上一篇
html超链接中如何传递数据
HTML超链接中,可通过URL查询参数、锚点或路径参数传递数据,接收方解析后即可获取信息
HTML中,超链接不仅是实现页面跳转的核心机制,还能通过多种方式传递数据,以下是几种主流的技术方案及其详细实现方法:
URL查询参数(GET方法)
这是最常用的方式,通过在目标地址后追加?key=value形式的键值对来传输信息。<a href="/target.html?name=张三&age=25">点击提交</a>,当用户点击该链接时,浏览器会将编码后的参数附加到请求头中发送至服务器端,这种方式适合传递少量非敏感数据,如搜索关键词或分页索引,需要注意的是,由于参数直接暴露在地址栏中,涉及隐私的内容应避免使用此方法。
| 特点 | 说明 |
|---|---|
| 可见性 | 所有参数都会显示在浏览器地址栏 |
| 长度限制 | 受浏览器和服务器的最大URL长度约束(通常约2048字符) |
| 编码处理 | 特殊符号需进行百分号编码(如空格转为%20) |
| 适用场景 | 表单预填、筛选条件传递、简单对象标识等 |
锚点定位(Fragment Identifier)
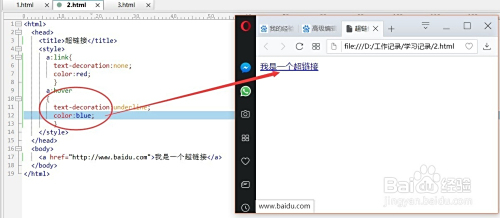
利用符号后的片段标识符可实现单页内滚动定位或状态管理,比如<a href="#section3">跳转到第三章</a>会使页面平滑滚动到id为section3的元素位置,进阶用法还包括结合JavaScript监听hashchange事件,动态加载对应模块而无需刷新整个页面,这种方式本质上不与服务器交互,完全由客户端解析执行。

| 功能类型 | 典型应用案例 |
|---|---|
| 页面内导航 | 长文档的章节快速定位 |
| 前端路由模拟 | SPAs(单页应用)中模拟多页面切换 |
| 状态标记 | 记录用户操作进度,如图片轮播当前选中项 |
路径参数模式
现代前端框架常采用RESTful风格的路由设计,将变量嵌入URL路径本身,原生HTML可通过手动构造实现类似效果,/user/123中的123代表用户ID,配合后端路由解析规则,能够优雅地处理资源层级关系,这种方法提高了URL可读性,也更符合SEO最佳实践。
JavaScript增强型传参
当需要传递复杂结构化数据时,可以先用脚本序列化为JSON字符串,再编码进URL,示例流程如下:
const data = { products: [{"id":1,"price":99}, ...] };
const encodedData = btoa(JSON.stringify(data)); // Base64编码
window.location.href = `/process?payload=${encodedData}`;
接收端则进行反向解码操作,不过要注意Base64会增加约33%的长度开销,且仍需注意总长度限制。
安全性考量要点
- 敏感信息保护:永远不要通过GET方式传输密码、信用卡号等机密数据,应改用POST表单提交;
- 注入攻击防范:对用户输入进行严格的校验与转义处理,防止跨站脚本攻击(XSS);
- 数据截断风险:重要参数建议放在POST请求体中传输,特别是超过1KB的大段文本;
- 缓存控制:对于含敏感操作的链接,添加
cache="no-store"元标签禁止缓存响应结果。
实际开发技巧
- 语义化命名:给参数起有意义的名字有助于维护,如用
sortBy=price_desc代替简单的数字编号; - 默认值设置:后端程序应该为缺失的可选参数提供合理的默认处理逻辑;
- 错误回退机制:设计优雅降级方案,当某些参数无效时仍能保持基本功能可用;
- URL规范化:统一参数顺序并去除冗余空格,有利于提升缓存命中率和SEO效果。
相关问答FAQs
Q1:如何确保通过超链接传递的数据不会被改动?
A:实际上无法绝对防止客户端层面的修改,但可以通过以下措施降低风险:①对关键参数进行签名验证(如HMAC算法生成校验码);②结合Token令牌实现权限校验;③重要操作要求二次确认,最根本的解决方案是将业务逻辑放在服务器端进行最终判断。
Q2:同一个页面内有多个带参数的链接指向不同锚点怎么办?
A:每个锚点对应独立的URL片段,浏览器会自动识别最新的hash变化,推荐使用唯一ID作为锚点名称,并通过history.pushState()方法更新浏览器历史堆栈,这样用户点击前进/后退按钮时能正确恢复各个状态,同时注意避免多个链接