上一篇
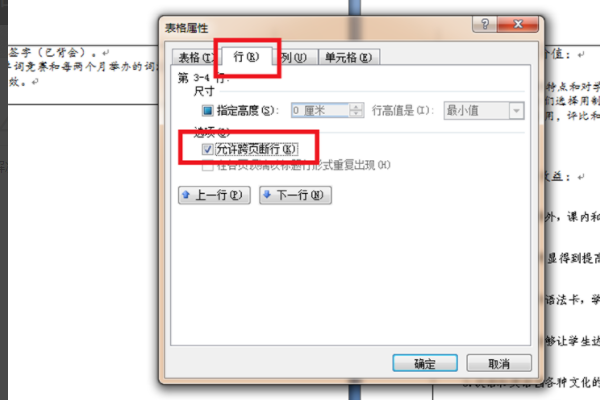
html2canvas如何分页

ml2canvas可通过结合jspdf等工具实现分页,先渲染成canvas,再按PDF高度计算
分页节点截取内容,优化切断处坐标后合并成多页PDF
是关于 html2canvas 如何实现分页的详细解决方案:
核心挑战
当使用 html2canvas 结合 jsPDF 等工具生成多页文档时,默认的固定高度切割方式(如按每页 A4 纸的标准高度切片)会导致以下问题:
- 语义断裂:文字行、表格等内容被机械地截断在页面之间;
- 可读性差:跨页的图表或关联性强的数据块被迫分离;
- 布局错乱:未考虑元素的自然边界(如段落结束位置)。
这些问题源于传统方案仅基于坐标系统的物理分割,而非内容的逻辑结构,因此需要采用更智能的策略来识别并保留内容的完整性。
进阶实现方案:基于元素分析的动态分页
预处理阶段:收集关键节点信息
遍历目标容器内的所有子元素,记录每个元素的起始位置、高度及类型(文本/图片/表格等)。
const elements = [];
document.querySelectorAll('#targetDiv ').forEach(el => {
const rect = el.getBoundingClientRect();
elements.push({
top: rect.top,
bottom: rect.bottom,
type: el.tagName, // 区分不同标签的处理逻辑
content: el.innerHTML || ''
});
});
此步骤为后续判断是否应在此处分页提供数据基础。
构建虚拟渲染流模型
模拟实际打印时的垂直堆叠过程,维护当前累积高度 currentTotalHeight 和最大允许单页高度 maxPageHeight(通常对应 A4/Letter 尺寸减去边距),每当添加新元素时检查两个条件:
- 如果该元素单独占据剩余空间仍超限 → 强制分页;
- 如果与前一个元素属于同一逻辑组(如同一章节的小标题+正文),则尝试合并到同一页。
智能断点决策算法
采用优先级规则确定最佳分页位置:
| 优先级 | 判断依据 | 操作方式 |
|——–|——————————|————————|
| Lvl1 | 遇到 <hr>/分节符标记 | 立即在此插入分页符 |
| Lvl2 | 当前元素是完整标题层级 | 保持其与下文内容的关联 |
| Lvl3 | 表格/图表等不可拆分组件 | 确保整体落入同一页面内 |
| Lvl4 | 普通文本段落的自然段结束处 | 优先作为候选断点 |
通过逐级匹配这些规则,可有效避免破坏内容的语义连贯性。
动态调整与回溯机制
若发现某次分页导致后续页面出现大量空白(如孤悬的大标题),则触发回溯重算:将最近一次分页点向后移动至下一个合适的位置,这种自适应能力能显著提升版面利用率。
典型代码架构示例
async function generatePaginatedPDF() {
const { jsPDF } = require('jspdf');
const canvas = await html2canvas(document.body);
let currentY = 0;
const pageHeight = 841; // A4高度(单位:px)
while (currentY < canvas.height) {
// 第一步:预测下一段内容的占用空间
const nextSegment = findNextLogicalBreakpoint(currentY);
// 第二步:校验是否适合放入当前页
if (nextSegment.endPos > pageHeight) {
// 触发分页操作
doc.addPage();
currentY = nextSegment.startPos;
} else {
// 继续填充当前页
const imageData = canvas.getContext('2d').getImageData(0, currentY, canvas.width, nextSegment.length);
doc.addImage(imageData, 'JPEG', 0, doc.internal.getCurrentPosition());
currentY += nextSegment.length;
}
}
}
注意:上述伪代码中的
findNextLogicalBreakpoint()需自行实现,其核心在于解析 DOM 树并应用前述的规则集。
优化技巧补充
- 缓存机制:对重复出现的结构(如列表项)建立索引库,减少重复计算开销;
- 预渲染缩放:先以较低分辨率快速生成草稿图,用于估算大致换行位置,再进行高清渲染;
- 用户干预选项:允许手动插入
data-nosplit属性标记禁止拆分的区域。
️ 常见误区警示
| 错误做法 | 后果 | 正确替代方案 |
|---|---|---|
| 单纯按固定像素值切割 | 破坏表格完整性 | 识别 <table> 标签整体保留 |
| 忽略字体大小差异的影响 | 导致段落中间意外断句 | 根据 CSS font-size 动态修正阈值 |
| 未处理浮动元素的定位异常 | 图片错位引发内容重叠 | 先转为静态布局再进行转换 |
FAQs
Q1: 为什么使用 html2canvas 生成的 PDF 会出现内容截断?
答:这是因为默认的分页逻辑仅基于坐标系统的物理切割,未考虑 HTML 元素的语义边界,例如连续文本可能被切成两半,表格也会被拆分到不同页面,解决方案是通过分析 DOM 结构识别逻辑断点(如段落结束、标题层级变化),并在此处插入分页符。
Q2: 如何在特定元素后强制分页?
答:可以为该元素添加自定义属性(如 data-pagebreak="true"),然后在解析时检测此标记,当遍历到带有该属性的元素时,立即结束当前页面并新建一页,同时建议配合 CSS 确保该