上一篇
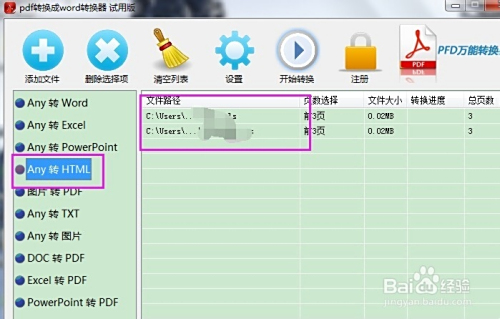
html如何转excel表格
HTML表格结构提取后,用编程工具(如Python的pandas库)解析并写入
HTML转换为Excel表格是一个常见需求,尤其在数据处理和分析场景中,以下是详细的实现方法及注意事项:
直接复制粘贴法(适用简单结构)
-
操作步骤

- 打开浏览器并加载目标网页,选中需要导出的表格区域(可用鼠标拖拽或Ctrl+A全选)。
- 右键选择“复制”(或按Ctrl+C),切换到Excel软件界面,点击首页的“粘贴”按钮下的倒三角图标,选择“保留文本”格式,此方式能去除大部分样式干扰,但仅适用于无嵌套布局的基础表格。
- ️局限性:若原HTML包含复杂框架、动态脚本或非标准标签,可能导致数据错位,合并单元格、跨行跨列的设计会被拆分成独立单元。
-
优化技巧
使用Word作为中转站:先将HTML内容粘贴到Word文档,利用其“表格工具”整理结构后再转入Excel,可减少格式丢失风险。
手动重构法(精准控制版)
适合对数据质量要求较高的场景:
-
解析HTML源码
通过浏览器开发者工具查看DOM结构,定位<table>标签及其内部的<tr>(行)、<td>(单元格)元素,记录每个单元格的内容与位置关系。 -
新建Excel逐项填充
根据解析结果在Excel中重建表头、数据行,并设置相应的格式,此方法虽耗时但能确保完全匹配原始逻辑,尤其适合处理带有注释类特殊符号的内容。 -
示例对比表
| HTML标签 | Excel对应功能 | 说明 |
|—————-|———————–|————————–|
|<table>| 工作表整体范围 | 定义数据边界 |
|<caption>| 工作表标题 | 显示于顶部 |
|<thead>| 冻结窗格中的标题行 | 方便滚动查看 |
|<colgroup>| 列宽自定义 | 需手动调整默认宽度 |
|<tbody>| 主体数据区域 | 逐行映射到A1:Xn区间 |
自动化工具方案(高效批量处理)
推荐工具清单:
| 工具类型 | 代表软件/库 | 优势 | 典型用法 |
|---|---|---|---|
| 桌面端插件 | Tabula | 智能识别非规范表格 | 导入时自动对齐多级标题 |
| Python生态 | BeautifulSoup+pandas | 可编程处理海量网页数据 | soup.find_all('table')提取核心块 |
| JavaScript库 | Tableau API | 交互式可视化转换 | convertHtmlToSheet()函数调用 |
| 在线转换平台 | CloudConvert | 无需安装即用 | 支持URL直链解析 |
代码示例(Python):
from bs4 import BeautifulSoup
import pandas as pd
html_doc = open('data.html').read()
soup = BeautifulSoup(html_doc, 'html.parser')
tables = soup.find_all('table')[0] # 获取第一个表格
# 提取表头
headers = [th.get_text() for th in tables.find('thead').find_all('th')]
# 提取每行数据
rows = []
for tr in tables.find('tbody').find_all('tr'):
row_data = [td.get_text(strip=True) for td in tr.find_all(['td', 'th'])]
rows.append(row_data)
df = pd.DataFrame(rows, columns=headers)
df.to_excel('output.xlsx', index=False)
该脚本可处理绝大多数标准HTML表格,并通过pandas自动优化列类型。
特殊场景应对策略
- 动态加载内容
部分网页依赖JavaScript异步生成数据,此时需先用Selenium模拟浏览器行为完成渲染,再抓取最终态的DOM树,例如电商价格监控类页面常采用此技术。 - 分页表格拼接
遇到AJAX分页加载的情况,可通过修改请求参数循环获取各页JSON数据,最后合并成完整数据集后导出,这要求目标站点未做反爬限制。 - 图像型表格OCR识别
极少数老旧系统会以图片形式展示表格,这时需要结合Tesseract等光学字符识别引擎进行解码,但准确率受字体复杂度影响较大。
常见问题排查指南
| 现象 | 可能原因 | 解决方案 |
|---|---|---|
| 数字存储为文本格式 | 单元格前导空格/特殊符号 | 使用“分列”功能重新指定类型 |
| 超长文本被截断显示 | 列宽不足 | 双击列标交界处自动适配宽度 |
| 日期变成序列号 | 区域格式设置错误 | 设置为“短日期”或自定义格式码 |
| 丢失批注信息 | HTML无对应元数据标签 | 转为备注栏文字说明 |
FAQs
Q1: 为什么从网页复制到Excel后会出现乱码?
A: 这是由于编码不兼容导致的,解决方法是在粘贴时选择“Unicode文本”,或者先粘贴到记事本再转入Excel,对于包含中文的场景,建议统一保存为UTF-8编码格式。
Q2: 如何保留原始表格中的链接和图片?
A: Excel本身不支持直接嵌入HTML多媒体元素,替代方案是将图片另存为独立文件,在对应单元格插入路径;链接可通过VBA宏实现跳转功能,但普通