上一篇
数据库多表查询如何实现

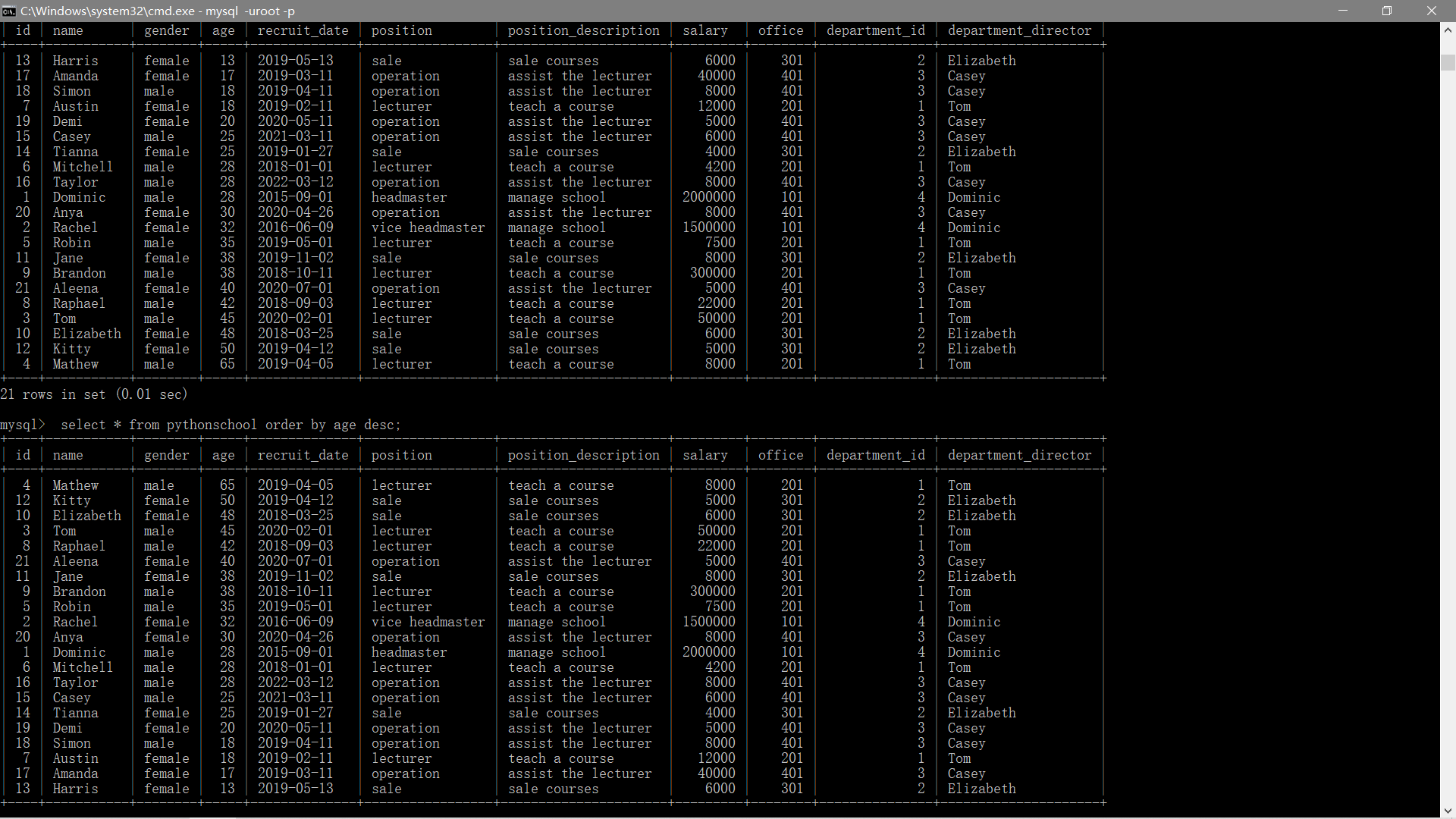
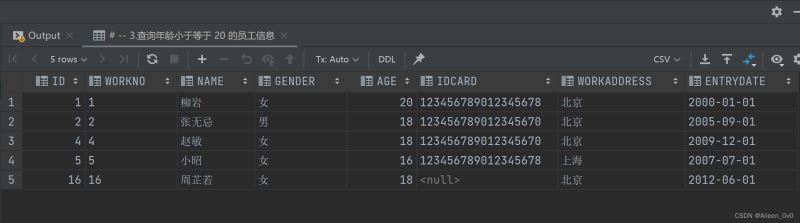
多表查询使用JOIN语句关联多个表,通过主键/外键匹配数据,常用方式包括INNER JOIN(交集)、LEFT JOIN(左表全保留)、RIGHT JOIN(右表全保留)和FULL JOIN(并集),SELECT时需明确字段来源(如table.column),避免歧义可用别名。
<div class="article-content">
<section>
<p>数据库多表查询是处理关系型数据库的核心技能,它通过关联多个表中的数据实现复杂数据分析,本文将详细解析多表查询的原理、方法和优化技巧,帮助您高效提取跨表数据。</p>
</section>
<section>
<h2>一、多表查询的本质与必要性</h2>
<p>关系型数据库通过<strong>主键-外键关联</strong>建立表间联系,多表查询的核心价值在于:</p>
<ul>
<li>消除数据冗余:避免单表存储重复信息</li>
<li>实现数据完整性:外键约束保证关联数据一致性</li>
<li>支持复杂分析:跨表组合计算业务指标(如订单关联客户和产品)</li>
</ul>
<p>示例场景:电商系统中需同时获取<em>订单信息+客户姓名+商品名称</em></p>
</section>
<section>
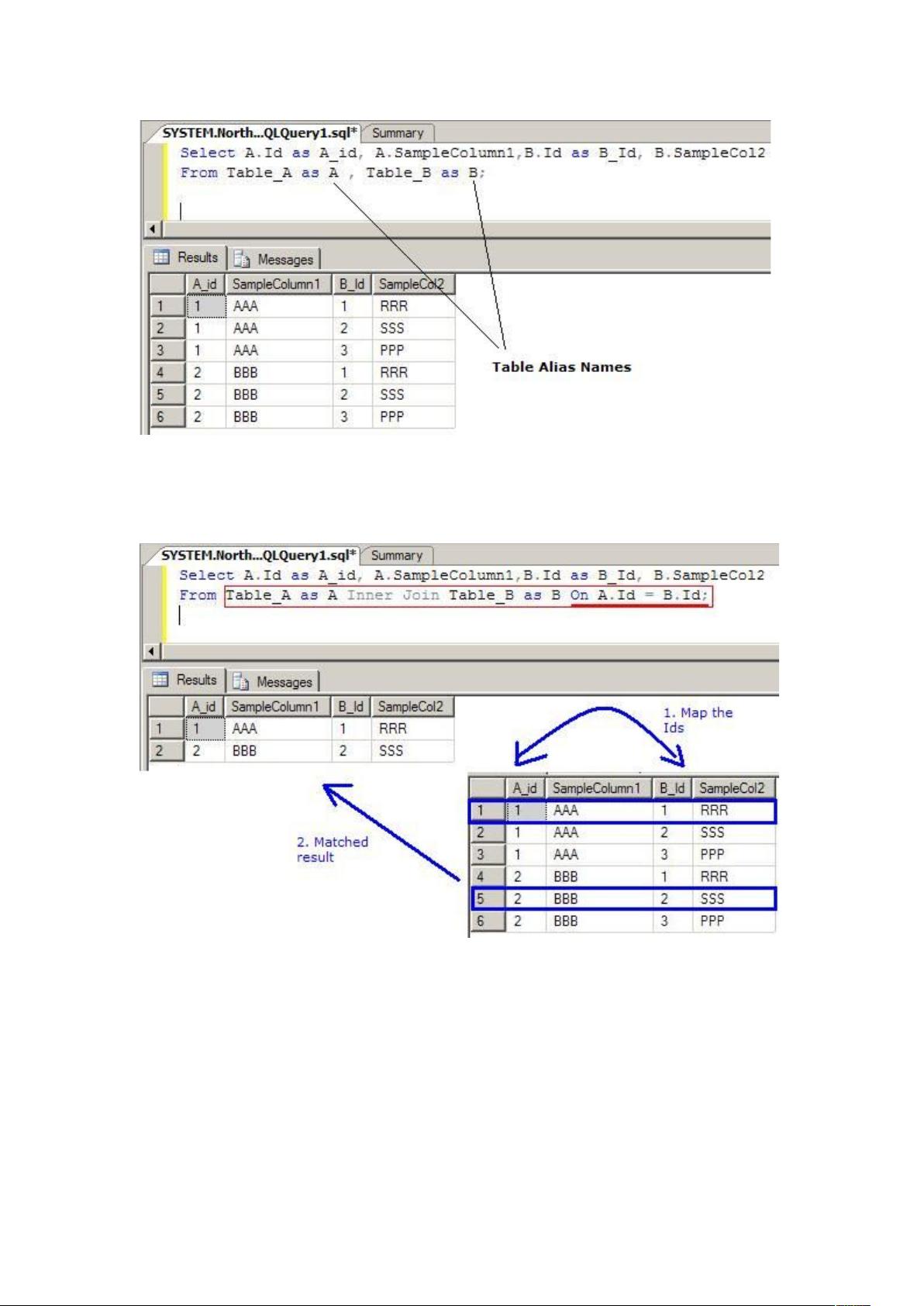
<h2>二、五大连接类型详解(附SQL示例)</h2>
<h3>1. INNER JOIN(内连接)</h3>
<p>取两表<strong>交集数据</strong>,仅返回匹配成功的记录</p>
<pre>SELECT orders.id, customers.name
FROM orders
INNER JOIN customers
ON orders.customer_id = customers.id;</pre>
<p class="tip">适用场景:需排除无关联数据的记录</p>
<h3>2. LEFT JOIN(左连接)</h3>
<p>以左表为基准,返回<strong>全部左表记录</strong>+匹配的右表记录</p>
<pre>SELECT employees.name, departments.dept_name
FROM employees
LEFT JOIN departments
ON employees.dept_id = departments.id;</pre>
<p class="tip">适用场景:统计员工时需包含未分配部门的员工</p>
<h3>3. RIGHT JOIN(右连接)</h3>
<p>以右表为基准,返回<strong>全部右表记录</strong>+匹配的左表记录</p>
<pre>SELECT products.name, suppliers.company
FROM suppliers
RIGHT JOIN products
ON suppliers.id = products.supplier_id;</pre>
<h3>4. FULL OUTER JOIN(全外连接)</h3>
<p>返回两表<strong>所有记录</strong>(MySQL需用UNION实现)</p>
<pre>SELECT *
FROM tableA
LEFT JOIN tableB ON tableA.id = tableB.id
UNION
SELECT *
FROM tableA
RIGHT JOIN tableB ON tableA.id = tableB.id;</pre>
<h3>5. CROSS JOIN(交叉连接)</h3>
<p>生成两表的<strong>笛卡尔积</strong>(慎用)</p>
<pre>SELECT * FROM colors CROSS JOIN sizes;</pre>
</section>
<section>
<h2>三、高级多表查询技巧</h2>
<h3>1. 多表链式连接</h3>
<pre>SELECT
orders.order_date,
customers.name,
products.product_name
FROM orders
JOIN customers ON orders.customer_id = customers.id
JOIN order_items ON orders.id = order_items.order_id
JOIN products ON order_items.product_id = products.id;</pre>
<h3>2. 自连接查询</h3>
<p>同一表内建立关联(如组织架构查询)</p>
<pre>SELECT
e1.name AS employee,
e2.name AS manager
FROM employees e1
LEFT JOIN employees e2
ON e1.manager_id = e2.id;</pre>
<h3>3. 联合查询(UNION)</h3>
<p>垂直合并结果集(需相同列结构)</p>
<pre>SELECT name, 'customer' AS type FROM customers
UNION ALL
SELECT name, 'supplier' FROM suppliers;</pre>
</section>
<section>
<h2>四、性能优化关键策略</h2>
<ul>
<li><strong>索引优化</strong>:为所有JOIN条件字段创建索引</li>
<li><strong>限制字段</strong>:避免SELECT *,明确指定所需字段</li>
<li><strong>子查询优化</strong>:将EXISTS替代IN处理大量数据</li>
<li><strong>分页处理</strong>:大数据集使用LIMIT分页加载</li>
<li><strong>执行计划分析</strong>:用EXPLAIN命令检查查询效率</li>
</ul>
<pre>EXPLAIN SELECT * FROM orders JOIN customers ON ...</pre>
</section>
<section>
<h2>五、常见错误与避坑指南</h2>
<table>
<thead>
<tr><th>错误类型</th><th>后果</th><th>解决方案</th></tr>
</thead>
<tbody>
<tr>
<td>笛卡尔积爆炸</td>
<td>返回百万级无效数据</td>
<td>检查JOIN条件是否遗漏</td>
</tr>
<tr>
<td>字段歧义</td>
<td>SQL报错"column ambiguous"</td>
<td>使用table.column明确来源</td>
</tr>
<tr>
<td>NULL值处理</td>
<td>统计结果偏差</td>
<td>用COALESCE函数设置默认值</td>
</tr>
<tr>
<td>性能陷阱</td>
<td>全表扫描导致慢查询</td>
<td>建立复合索引覆盖查询</td>
</tr>
</tbody>
</table>
</section>
<section>
<h2>六、实战应用场景示例</h2>
<p><strong>场景:统计每个部门的员工数量(含无员工部门)</strong></p>
<pre>SELECT
d.dept_name,
COUNT(e.id) AS employee_count
FROM departments d
LEFT JOIN employees e ON d.id = e.dept_id
GROUP BY d.dept_name;</pre>
<p><strong>场景:查找从未下单的客户</strong></p>
<pre>SELECT name
FROM customers
LEFT JOIN orders ON customers.id = orders.customer_id
WHERE orders.id IS NULL;</pre>
</section>
<section class="summary">
<h2>最佳实践总结</h2>
<ol>
<li>明确数据关系:绘制ER图理清表关联逻辑</li>
<li>选择最小数据集:仅查询必要字段和记录</li>
<li>优先INNER JOIN:减少数据处理量</li>
<li>重要操作前备份:UPDATE/DELETE搭配事务使用</li>
<li>版本控制:存储复杂查询的SQL脚本</li>
</ol>
<blockquote>
<p>“优秀的SQL不是复杂的代码堆砌,而是用最简洁的方式精确获取所需数据” —— 数据库专家 C.J. Date</p>
</blockquote>
</section>
<div class="reference">
<h3>引用说明</h3>
<p>1. 《SQL性能优化》 - 人民邮电出版社, 2020<br>
2. MySQL 8.0官方文档 - JOIN语法详解<br>
3. 关系数据库设计范式理论 - Edgar F. Codd<br>
4. 阿里巴巴Java开发手册 - 数据库章节</p>
</div>
</div>
<style>
.article-content {
font-family: 'Segoe UI', Tahoma, sans-serif;
line-height: 1.8;
color: #333;
max-width: 900px;
margin: 0 auto;
padding: 20px;
}
section {
margin-bottom: 40px;
border-bottom: 1px solid #eee;
padding-bottom: 30px;
}
h2 {
color: #2c3e50;
border-left: 5px solid #3498db;
padding-left: 15px;
margin-top: 40px;
}
h3 {
color: #2980b9;
margin-top: 25px;
}
pre {
background: #f8f9fa;
border: 1px solid #eaeaea;
border-radius: 4px;
padding: 15px;
overflow: auto;
margin: 15px 0;
}
table {
width: 100%;
border-collapse: collapse;
margin: 20px 0;
}
th {
background: #3498db;
color: white;
}
td, th {
border: 1px solid #ddd;
padding: 12px;
text-align: left;
}
tr:nth-child(even) {
background-color: #f2f2f2;
}
blockquote {
border-left: 4px solid #3498db;
background: #f9f9f9;
padding: 15px 20px;
margin: 25px 0;
font-style: italic;
}
.tip {
background: #e1f5fe;
padding: 10px;
border-radius: 4px;
}
.reference {
font-size: 0.9em;
color: #7f8c8d;
margin-top: 40px;
}
.summary {
background: #e8f4f8;
padding: 20px;
border-radius: 8px;
}
</style>