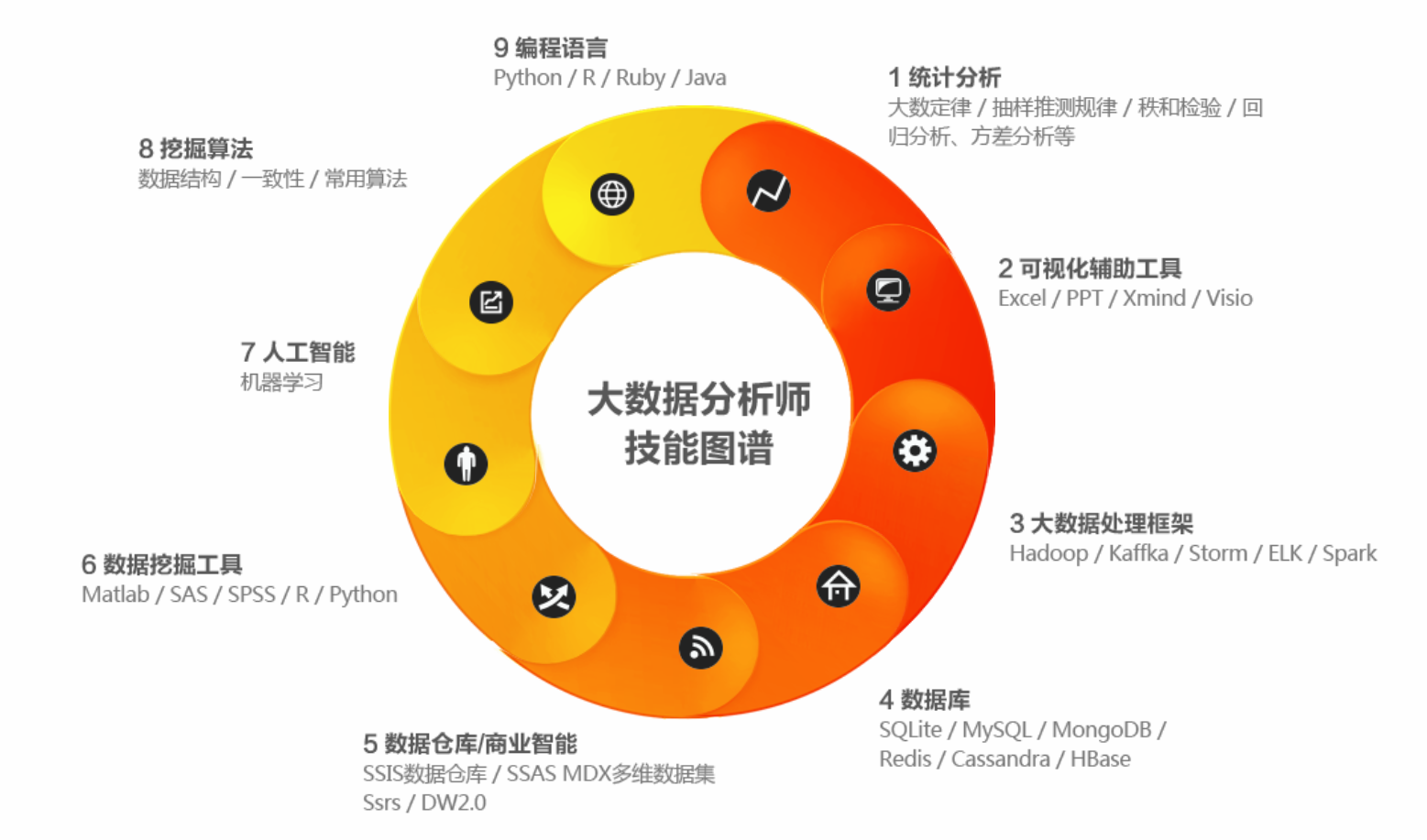
分钟上手大数据分析
选工具Python/R,连数据源,用Pandas/Spark处理,Mat
什么是大数据分析?
大数据分析是指通过技术手段从海量、高速、多样化的数据中提取有价值的信息,帮助企业或个人做出决策,其核心特点包括:
- 数据量大:处理TB、PB级数据(如日志、用户行为、传感器数据)。
- 处理速度快:实时或近实时分析(如流数据处理)。
- 数据类型多样:结构化(数据库)、半结构化(JSON/XML)、非结构化(文本、图像)。
核心应用场景
| 场景 | 示例 |
|---|---|
| 用户行为分析 | 电商网站通过用户点击、购买记录优化推荐算法 |
| 风险预测 | 金融机构利用历史交易数据识别欺诈模式 |
| 运营优化 | 物流企业通过路线数据缩短配送时间 |
| 市场趋势洞察 | 社交媒体数据挖掘热点话题,辅助产品定位 |
快速上手的必备工具
数据采集
- 工具:Apache NiFi、Logstash、Python Scrapy
- 功能:从数据库、API、网页等来源抓取数据。
- 示例:用Logstash采集服务器日志并推送到Hadoop集群。
数据存储
| 工具类型 | 代表工具 | 适用场景 |
|---|---|---|
| 分布式文件系统 | HDFS | 存储海量非结构化数据(如日志) |
| 列式数据库 | HBase/Cassandra | 高并发读写(如物联网设备数据) |
| 数据仓库 | Amazon Redshift | BI分析(如销售报表) |
数据处理与分析
- SQL类工具:
- Pandas/SQLite:适合小规模数据清洗(Python生态)。
- Hive/Spark SQL:处理Hadoop/Spark上的大规模数据。
- 无代码工具:
- Power BI/Tableau:拖拽式操作生成可视化报表。
- Google Data Studio:免费且支持多数据源整合。
- 编程类工具:
- Python(Pandas/NumPy):数据清洗、统计分析。
- R语言:统计学模型与可视化。
可视化与报告
- 基础工具:Matplotlib、Seaborn(Python)、ECharts(前端)。
- 高级工具:Tableau、Power BI支持交互式仪表盘。
5步实现“分钟级”数据分析
步骤1:明确问题
- 示例:某电商需分析“用户流失原因”。
- 关键指标:活跃度、留存率、最后登录时间。
步骤2:获取数据
- 数据源:用户行为日志(如浏览、下单记录)。
- 工具:直接导出MySQL数据库表,或用Python脚本抓取。
步骤3:数据清洗
- 操作:
- 删除重复值(如重复订单)。
- 填充缺失值(用均值/中位数替代)。
- 格式转换(如日期统一为YYYY-MM-DD)。
- 代码示例(Python):
import pandas as pd df = pd.read_csv("user_data.csv") df.drop_duplicates(subset="order_id", inplace=True) df["last_login"] = pd.to_datetime(df["last_login"])
步骤4:分析与建模
- 基础分析:
- 统计用户活跃天数:
df.groupby("user_id")["login_date"].count()。 - 计算7日留存率:
活跃用户中7天后仍登录的比例。
- 统计用户活跃天数:
- 进阶模型:
- 用逻辑回归预测用户流失概率。
- 聚类分析(K-Means)划分用户群体。
步骤5:输出结果
- 可视化:用Matplotlib绘制留存曲线图。
- 报告:将上文归纳写入Jupyter Notebook,或导出为PDF。
实战案例:电商用户流失预警
背景
某电商平台发现近30%用户注册后未复购,需快速定位原因。

执行流程
- 数据采集:导出近1年用户订单数据(含注册时间、订单金额、登录次数)。
- 清洗数据:过滤无效订单(如退款),填补缺失的“城市”字段。
- 特征工程:
- 计算用户生命周期(注册至最后一次登录的天数)。
- 生成RFM模型指标(最近消费时间、消费频率、金额)。
- 建模:
- 用随机森林分类器预测“高流失风险”用户。
- 输出概率>0.8的用户列表。
- 干预:对高风险用户发送优惠券,观察复购率变化。
避坑指南
- 数据质量问题:
脏数据(如空值、错误格式)会导致模型偏差,需优先清洗。
- 工具选择误区:
小规模数据用Excel/Pandas,大规模数据选Spark/Hadoop。
- 过度依赖工具:
避免盲目追求复杂模型,先从描述性统计(如均值、分布)入手。
FAQs
Q1:完全没有编程基础,如何快速入门大数据分析?
A:可以从以下步骤开始:
- 学习基础SQL(如SELECT、GROUP BY)用于数据查询。
- 使用无代码工具(如Power BI)连接Excel或数据库,生成简单报表。
- 通过在线课程(如Coursera的“数据科学入门”)掌握Python基础语法。
Q2:如何处理实时数据流(如监控日志)?
A:可选用以下工具链:
- 数据采集:Flume/Logstash实时收集日志。
- 流处理:Apache Flink或Spark Streaming进行实时计算(如统计每分钟错误率)。
- 可视化:将结果推送至Graf