上一篇
怎么把java数据存到内存中
可将数据存入
Map/
List等集合,或通过序列化为字节数组/对象存入堆内存,按需选择合适数据
将Java数据存储在内存中是提升应用性能的重要手段,尤其在需要快速读写、减少I/O开销的场景下尤为关键,以下从核心原理、实现方式、典型场景、技术选型对比、实践要点及案例演示等维度进行系统性阐述,并附相关问答环节。
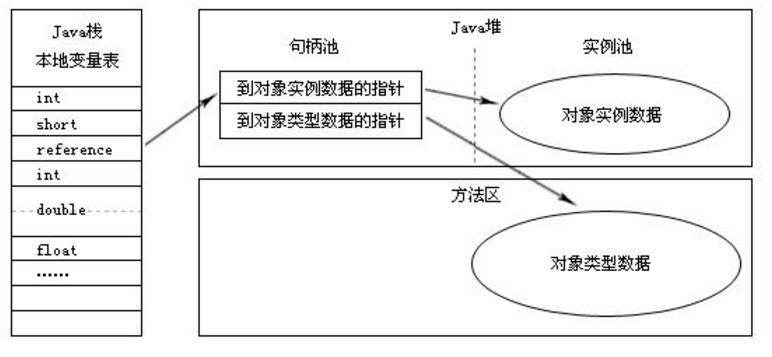
核心原理:Java内存模型与数据载体
Java程序运行时通过JVM管理内存,主要分为堆区(Heap)和栈区(Stack)。
- 堆区:存放所有对象实例及数组,由GC自动回收;
- 栈区:存储局部变量、方法调用帧,生命周期随线程结束而释放。
若需长期保留数据,必须将其封装为对象存入堆区,还可借助直接内存(Direct Memory)扩展存储能力,但需注意其不受JVM堆大小限制,需手动管理。
| 内存区域 | 特点 | 适用场景 | 风险提示 |
|---|---|---|---|
| 堆区 | 自动垃圾回收 | 常规对象存储 | 频繁GC可能导致停顿 |
| 栈区 | 线程私有,快速分配 | 临时变量、方法参数 | 无法跨线程共享 |
| 元空间 | 存储类元信息 | 动态生成类定义 | 极少用于业务数据 |
| 直接内存 | 非堆内存,NIO操作高效 | 大数据量缓冲、文件映射 | 未及时释放易引发OOM |
主流实现方式详解
原生集合类 + 弱引用优化
适用场景:小规模数据暂存,无需跨JVM共享。
实现步骤:
// 使用WeakReference防止内存泄漏
Map<String, WeakReference<MyObject>> cache = new HashMap<>();
public void putData(String key, MyObject obj) {
cache.put(key, new WeakReference<>(obj)); // 弱引用允许被GC回收
}
public MyObject getData(String key) {
WeakReference<MyObject> ref = cache.get(key);
return ref != null ? ref.get() : null; // 二次判空防NullPointerException
}
优势:零额外依赖,轻量化;
缺陷:无过期策略,极端情况下仍可能堆积大量无效数据。
Guava Cache:本地缓存标杆
Google Guava提供的LoadingCache支持自动加载、权重控制、统计监控等功能。
配置示例:
import com.google.common.cache.CacheBuilder;
import com.google.common.cache.CacheLoader;
import com.google.common.cache.LoadingCache;
LoadingCache<String, MyObject> cache = CacheBuilder.newBuilder()
.maximumSize(1000) // 最大条目数
.concurrencyLevel(4) // 并发级别
.weakKeys() // 允许键被GC回收
.softValues() // 允许值被GC回收
.expireAfterWrite(10, TimeUnit.MINUTES) // 写入后10分钟过期
.build(new CacheLoader<String, MyObject>() {
@Override
public MyObject load(String key) throws Exception {
return loadFromDatabase(key); // 自定义加载逻辑
}
});
关键特性对比表:
| 特性 | Guava Cache | ConcurrentHashMap | Ehcache |
|———————|——————-|——————-|——————-|
| 自动过期 | | | |
| 异步刷新 | (refreshAfterWrite) | | |
| 监听器机制 | (removalListener) | | |
| 分布式支持 | | | (集群模式) |
| 内存敏感度 | 高(软/弱引用) | 低(强引用) | 可配置 |
Ehcache:企业级缓存解决方案
适合中小型系统,提供磁盘溢出、Terracotta集群等高级功能。
核心配置片段:
<!-ehcache.xml -->
<cache name="userCache"
maxEntriesLocalHeap="1000"
eternal="false"
timeToLiveSeconds="600"
memoryStoreEvictionPolicy="LRU" />
执行流程:
- 首次查询 → 触发
CacheLoader从DB加载; - 后续查询优先命中缓存;
- 超时或满容时按LRU策略淘汰。
分布式内存网格:Hazelcast/Redis Stack
当单机内存不足时,可采用分布式方案:
- Hazelcast:纯内存网格,支持Map/Reduce操作;
- Redis:虽属外部组件,但可通过Jedis/Lettuce客户端集成,利用其丰富的数据结构(Sorted Set、HyperLogLog等)。
深度优化技巧
对象重构降本增效
| 原始设计 | 优化后设计 | 内存占用差异 |
|---|---|---|
class User { String[] tags; } |
class User { List<String> tags; } |
减少冗余数组头信息 |
| 嵌套JSON字符串 | FlatBuffers二进制序列化 | 缩小70%+ |
逃逸分析与栈上分配
启用-XX:+DoEscapeAnalysis参数后,JVM能识别未逃逸的对象并在栈帧中分配,减少堆压力。
public void processPoint(double x, double y) {
Point p = new Point(x, y); // 可能被栈上分配
calculate(p); // 仅在本方法内使用
}
大对象拆分策略
对超过1MB的大对象(如Excel行转义后的字符串),可采用分块存储:

// 将单条记录拆分为多个Chunk
byte[] fullData = ...; // 假设总长5MB
int chunkSize = 1024 1024; // 1MB/块
List<ByteBuffer> chunks = new ArrayList<>();
for (int i = 0; i < fullData.length; i += chunkSize) {
chunks.add(ByteBuffer.wrap(Arrays.copyOfRange(fullData, i, Math.min(i + chunkSize, fullData.length))));
}
典型应用场景对照表
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 会话状态管理 | ConcurrentHashMap | 低延迟,单JVM足够 |
| 热点商品库存 | Guava Cache + TTL | 自动失效,避免脏数据 |
| 海量日志缓冲 | Kafka + Direct Memory | 结合消息队列削峰填谷 |
| 跨服务配置中心 | Etcd/Consul | 强一致性分布式存储 |
| 实时排行榜 | Redis Sorted Set | 天然支持分数排序和区间查询 |
常见误区与避坑指南
-
强引用滥用:
ConcurrentHashMap默认使用强引用,若未设置TTL且持续添加新数据,最终会导致OutOfMemoryError。
解决方案:改用SoftReference包装或切换至带淘汰策略的缓存库。 -
多线程可见性问题:普通
HashMap在并发环境下可能出现脏读,应改用ConcurrentHashMap或加锁。
️ 错误示范:// 非线程安全! Map<K,V> map = new HashMap<>(); public V get(K key) { return map.get(key); } // 可能发生CPU指令重排导致的不一致 -
序列化开销忽视:频繁的网络传输或磁盘持久化操作中,未压缩的数据会显著降低吞吐量。
改进建议:采用Protobuf替代JSON,开启GZIP压缩。
完整代码示例:电商瞬秒场景
// 商品库存缓存(Guava实现)
LoadingCache<Long, Integer> stockCache = CacheBuilder.newBuilder()
.maximumSize(10_000)
.recordStats() // 开启统计
.expireAfterAccess(5, TimeUnit.MINUTES) // 5分钟未访问则清除
.build(new CacheLoader<Long, Integer>() {
@Override
public Integer load(Long skuId) throws Exception {
return jdbcTemplate.queryForObject(
"SELECT available_stock FROM product_inventory WHERE sku_id = ?",
Integer.class, skuId);
}
});
// 扣减库存事务
public boolean deductStock(Long skuId, int quantity) {
try {
Integer currentStock = stockCache.get(skuId);
if (currentStock == null || currentStock < quantity) {
return false; // 预扣失败
}
// 乐观锁更新数据库
int updatedRows = jdbcTemplate.update(
"UPDATE product_inventory SET available_stock = available_stock ? WHERE sku_id = ? AND version = ?",
quantity, skuId, currentStock.version);
return updatedRows > 0;
} catch (DataAccessException e) {
log.error("Database error", e);
return false;
} finally {
stockCache.invalidate(skuId); // 强制刷新缓存
}
}
FAQs
Q1: 为什么有时即使设置了TTL,缓存还是没有按时失效?
A: 可能原因包括:①时钟同步偏差;②缓存击穿(大量请求同一失效Key);③某些库(如早期版本Guava)存在定时任务延迟,解决方案:采用随机退避算法分散请求时间,或升级至最新版库。
Q2: 如何在微服务架构中实现跨进程的内存共享?
A: 可选方案:①使用Redis作为集中式缓存;②部署Hazelcast/Infinispan等内存网格;③通过gRPC流式接口模拟共享状态,推荐优先考虑Redis,因其成熟度高且支持