上一篇
Java乱码原因及解决?
Java乱码问题通常因字符编码不匹配导致,常见场景包括文件读写、网络传输或数据库交互时编码与解码使用的字符集不一致(如UTF-8与GBK混用),解决方法需确保各环节统一使用UTF-8编码,并在IO操作时显式指定字符集。
在Java开发中,乱码问题是最常见的字符编码挑战之一,根本原因在于字节流与字符流转换时编码不一致,本文将深入解析乱码成因,并提供场景化解决方案(附代码示例),帮助开发者彻底规避问题。
乱码产生的核心原因
乱码本质是“编码-解码”不匹配的过程:
// 错误示例:用ISO-8859-1编码,却用GBK解码
byte[] bytes = "你好".getBytes("ISO-8859-1"); // 编码阶段
String str = new String(bytes, "GBK"); // 解码阶段 → 乱码
- 关键点:数据存储/传输时的编码格式 与 读取时的解码格式 必须一致
- 常见编码标准:UTF-8(推荐)、GBK、ISO-8859-1等
高频乱码场景及解决方案
场景1:文件读写乱码
原因:读写文件未指定编码,使用系统默认编码(如Windows中文环境默认GBK)
// 错误写法:依赖默认编码
FileReader reader = new FileReader("test.txt"); // 可能用GBK读取UTF-8文件
// 正确方案:显式声明编码
try (BufferedReader br = new BufferedReader(
new InputStreamReader(
new FileInputStream("test.txt"), StandardCharsets.UTF_8))) {
String line = br.readLine(); // 正确解码
}
场景2:HTTP网络传输乱码
HTTP请求乱码处理:
// 针对POST请求
request.setCharacterEncoding("UTF-8"); // 必须在getParameter前调用
// 针对GET请求(Tomcat为例)
// 修改server.xml:<Connector URIEncoding="UTF-8" .../>
HTTP响应乱码处理:

response.setContentType("text/html;charset=UTF-8");
response.setCharacterEncoding("UTF-8"); // 双重保险
场景3:数据库交互乱码
MySQL连接示例:
String url = "jdbc:mysql://localhost:3306/db?useUnicode=true&characterEncoding=UTF-8"; // 关键参数: // useUnicode=true 启用Unicode // characterEncoding=UTF-8 指定传输编码
场景4:字符串与字节转换
必须显式指定编码:
String str = "中文测试"; byte[] bytes = str.getBytes(StandardCharsets.UTF_8); // 编码 String recovered = new String(bytes, StandardCharsets.UTF_8); // 解码
系统级编码统一策略
-
JVM默认编码设置
启动参数添加:-Dfile.encoding=UTF-8
注:不推荐依赖此设置,但可作兜底方案 -
IDE工程设置
- Eclipse:Window → Preferences → General → Workspace → Text file encoding
- IntelliJ:File → Settings → Editor → File Encodings
统一设置为UTF-8
-
操作系统环境
Linux/Mac:export LANG=en_US.UTF-8
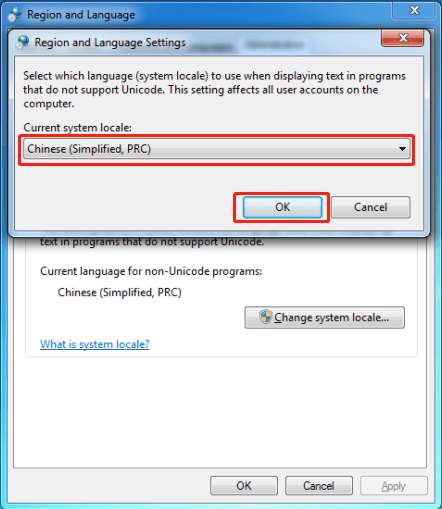
Windows:控制面板 → 区域设置 → 管理 → 非Unicode程序语言 → 勾选”Beta: UTF-8支持”
诊断乱码的调试技巧
-
打印字节值:快速定位编码错位
byte[] data = str.getBytes("ISO-8859-1"); System.out.println(Arrays.toString(data)); // 输出:[60, 63, 100, ...] → 对比正常编码值 -
编码猜测工具(推荐):
String[] encodings = {"UTF-8", "GBK", "ISO-8859-1"}; for (String enc : encodings) { try { System.out.println("Trying " + enc + ": " + new String(bytes, enc)); } catch (Exception ignored) {} }
终极预防法则
- 黄金原则:所有I/O操作显式声明编码
- 项目规范:
- 统一使用UTF-8编码
- 禁止出现
new String(byte[])无参构造 - 配置文件(.properties)用
native2ascii转义非ASCII字符
- 框架配置:
Spring Boot默认UTF-8,必要时在application.yml添加:spring: http: encoding: force: true charset: UTF-8
关键结论:乱码不是技术缺陷,而是编码规范缺失,建立全流程编码意识,即可100%规避问题。
引用说明
本文解决方案参考:
- Oracle官方文档《Java Platform Standard Edition 8: Character Encoding》
- RFC 3629: UTF-8, a transformation format of ISO 10646
- MySQL 8.0 Reference Manual: Connection Character Sets
- Spring Framework Documentation: Web MVC encoding configuration