上一篇
java怎么拆分一段字符串
va拆分字符串可用String.split()按正则表达式分割、StringTokenizer类迭代拆分,或substring()指定索引截取
使用 split() 方法(最常用)
这是最直接的方式,适用于大多数场景,其核心原理是通过指定的正则表达式作为分隔符来切割原始字符串,返回一个由子串组成的数组,需要注意的是,该方法属于 String 类的成员函数。
语法格式
public String[] split(String regex); // 或者带限制参数的版本: public String[] split(String regex, int limit);
- 参数说明:
regex: 正则表达式定义的分隔模式。,"\s+"(多个空白符)、"[a-zA-Z]+"等。limit(可选):控制结果数组的最大长度,若未提供此参数,则默认返回所有匹配项;若设置了该值,则仅保留前 N-1 个元素,最后一个元素包含剩余全部内容。
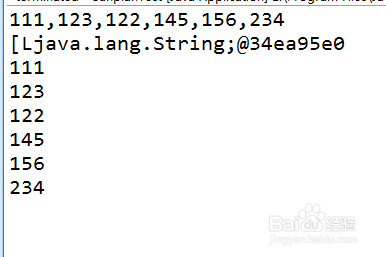
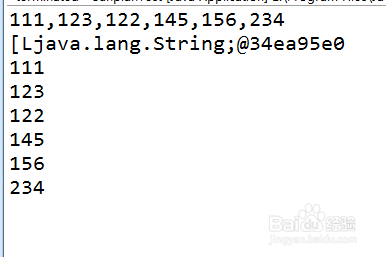
示例1:简单逗号分隔
假设有一个以逗号隔开的CSV行数据:"apple,banana,orange",希望将其拆分为水果名称列表。
String fruits = "apple,banana,orange";
String[] parts = fruits.split(","); // 得到 ["apple", "banana", "orange"]
for (String part : parts) {
System.out.println(part);
}
输出结果依次为:apple, banana, orange。
️ 特殊字符转义问题:如果分隔符本身是特殊符号(如点号 、竖线 ),必须进行转义处理,例如要按点号拆分IP地址
"192.168.1.1",应写成split("\."),因为 在正则中有“任意单个字符”的含义,需用双反斜杠取消特殊意义。
示例2:混合空白符分割
对于包含空格、制表符等多种空白的情况,可以用 \s+ 表示“一个或多个空白字符”,比如句子 "Hello world! How are you?" 按单词拆分:
String sentence = "Hello world! How are you?";
String[] words = sentence.split("\s+"); // 得到 ["Hello", "world!", "How", "are", "you?"]
这里 \s+ 匹配任意数量的空白字符(包括换行符 n、回车符 r 等)。
示例3:限制返回数量
当只需要部分结果时,可通过第二个参数优化性能,例如从长日志中提取前3个错误码:
String logEntry = "ERR001|WARN002|FAIL003|DEBUG004";
String[] errors = logEntry.split("\|", 3); // 只取前两个分割点后的三段
// errors[0]="ERR001", errors[1]="WARN002", errors[2]="FAIL003|DEBUG004"
此时第三个元素保留了后续所有内容,避免不必要的全局扫描。
其他实用技巧与变体
除了标准的 split(),还有一些扩展用法值得掌握:
| 场景 | 实现方式 | 说明 |
|---|---|---|
| 去除首尾多余空格 | trim().split(...) |
先调用 trim() 清理两端空白,再执行拆分 |
| 过滤空字符串 | 结合流式API过滤 | 使用 Java Stream API 跳过空元素 |
| 自定义复杂逻辑 | 手动遍历+索引截取 | 当正则无法满足需求时采用循环逐段提取 |
案例演示:过滤掉空字符串
某些情况下,连续的分隔符可能导致产生空字符串(如 a,,b → ["a", "", "b"]),这时可以通过流式处理剔除无效项:

import java.util.;
import java.util.stream.;
String input = "Java;;Python;Scala;";
List<String> nonEmptyItems = Arrays.asList(input.split(";"))
.stream()
.filter(s -> !s.isEmpty())
.collect(Collectors.toList());
// nonEmptyItems 现在包含 ["Java", "Python", "Scala"]
这种方法尤其适合处理用户输入中的异常格式。
常见错误与避坑指南
初学者容易犯以下几类错误:
-
忽略正则表达式的特殊含义
比如想用竖线 做分隔符却直接写split("|"),这会导致编译错误,正确写法是split("\|"),同理,其他元字符如 , , 也需要转义。 -
未考虑大小写敏感性
默认情况下正则是区分大小写的,若要实现不敏感匹配,可在模式前加(?i),"(?i)(and|or)"能同时匹配 AND/and/Or/or。 -
过度依赖单一方法导致效率低下
对于超大文本文件(GB级别),反复调用split()可能造成内存溢出,此时建议改用缓冲读取器逐行解析,或借助第三方库如 Apache Commons Lang 的StringUtils.splitPreserveAllTokens()。 -
混淆分割次数的影响
观察下面两段代码的差异:// Case A: 完全分割 "a,b,c".split(","); → ["a","b","c"] (长度3) // Case B: 最多分两次 "a,b,c".split(",", 2); → ["a","b,c"] (长度2)第二个参数决定了实际产生的子串数量上限。
进阶替代方案对比
虽然 split() 足够应对多数情况,但在特定场景下可能有更优选择:
| 工具/类库 | 适用场景 | 优势 |
|————————|———————————–|—————————————-|
| Scanner | 结构化文本解析(如配置文件) | 支持多种定界模式,可逐个读取字段 |
| StringTokenizer | 旧版兼容性项目 | 线程安全且无需正则知识 |
| OpenNLP/ICU4J | 多语言分词、语义级切分 | 专业NLP组件提供的高级文本分析能力 |
| Guava的Splitter | 需要链式配置时 | 更友好的API设计,支持OmitEmptyStrings等选项 |
例如使用 Guava 的 Splitter:
import com.google.common.base.Splitter;
Iterable<String> result = Splitter.on(',').omitEmptyStrings().split(input);
它能自动忽略空值并返回迭代器接口,适合大数据量下的懒加载模式。
性能考量与最佳实践
- 预编译Pattern对象复用
频繁调用相同正则式的split()会重复编译模式,影响效率,推荐预先创建Pattern实例:Pattern pattern = Pattern.compile(","); // 一次性编译开销较大但可重用 String[] arr = pattern.split(str); // 内部调用相同的Matcher实例更快 - 避免嵌套循环内的Split操作
在外层循环中反复执行split()可能导致O(n²)时间复杂度爆炸,解决方案是将中间结果缓存起来。 - 选择合适的数据结构存储结果
如果后续只需遍历一次,直接使用数组即可;若有动态增删改查需求,则转为ArrayList或其他集合类更灵活。
FAQs
Q1: 如果我要按中文标点“、”来拆分怎么办?
答:由于中文顿号不是ASCII字符,直接写入字符串即可无需转义,但要注意编码一致性(确保源文件保存为UTF-8),示例如下:
String chineseText = "北京、上海、广州";
String[] cities = chineseText.split("、"); // 正确拆分出三个城市名
若遇到乱码问题,请检查IDE/JDK的环境变量设置是否支持中文字符集。
Q2: 如何拆分包含引号包围内容的CSV单元格?(如 "Smith, John",Doe)
答:标准库难以完美处理带转义符的复杂CSV格式,推荐两种方案:
- 方案A 借助现成解析器:Apache Commons CSV库专门为此设计:
import org.apache.commons.csv.CSVParser; String inputLine = ""Smith, John",Doe"; Reader reader = new StringReader(inputLine); CSVParser parser = new CSVParser(reader); List<String> record = parser.parseNextRecord(); // record=[Smith, John, Doe]
- 方案B 自行实现状态机解析:跟踪是否处于引号内部的状态,遇到逗号但不在引号内时才视为分隔符,这需要编写较多逻辑代码,适合轻