上一篇
如何高效掌握Dataphin智能数据构建与管理技巧?
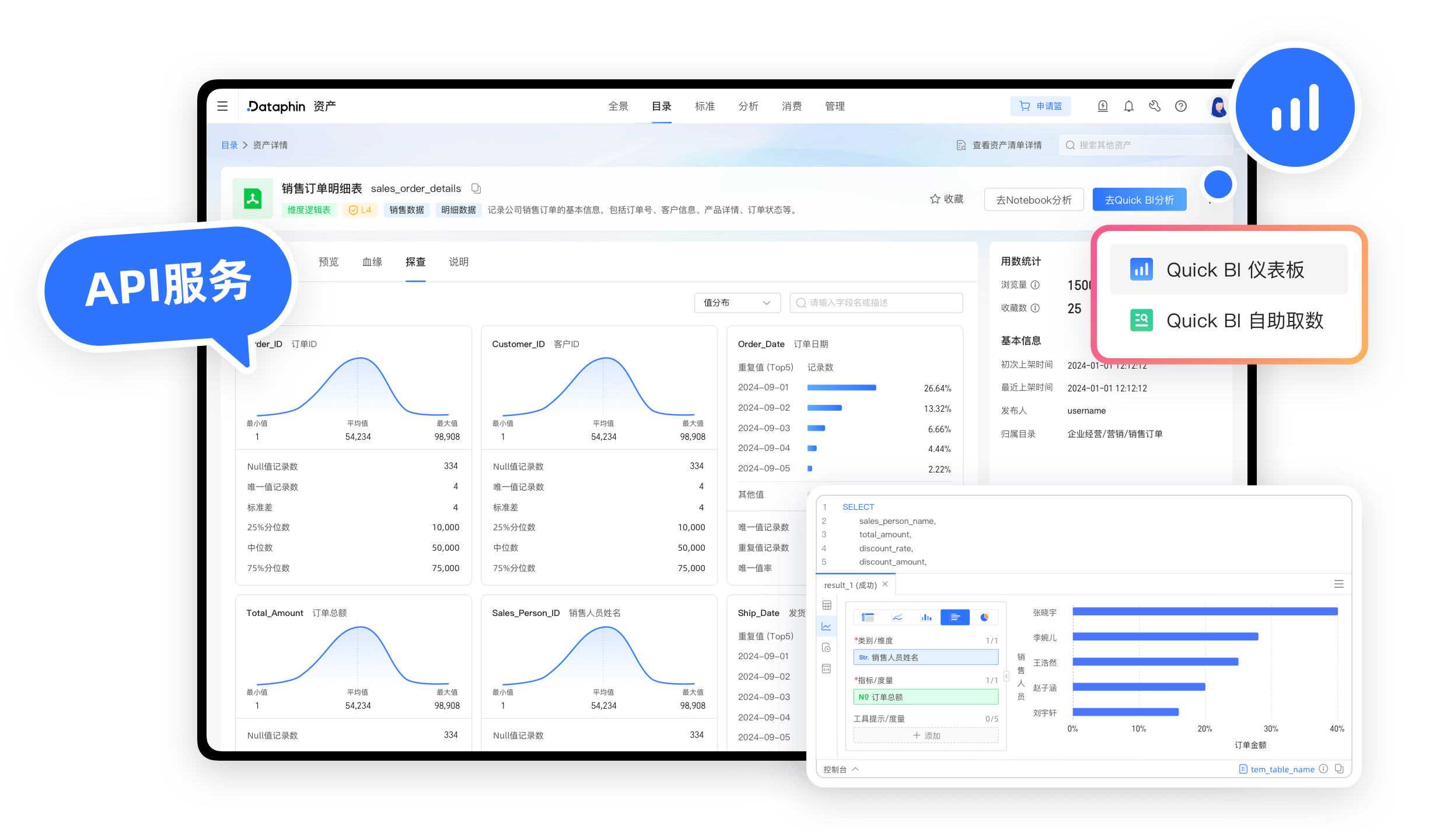
Dataphin是阿里云推出的智能数据构建与管理平台,提供数据集成、开发、质量监控及资产化管理等功能,用户通过配置数据源、设计数据模型、调度任务实现自动化数据处理流程,支持统一元数据管理、标准化建模和智能运维,帮助企业高效完成数据资产治理与开发,确保数据质量与一致性,助力业务分析与决策。
Dataphin是阿里巴巴集团推出的智能数据构建与管理平台,旨在帮助企业高效完成数据资产的集成、开发、治理与应用,它通过自动化、智能化的工具链,降低数据开发门槛,提升数据资产价值,以下为详细使用指南,帮助用户快速掌握核心功能与操作流程。
Dataphin的核心功能
智能数据集成
支持多源异构数据的统一接入,涵盖数据库、日志、API、文件等类型,通过可视化配置,自动生成数据同步任务,减少手动编码工作量。- 操作步骤:进入【数据集成】模块 → 选择数据源类型(如MySQL、Oracle) → 配置连接信息 → 定义同步任务(全量/增量) → 启动任务并监控状态。
自动化数据建模
基于OneData方法论,提供维度建模、指标体系设计等功能,通过智能推荐字段关联关系,辅助构建标准化的数据仓库模型。- 操作步骤:进入【数据建模】模块 → 创建主题域(如交易、用户) → 定义维表/事实表 → 配置字段与指标 → 发布模型并生成物理表。
代码化数据开发
支持SQL、Python等多种开发语言,提供在线IDE环境,内置语法检查与执行日志,支持任务调度依赖配置,实现复杂ETL流程的自动化编排。- 操作步骤:进入【数据开发】模块 → 新建脚本任务 → 编写代码 → 配置调度周期与依赖关系 → 提交任务至运维中心。
数据资产治理
自动构建数据血缘图谱,追踪数据来源与流向,支持数据质量规则配置(如空值检测、唯一性校验),并生成治理报告。- 操作步骤:进入【资产管理】模块 → 查看数据血缘 → 定义质量规则 → 运行校验任务 → 修复问题数据。
安全与权限管理
支持基于角色的访问控制(RBAC),精细化分配数据表、字段级权限,提供数据脱敏、审计日志等功能,满足企业级安全合规需求。
使用流程详解
第一步:数据接入与同步
- 创建数据源
在【数据集成】中选择“新增数据源”,填写数据库地址、账号、密码等信息,测试连接成功后保存。

- 配置同步任务
选择源表与目标表,设置同步频率(如每日凌晨1点),支持断点续传与脏数据隔离。
第二步:构建数据模型
- 定义主题域
根据业务场景划分主题(电商交易”),关联对应的业务过程与实体。
- 设计模型与指标
使用维度建模工具拖拽字段,系统自动生成ER图,设置原子指标(如“订单金额”)与派生指标(如“月均GMV”)。
第三步:开发与调度
- 编写ETL脚本
在数据开发界面调用内置函数(如日期转换、聚合计算),调试通过后保存。
- 配置任务依赖
设置任务触发条件(上游表更新后执行”),支持跨项目依赖管理。
第四步:资产管理与运维
- 监控任务运行
在运维中心查看任务执行状态、耗时及资源消耗,支持失败告警(邮件/钉钉通知)。
- 优化数据质量
根据校验报告定位问题,例如修复缺失值或调整数据清洗逻辑。
最佳实践案例
- 场景:电商用户行为分析
- 数据接入:同步用户日志(埋点数据)、订单库、会员信息表至Dataphin。
- 建模:构建“用户行为”主题域,定义“页面访问”、“加购转化”等核心指标。
- 开发:编写SQL计算用户留存率,调度任务每日自动更新。
- 应用:将结果表推送至Quick BI生成可视化报表,指导运营策略。
常见问题解答
- 如何保障数据安全?
启用字段级权限控制,敏感数据(如手机号)配置动态脱敏规则。
- 是否支持跨云环境?
支持混合云部署,可连接阿里云、AWS、私有IDC等多环境数据源。
- 如何处理大数据量下的性能问题?
启用分布式计算引擎(如MaxCompute),优化分区策略,减少全表扫描。
Dataphin通过一体化数据开发与治理能力,帮助企业从原始数据到资产价值的快速转化,其核心优势在于:
- 降低技术门槛:可视化操作替代复杂编码,适合业务与技术人员协作。
- 提升效率:自动化任务调度减少人工干预,释放70%以上的开发时间。
- 保障合规性:内置数据安全与质量管控机制,满足GDPR等法规要求。
通过上述步骤与案例,用户可快速上手并实现数据资产的规范管理,建议结合官方文档与社区资源持续优化实践(引用:阿里云Dataphin产品文档)。
引用说明
本文部分操作步骤参考自阿里云官方文档,具体功能以实际版本为准。