上一篇
怎么用函数公司检查重复的数据库
Excel中,可用COUNTIF函数检查重复数据,如在B2输入=COUNTIF(A:A, A2)并下拉填充,B列大于1即
重复项
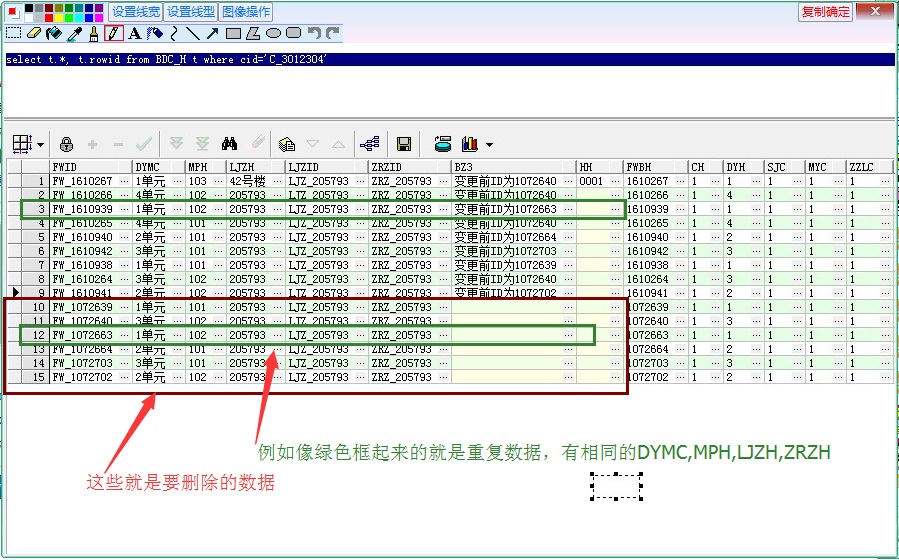
数据库管理中,检测重复数据是一项常见且重要的任务,以下是几种常用的方法来实现这一目标,主要依赖于SQL函数和一些高级特性,每种方法都有其适用场景和优缺点,具体选择取决于你的需求以及所使用的数据库系统。
使用GROUP BY与HAVING子句结合COUNT()函数
这是最基础也是最常用的一种方式,基本思路是对某一列或多列进行分组,然后统计每组的记录数,最后筛选出数量大于1的结果集,假设我们有一个名为employees的员工表,想要找出姓名相同的员工:
SELECT name, COUNT() as count FROM employees GROUP BY name HAVING COUNT() > 1;
上述代码会返回所有出现次数超过一次的名字及其对应的总条数,如果还需要查看具体的重复条目详情,可以进一步扩展此查询:
SELECT FROM employees e1 JOIN (SELECT name, COUNT() as cnt FROM employees GROUP BY name HAVING cnt > 1) t ON e1.name = t.name;
这种方法简单直接,适用于大多数关系型数据库(如MySQL、PostgreSQL等),但缺点是无法精确定位到哪些行是完全相同的(即全部字段都一致)。

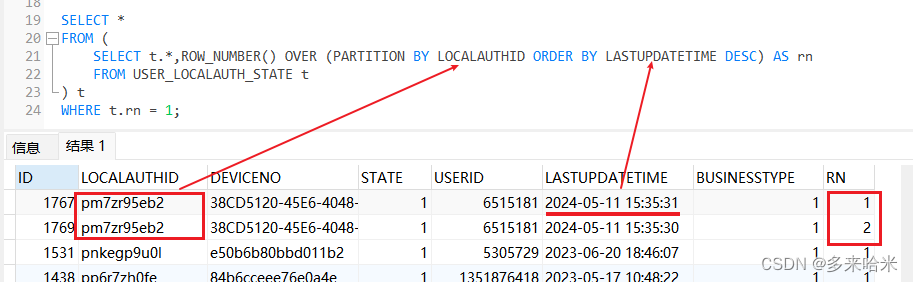
利用窗口函数ROW_NUMBER()
窗口函数提供了更灵活的处理方式,特别是当需要保留原始数据集中的额外信息时非常有用,以MySQL为例,可以通过以下步骤操作:
- 创建一个临时排名列,基于整个表的分区并按顺序编号;
- 根据这个新生成的序号来判断是否存在重复项。
示例如下:WITH ranked AS ( SELECT , ROW_NUMBER() OVER (PARTITION BY column_to_check ORDER BY some_other_column) AS rownum FROM your_table ) SELECT FROM ranked WHERE rownum > 1;
这里
column_to_check代表你要检查是否重复的那个字段,而some_other_column则用于确定排序规则,这种方式的好处是可以很容易地扩展到多个维度上的比较,并且能够清晰地看到哪些行被认为是重复的。
使用DISTINCT关键字辅助验证唯一性
虽然DISTINCT本身并不能直接告诉我们哪些数据是重复的,但它可以帮助快速了解某个域内的唯一值集合,若想知晓‘department’部门下的不同职位种类,可写:
SELECT DISTINCT position FROM jobs WHERE department = 'IT';
通过对比实际存在的不同值的数量与预期应有的唯一值数目之间的差异,间接推断出可能存在重复的情况,不过这种方法更多作为一种补充手段,单独使用时效果有限。
多条件组合查询优化复杂情况下的准确性
有时仅靠单一字段不足以准确定义“重复”,此时可以考虑联合多个属性作为判断标准,在一个订单系统中,可能希望同时考虑客户ID、产品编号及购买日期这三个因素来确定是否存在完全相同的交易记录:
SELECT order_id, customer_id, product_code, order_date, COUNT() over(PARTITION BY customer_id, product_code, order_date) as dup_flag FROM orders;
这样就能更精准地识别出符合特定条件的重复项。
| 方法 | 优点 | 局限性 |
|---|---|---|
| GROUP BY + HAVING | 实现简单,广泛支持 | 只能识别指定列上的重复,难以处理全行匹配的问题 |
| 窗口函数 | 灵活性高,可保留更多上下文信息 | 语法相对复杂,对新手不太友好 |
| DISTINCT | 快速获取唯一值列表 | 不能直接指出具体的重复记录 |
| 多条件组合 | 提高准确性,适应复杂业务逻辑 | 编写和维护成本较高 |
注意事项
- 性能考量:对于大型数据集,复杂的查询可能会导致较长的执行时间,建议先在小规模样本上测试优化后的SQL语句。
- 索引影响:合理设置索引有助于加快查询速度,但也应注意过度索引带来的写入开销增加的问题。
- 事务处理:如果是在线环境中的应用,确保在事务内执行此类操作以避免数据不一致的风险。
以下是相关问答FAQs:
Q1: 如果我只想要删除而不是仅仅查找这些重复记录怎么办?
A1: 你可以使用类似的逻辑构造DELETE语句,对于前面提到的GROUP BY例子,可以将外层包装成一个子查询,然后在主查询中使用DELETE代替SELECT,注意一定要谨慎操作,最好备份数据后再进行批量删除。
Q2: 我使用的是NoSQL数据库,上述方法还适用吗?
A2: NoSQL数据库的结构不同于传统的关系型数据库,因此上述基于SQL的解决方案可能不完全适用,不过许多NoSQL平台也提供了自己的机制来处理类似问题,比如MongoDB中的find()方法和Aggregation Pipeline框架就可以用来实现类似的功能,具体实现方式