上一篇
服务器CPU占用率100%?这些原因你排查了吗?
服务器CPU满载多由程序错误、资源竞争或反面攻击引起,可能导致服务响应延迟或宕机,需检查高负载进程、排查死循环代码、分析系统日志定位异常进程,并通过扩容资源、优化程序逻辑、限制异常请求或升级硬件配置来缓解负载压力,保障业务稳定运行。
服务器CPU占用率100%?深度解析原因与解决方案
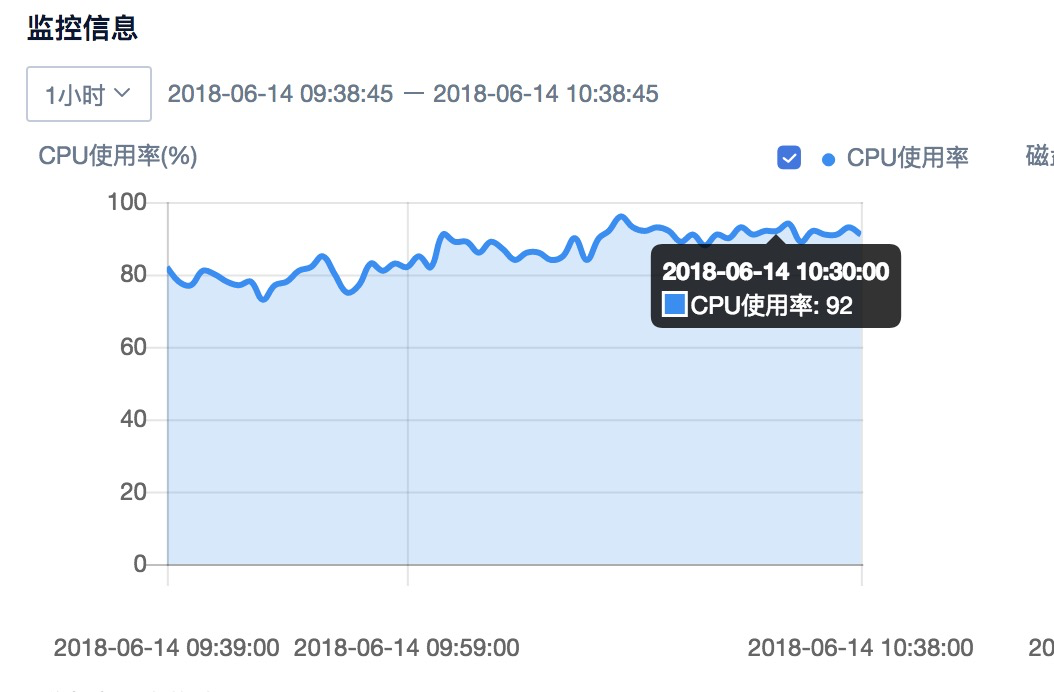
当服务器型计算机的CPU占用率持续飙升至100%,意味着系统已超负荷运行,可能导致服务崩溃、响应延迟甚至数据丢失,本文从技术角度剖析CPU占满的六大常见原因,并提供对应的解决方案与预防措施,帮助运维人员快速定位问题,保障业务稳定。
代码逻辑缺陷或死循环
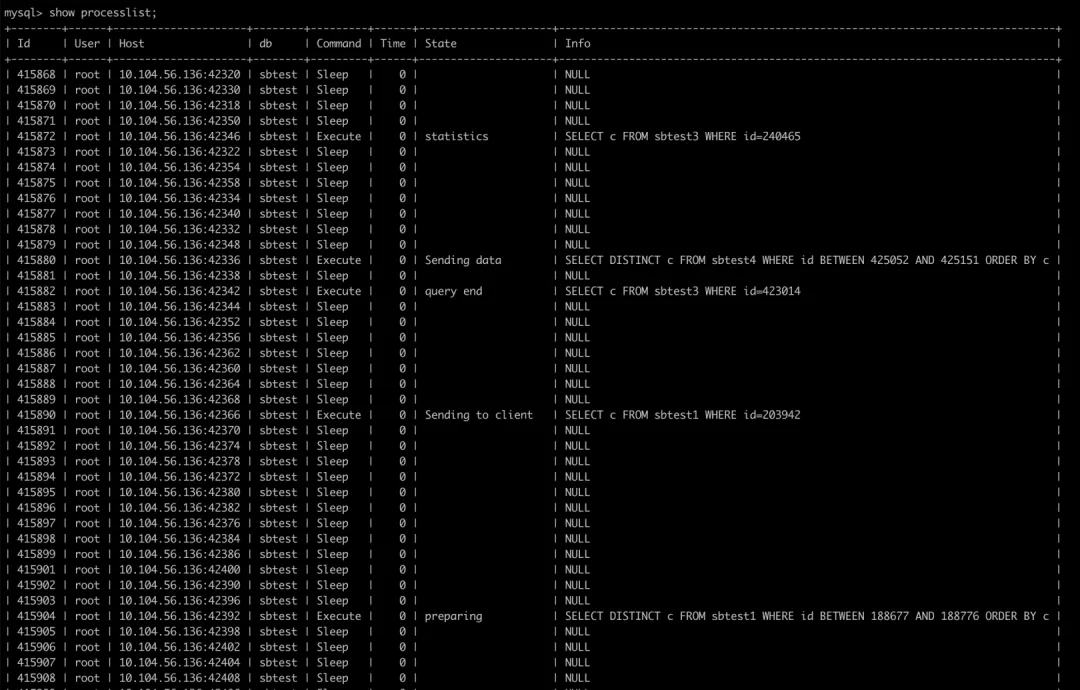
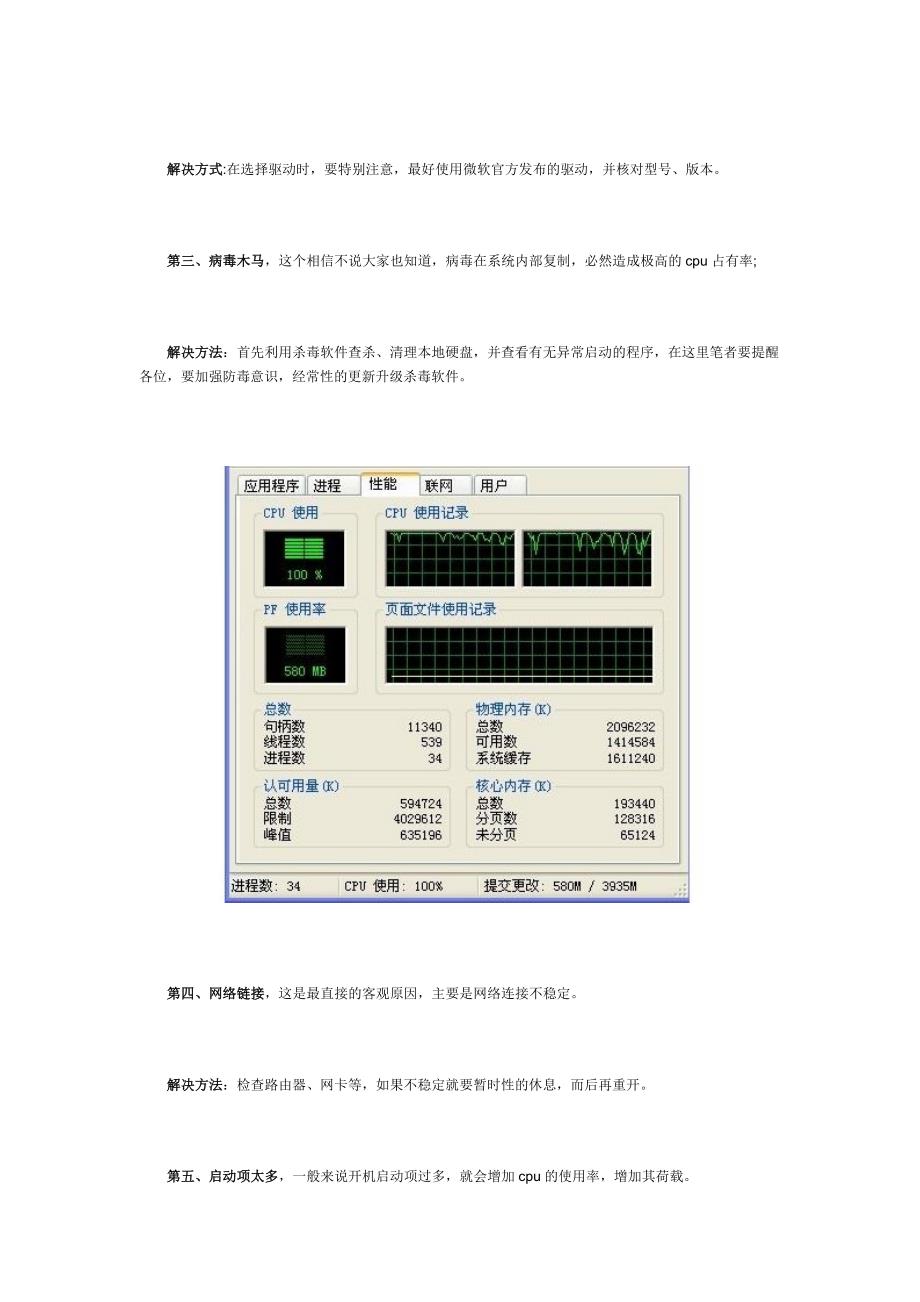
表现:某一进程持续占用高CPU资源,常见于Web应用、数据库查询或脚本任务。
定位方法:

- 使用命令
top(Linux)或任务管理器(Windows)查看占用CPU最高的进程。 - 通过
strace -p [PID]追踪进程的系统调用,分析其行为。
解决方案:
- 重启相关服务释放资源,临时缓解问题。
- 检查代码是否存在死循环、未关闭的连接或递归调用错误。
- 优化数据库查询,避免全表扫描或复杂联合查询。
反面攻击或异常流量
表现:CPU突然飙升,伴随网络带宽占满,常见于DDoS攻击、暴力破解或爬虫滥用。
定位方法:
- 使用
netstat -an | grep :80 | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -n统计异常IP连接。 - 分析日志文件(如Nginx的
access.log),筛选高频请求IP。
解决方案:
- 启用防火墙(如iptables、Cloudflare)屏蔽异常IP。
- 配置限流策略(如Nginx的
limit_req模块)。 - 部署Web应用防火墙(WAF)拦截反面流量。
资源不足或配置错误
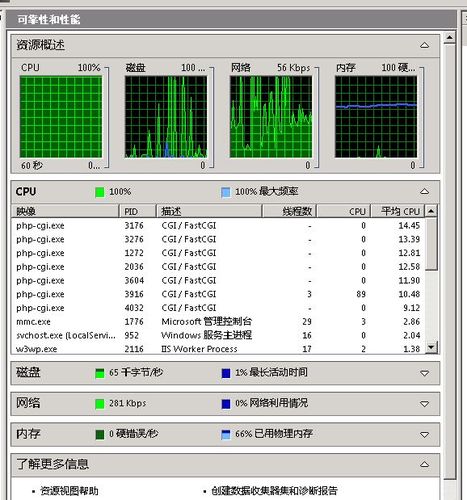
表现:多任务并发时CPU满载,系统负载(Load Average)持续高于CPU核心数。
定位方法:
- 通过
uptime查看负载平均值,若长期超过CPU核心数2倍以上需警惕。 - 检查定时任务(Cron)或后台服务是否配置不合理。
解决方案: - 升级服务器配置,增加CPU核心数或切换高性能实例。
- 优化任务调度策略,避免高峰时段集中执行资源密集型任务。
- 调整应用线程池大小,避免过度创建线程。
僵尸进程积累
表现:top命令中显示大量“Zombie”进程,占用系统资源。
原因:父进程未正确回收子进程资源,导致内核进程表被占满。
解决方案:
- 终止僵尸进程的父进程:
kill -9 [PPID]。 - 修改程序逻辑,确保子进程结束后父进程调用
wait()回收资源。
硬件故障或驱动异常
表现:CPU占用率高且伴随温度报警、系统卡顿。
定位方法:
- 使用
dmesg查看内核日志,排查硬件错误提示。 - 运行
stress测试工具,观察CPU稳定性。
解决方案: - 清理服务器散热风扇,改善通风环境。
- 更新主板BIOS和硬件驱动至最新版本。
- 联系服务器厂商检测CPU或主板是否损坏。
预防CPU占满的长期策略
- 监控告警:部署Prometheus+Grafana或Zabbix,实时监控CPU使用率并设置阈值告警。
- 压测优化:定期对服务进行压力测试,定位性能瓶颈(如使用JMeter或LoadRunner)。
- 容器化部署:通过Kubernetes实现自动扩缩容,动态分配计算资源。
- 日志分析:集中管理日志(ELK stack),快速定位异常事件。
引用说明
- Linux系统命令参考:
man手册、Linux Documentation Project - 服务器安全实践:OWASP指南
- 性能监控工具:Grafana官方文档