上一篇
html如何转换为xml文件怎么打开
可将 HTML 通过编程(如 Python 的 lxml 库)解析后按 XML 规则重写标签生成 XML 文件;也可用在线转换工具,生成的 XML 文件可用浏览器、记事本、VS Code 等
以下是关于HTML如何转换为XML文件及打开方式的完整指南,涵盖核心原理、操作步骤、工具推荐、注意事项以及常见问题解决方案:
HTML与XML的本质区别
在讨论转换前需明确二者定位差异:
| 特性 | HTML | XML |
|—————-|——————————|———————————-|
| 设计目标 | 网页内容展示 | 数据存储与交换 |
| 标签语义 | 预定义标签(如<p>, <h1>)| 自定义标签(需严格遵循规则) |
| 容错性 | 宽松(浏览器自动修正错误) | 严格(任何格式错误导致解析失败) |
| 默认行为 | 渲染可视化页面 | 仅描述数据结构 |
| 属性引号 | 可选 | 强制要求 |
| 空元素写法 | <br> | <br/> 或 <br></br> |
| 注释语法 | <!---> | <!--->(完全相同) |
这种差异决定了转换并非简单的“一键替换”,而是需要系统性调整文档结构。
HTML转XML的完整流程
▶ 阶段1:预处理原始HTML文件
-
清理冗余代码
- 删除所有JavaScript/CSS内联代码(建议移至外部文件)
- 移除
<script>、<style>标签 - 修正嵌套混乱的表格结构(如跨行合并单元格)
- 统一特殊字符转义(
&→&,<→<等)
-
标准化标签命名
- 将语义化不强的
<div>改为业务相关标签(如<article>,<section>) - 为图片添加
alt属性并包裹在<img>标签内 - 将所有单标签改为自闭合形式(如
<input />)
- 将语义化不强的
-
处理特殊结构
- 框架集(Frameset):需重构为嵌套的
<object>或<iframe> - Applet/Object标签:替换为现代替代方案或删除
- Basefont标签:改用CSS字体设置
- 框架集(Frameset):需重构为嵌套的
▶ 阶段2:执行转换操作
方法1:手工逐行修改(适合小型文件)
<html> + <?xml version="1.0" encoding="UTF-8"?> <head> + <root>示例文档</title> + <metadata> + <title>示例文档</title> + <author>张三</author> + </metadata> <body> + <content> <h1>章节标题</h1> <p>段落文本...</p> + <chapter> + <heading level="1">章节标题</heading> + <paragraph>段落文本...</paragraph> + </chapter> </body> + </content> </html> + </root>
关键修改点:

- 添加XML声明头
- 创建唯一根元素(如
<root>) - 重命名所有HTML标签为有意义的XML标签
- 为所有属性添加引号(如
class="main") - 关闭所有未闭合标签(如
<img src="..." />)
方法2:借助工具批量转换(推荐)
| 工具类型 | 代表工具 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 在线转换器 | CloudConvert | 快速测试小文件 | 无需安装,操作简单 | 大文件隐私风险,功能有限 |
| 桌面软件 | Altova MapForce | 复杂结构映射 | 可视化界面,支持XSLT/XQuery | 商业付费,学习曲线较陡 |
| IDE插件 | Notepad++ XML Tools | 边写边验证 | 实时语法高亮,错误提示即时 | 依赖特定编辑器 |
| 命令行工具 | xsltproc (Linux) | 自动化集成构建流程 | 可编写脚本批量处理 | Windows用户配置复杂 |
| 编程库 | lxml (Python) | 深度定制转换逻辑 | 灵活控制每个节点的处理 | 需要编程基础 |
典型工具使用示例(以Python+lxml为例):
from lxml import etree, html
# 解析HTML文件
parser = html.HTMLParser(remove_blank_text=True)
tree = html.parse('input.html', parser)
# 获取根节点并修改名称
root = tree.getroot()
root.tag = 'root'
# 递归处理所有子节点
def rename_tags(node):
if node.tag == 'body':
node.tag = 'content'
elif node.tag == 'h1':
node.tag = 'heading'
# 添加更多规则...
for child in node:
rename_tags(child)
rename_tags(root)
# 保存为XML文件
etree.ElementTree(root).write('output.xml', pretty_print=True, xml_declaration=True, encoding='utf-8')
▶ 阶段3:验证与优化
-
W3C校验
访问https://validator.w3.org/xml/上传文件,重点检查:- Well-formedness(良好格式):标签匹配、属性引号等
- Validity(有效性):是否符合关联的DTD/XSD约束
-
性能优化
- 压缩空白字符(保留必要缩进)
- 移除注释中的调试信息
- 对重复出现的模式使用实体引用(如
<!ENTITY copyright "© 2023 Company">)
XML文件的打开方式大全
方法1:文本编辑器直接查看
| 编辑器类型 | 推荐软件 | 优势 | 注意事项 |
|---|---|---|---|
| 轻量级 | VS Code / Sublime Text | 语法高亮+折叠功能 | 需安装XML插件 |
| 专业级 | Oxygen XML Editor | 网格视图/模式视图切换 | 体积较大 |
| 跨平台 | Atom / Geany | 插件扩展性强 | 默认不支持XML校验 |
操作技巧:
- 使用”Split View”分屏显示代码和预览效果
- 配置自动格式化快捷键(Ctrl+Alt+L)
- 启用软换行(Line Wrapping)提升可读性
方法2:浏览器渲染(仅限特定场景)
虽然浏览器本质是HTML渲染引擎,但可通过以下方式查看XML:
- 原生支持:Chrome/Firefox直接打开XML文件会显示树状结构
- XSLT转换:创建
.xsl样式表文件,通过<?xml-stylesheet type="text/xsl" href="style.xsl"?>关联 - JSON中介:先用
xmltodict库转为JSON,再用浏览器查看结构化数据
方法3:专用阅读器软件
| 平台 | 软件名称 | 特点 |
|---|---|---|
| Windows | XML Marker | 彩色标注不同层级元素 |
| MacOS | Xcode | 集成开发环境内置XML编辑器 |
| Linux | gXML | 命令行+图形界面双模式 |
| 移动端 | TurtleView (Android) | 触摸友好的树形导航 |
典型应用场景案例
案例1:图书元数据转换
输入HTML片段:
<div class="book">
<h2>深入理解计算机系统</h2>
<span class="author">Randal E. Bryant</span>
<ul>
<li>ISBN: 978-7-121-45678-9</li>
<li>出版日期: 2023-05-15</li>
</ul>
</div>
输出XML结果:
<?xml version="1.0" encoding="UTF-8"?>
<library>
<book id="BK001">深入理解计算机系统</title>
<author>Randal E. Bryant</author>
<isbn>978-7-121-45678-9</isbn>
<publish_date>2023-05-15</publish_date>
</book>
</library>
应用价值:便于导入图书馆管理系统,实现与其他机构的元数据交换。
案例2:科研数据归档
某实验室采集的设备日志原本存储为HTML表格,转换为XML后:
<experiment id="EXP-2023-007">
<device name="Spectrometer" model="SPM-3000"/>
<parameters>
<wavelength unit="nm">532</wavelength>
<intensity unit="mW">45.2</intensity>
</parameters>
<readings>
<data point="1" value="0.87" error="±0.02"/>
<data point="2" value="0.91" error="±0.03"/>
<!-... -->
</readings>
</experiment>
这种结构化存储满足SCI论文附件的FAIR原则(可发现、可访问、可互操作、可重用)。
常见问题FAQs
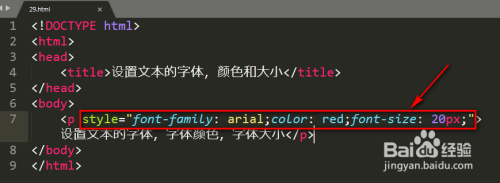
Q1:转换后的XML文件在浏览器中显示乱码怎么办?
A:这是编码问题导致的,解决方法:
- 确保XML声明头指定正确编码:
<?xml version="1.0" encoding="UTF-8"?> - 检查源HTML文件的实际编码(可用Notepad++查看)
- 如果包含中文字符,优先使用UTF-8编码
- 在浏览器中手动设置编码:右键→编码→选择UTF-8
- 终极方案:用Base64编码嵌入二进制数据(适用于特殊字符集)
Q2:能否反向将XML转回HTML?需要注意什么?
A:可以但需谨慎处理以下问题:
- 标签映射冲突:如XML中的
<head>可能对应HTML的<head>或<header> - 样式丢失:XML不保存CSS样式信息,需重新应用样式表
- 行为差异:如XML的
<a href="...">不会自动变成超链接,需添加事件处理 - 推荐工具:使用XSLT处理器配合精心设计的样式表进行逆向转换,或采用混合策略(保留部分HTML片段)
归纳与建议
- 小型项目:优先使用在线转换工具快速验证可行性
- 中型项目:采用Python+lxml组合实现半自动化转换
- 大型项目:建立完整的XSD模式约束,使用专业工具链(如Oxygen XML Editor + Jenkins持续集成)
- 最佳实践:始终保留原始HTML作为备份,转换过程分阶段进行,每步都进行校验
- 未来趋势:关注JSON-LD等新型数据格式,必要时考虑多格式共存方案
通过以上系统化的转换流程和工具选择,您可以高效地将HTML内容转化为符合标准的XML文档,满足数据交换、存档、系统集成等多种需求,实际操作中建议从简单样本开始测试,逐步完善转换规则,最终