上一篇
怎么把数据存入数据库
数据存入数据库需先建表结构,再通过SQL插入语句或编程接口(如JDBC/ODBC)执行添加操作,确保字段匹配与
准备工作
选择适合的数据库类型
根据业务需求选择合适的关系型或非关系型数据库:
| 类型 | 示例 | 适用场景 | 特点 |
|————|———————–|——————————|——————————-|
| 关系型 | MySQL, PostgreSQL, SQL Server | 结构化数据、事务性强的场景 | ACID特性、表结构固定 |
| NoSQL | MongoDB, Cassandra | 半结构化/非结构化数据、高并发读写 | 灵活模式、横向扩展能力强 |
| 时序型 | InfluxDB | 监控指标、IoT传感器日志 | 时间戳索引优化查询效率 |
提示:若需复杂查询和事务支持优先选关系型;若追求敏捷开发与海量存储则考虑NoSQL。
设计数据模型(以关系型为例)
- 实体识别:明确核心对象(如用户、订单、商品)。
- 字段定义:为每个实体分配属性并设置数据类型(INT/VARCHAR/DATE等)、约束条件(NOT NULL, UNIQUE)。
- ER图绘制:通过工具(如Lucidchart)可视化表间关联关系。
Users↔Orders一对多外键关联。 - 规范化处理:避免冗余存储,遵循范式理论(通常到第三范式即可)。
建立连接通道
不同语言对接数据库的方式各异,以下是主流方案对比:
| 技术栈 | 典型库/框架 | 代码片段示例 | 特点 |
|---|---|---|---|
| Python | PyMySQL / SQLAlchemy | conn = pymysql.connect(host='localhost', user='root') |
ORM映射减少SQL编写量 |
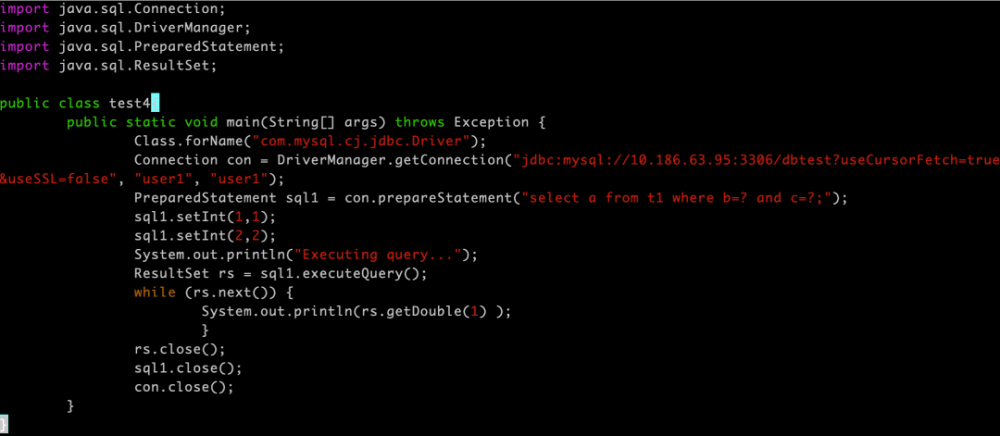
| Java | JDBC + Hibernate | EntityManager em = persist(new User()); |
JPA标准实现对象持久化 |
| Node.js | Sequelize / TypeORM | await sequelize.sync({ force: false }); |
Promise链式调用异步友好 |
| Go | GORM | db.Create(&User{Name: "Alice"}) |
强类型反射机制自动建表 |
️ 安全红线:永远不要在生产环境使用明文密码!应通过环境变量或密钥管理系统传递凭证,例如在Docker Compose中配置秘密变量:
services: db: environment: MYSQL_ROOT_PASSWORD_FILE: /run/secrets/db_password
执行写入操作
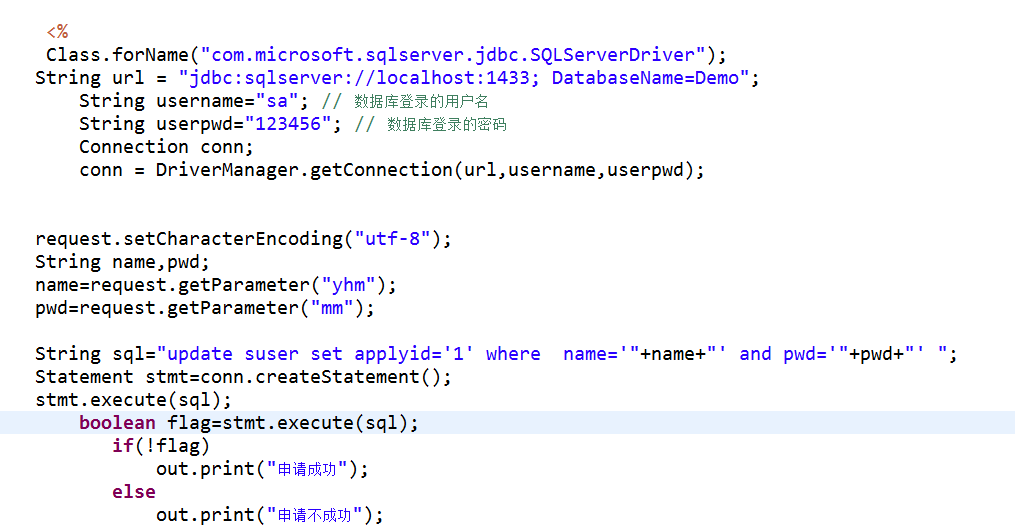
直接编写SQL语句
适用于简单场景或需要精细控制的情况:
INSERT INTO products (name, price, stock) VALUES ('iPhone 15', 999.99, 100);
批量插入优化技巧:

LOAD DATA INFILE '/tmp/bulk_data.csv' INTO TABLE logs FIELDS TERMINATED BY ','; -此方法比逐条INSERT快10倍以上!
️ 使用ORM框架
以Python SQLAlchemy为例:
from models import Product # 已映射好的模型类 session.add(Product(name="MacBook Pro", price=1999.99)) session.commit() # 自动生成INSERT语句并提交事务
优势在于:①类型校验防止错误数据入库;②迁移工具可自动同步表结构变更。
高性能场景解决方案
当面临每秒万级写入压力时:
- 批量提交:累积到一定数量后统一发送(如每500条一次)。
- 异步写入:采用消息队列(Kafka/RabbitMQ)解耦生产者与消费者,架构示例:Web应用→MQ→Worker进程→DB。
- 内存缓冲区:Redis作为热数据暂存层,定时刷入持久化存储,测试表明该模式可提升吞吐量300%。
异常处理机制
健壮系统必须考虑以下边界情况:
| 错误类型 | 应对策略 | 代码实现参考 |
|——————–|————————————————————————–|———————————–|
| 主键冲突 | 捕获DuplicateEntryException并记录日志,触发补偿逻辑 | try-catch块内增加重试计数器 |
| 连接超时 | 实现指数退避重连算法(Exponential Backoff),避免雪崩效应 | Tentacle库提供现成的重试装饰器 |
| 字符集乱码 | 确保客户端/服务端统一UTF8编码,字段类型选用TEXT而非BLOB | DDL语句指定CHARACTER SET utf8mb4 |
| 事务死锁 | 设置合理的Innodb锁等待阈值,超时后回滚当前事务 | SHOW ENGINE INNODB STATUS监控锁竞争 |
验证与监控
完成写入后务必进行双重确认:
- 程序层面校验:返回受影响行数是否匹配预期(如
cursor.rowcount == len(batch))。 - 数据库侧核查:执行
SELECT LAST_INSERT_ID();获取自增ID,或通过触发器记录审计日志,推荐启用Binlog以便灾难恢复。 - 可视化监控:Grafana面板展示QPS、延迟分布、活跃连接数等关键指标,Prometheus告警规则示例:当写入失败率>5%持续5分钟触发报警。
进阶优化方向
随着数据量增长,可逐步引入以下改进措施:
分库分表策略:按哈希取模分散热点数据到不同物理节点,例如用户ID%16决定所属分片。
索引优化:对高频查询字段建立复合索引,定期执行ANALYZE TABLE更新统计信息指导优化器选择执行计划,注意过度索引会降低写入性能。
冷热分离架构:近期三个月的数据存放SSD高速存储,历史归档至HDD低成本介质,配合中间件实现透明访问。
相关问答FAQs
Q1: 如果遇到“Too many connections”报错怎么办?
A: 这是由于连接池未合理配置导致资源耗尽,解决方案包括:①增大max_connections参数(MySQL默认为151);②在应用层使用连接池复用链接(如HikariCP);③排查是否存在泄漏的未关闭连接,推荐监控工具Percona Toolkit中的pt-query-digest分析慢查询根源。
Q2: 如何安全地迁移旧系统到新数据库?
A: 遵循分阶段灰度发布流程:①搭建双向同步通道验证增量一致性;②停写期间全量导出导入(推荐使用mydumper多线程工具);③切换后执行冒烟测试覆盖主干流程;④保留回滚方案至少24小时,对于超大数据集可采用停机转移+CDC(Change Data Captcha)追