上一篇
java异常一般怎么用
va异常通过try-catch块捕获处理,throws声明抛出,finally确保资源释放;可自定义异常类型并手动抛出(throw),根据异常类型执行相应逻辑。
Java编程中,异常处理是确保程序健壮性和稳定性的重要机制,以下是关于如何使用Java异常的详细说明,涵盖基本概念、分类体系、核心用法及最佳实践等内容:
理解异常的作用与意义
异常用于处理程序运行时发生的非正常情况(如文件不存在、数组越界等),其核心价值在于:①分离正常逻辑与错误处理代码;②提供跨函数/层的误差传递能力;③保证资源释放的安全性,通过合理使用异常,可以使代码更具可读性和维护性,同时避免因忽略潜在错误导致的崩溃风险。

异常体系的层级结构
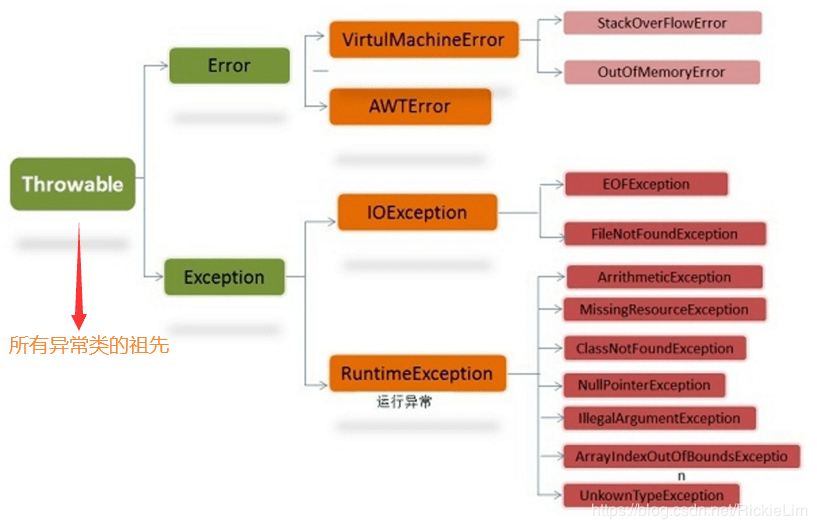
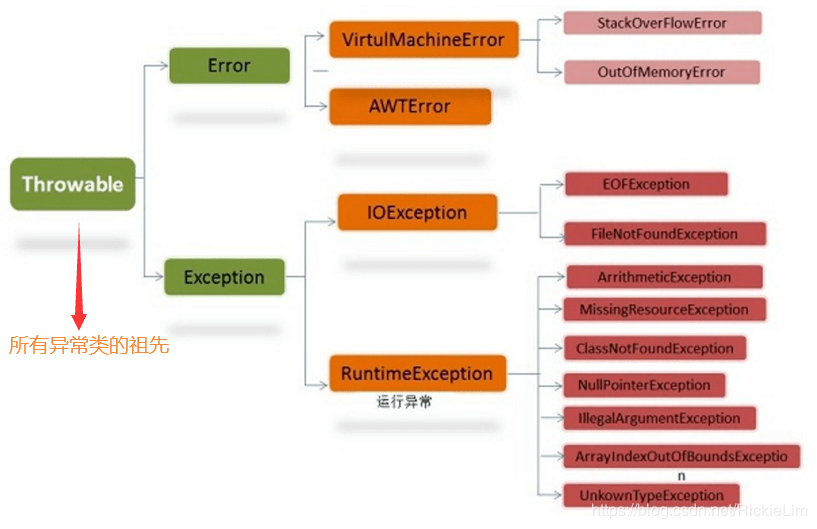
Java采用面向对象的设计模式构建了完整的异常类继承树:
| 基类 | 特点 | 典型子类举例 |
|——————–|———————————————————————-|———————————–|
| Throwable | 所有错误和异常的超类 | — |
| ├─ Error | 严重系统级故障(通常不可恢复),如内存溢出、JVM错误 | OutOfMemoryError, StackOverflowError |
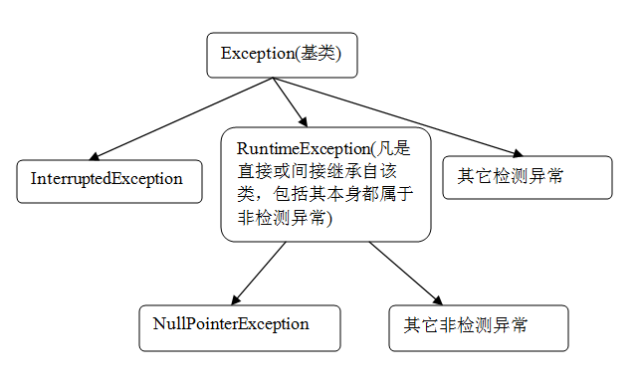
| └─ Exception | 应用程序应捕获并处理的常规异常 | IOException, SQLException, ClassNotFoundException |
| ├─RuntimeException | 未检查型异常(无需显式声明),多由编码缺陷引发 | NullPointerException, IndexOutOfBoundsException |
| └─其他受检异常 | 必须通过throws声明或try-catch块处理 | FileNotFoundException, MalformedURLException |
这种设计允许开发者灵活区分不同类型的错误场景,例如将可预见的I/O操作错误定义为受检异常,而将空指针引用这类编程失误归为运行时异常。
核心语法与实现方式
try-catch-finally结构
这是最基础的异常捕获机制,示例如下:
try {
// 可能抛出异常的操作
FileReader fr = new FileReader("data.txt");
int ch = fr.read();
} catch (FileNotFoundException e) { // 捕获特定类型的受检异常
System.err.println("目标文件未找到: " + e.getMessage());
e.printStackTrace(); // 打印完整调用栈跟踪
} catch (IOException ex) { // 捕获更通用的IO相关异常
logger.error("读取失败", ex); // 结合日志框架记录错误详情
} finally { // 确保执行清理工作的保障性代码块
if (fr != null) try { fr.close(); } catch (IOException ignored) {}
}
关键点:
- 精确匹配原则:优先捕获具体异常类,再逐步向上兼容(如先捕获
SQLException再捕获Exception); - 多路分支处理:同一try块可跟随多个catch子句应对不同异常类型;
- finally必执行性:无论是否发生异常,finally中的代码总会执行,适合关闭连接、解锁资源等收尾操作。
throw语句主动抛出异常
当检测到不符合业务规则的状态时,可以通过throw手动触发异常流程:
public static void validateAge(int age) {
if (age < 0 || age > 150) {
throw new IllegalArgumentException("年龄必须在0~150之间"); // 创建并抛出新实例
}
}
此处构造了一个带有描述信息的IllegalArgumentException对象,调用者能清晰了解错误原因,注意应选择语义最贴近的标准异常类型,必要时也可自定义继承自Exception类的专用异常。
throws子句声明方法可能抛出的异常
若方法内部可能产生受检异常且不愿自行处理,则需在签名中标注:
public void writeLogToDisk() throws IOException { / ... / }
这将强制调用方对该异常做出响应(要么继续抛出要么捕获处理),从而形成明确的错误传递路径,对于运行时异常则无此要求。
设计模式与进阶技巧
自定义异常体系构建
建议按照领域划分创建层次化的自定义异常类,
// 基础业务异常基类
class BusinessException extends Exception { public BusinessException(String msg) { super(msg); } }
// 订单模块专用异常
class OrderProcessingFailedException extends BusinessException { ... }
// 支付网关交互异常
class PaymentGatewayTimeoutException extends BusinessException { ... }
这种结构化的设计有助于实现精准的错误定位和分层过滤策略。
利用异常链保留原始上下文信息
在多层调用关系中维持完整的错误溯源非常重要:
try {
processOrder();
} catch (OrderProcessingFailedException e) {
throw new ApplicationException("订单处理失败", e); // 包装底层异常作为cause
}
通过initCause()方法或构造函数参数建立的异常链,可以在顶层统一入口处获取整个错误的演化过程。
断言机制辅助调试
虽然不属于正式的错误处理范畴,但适当使用assertion可以帮助发现潜在隐患:
assert userInput != null : "用户输入不能为空"; // JVM默认不启用,需添加-ea参数启动
该特性主要用于开发测试阶段的问题排查,生产环境通常禁用以提高性能。
常见误区规避指南
| 错误做法 | 正确替代方案 | 原因分析 |
|---|---|---|
| 过度捕获通用Exception类 | 尽量精确匹配具体异常类型 | 可能导致掩盖真实错误类型 |
| 忽略finally中的异常 | 在嵌套try块内单独处理每一个close() | 确保资源总能被正确释放 |
| 滥用异常控制流程 | 仅用于真正错误的边界条件 | 避免降低代码可读性和执行效率 |
| 吞掉异常不记录日志 | 至少打印堆栈跟踪或写入日志系统 | 便于后续排查问题根源 |
| 混淆错误返回值与异常 | 根据项目规范统一使用其中一种机制 | 保持API设计的一致性 |
性能考量因素
频繁的异常创建和传播会带来额外的开销,特别是在循环体内使用时尤其明显,基准测试表明,每次抛出异常大约需要消耗数百纳秒的时间成本,因此对于高频次的预期内状态判断,推荐采用条件语句而非异常机制:
// 低效写法(每次迭代都可能抛异常)
for (String item : list) {
if (!isValid(item)) throw new InvalidItemException(item);
}
// 高效写法(预先验证)
for (String item : filteredList) { / ... / }
只有在真正不可预见的错误场景下才应该依赖异常处理机制。
FAQs
Q1: 为什么说不要捕获过于宽泛的Exception?
A: 因为这样会丢失具体的异常类型信息,使得错误诊断变得困难,例如同时捕获IOException和SQLException时,无法区分到底是数据库连接失败还是文件读写出错,某些关键异常可能被错误地抑制,导致程序进入不稳定的状态。
Q2: finally块中的代码一定会执行吗?
A: 几乎总是如此,除非在执行finally之前JVM已经退出(如System.exit()被调用),但需要注意如果在finally中再次抛出异常,那么原异常将会丢失,因此最佳实践是在finally中仅进行资源清理等无状态操作,避免引入新的异常风险