上一篇
java怎么和数据库连接
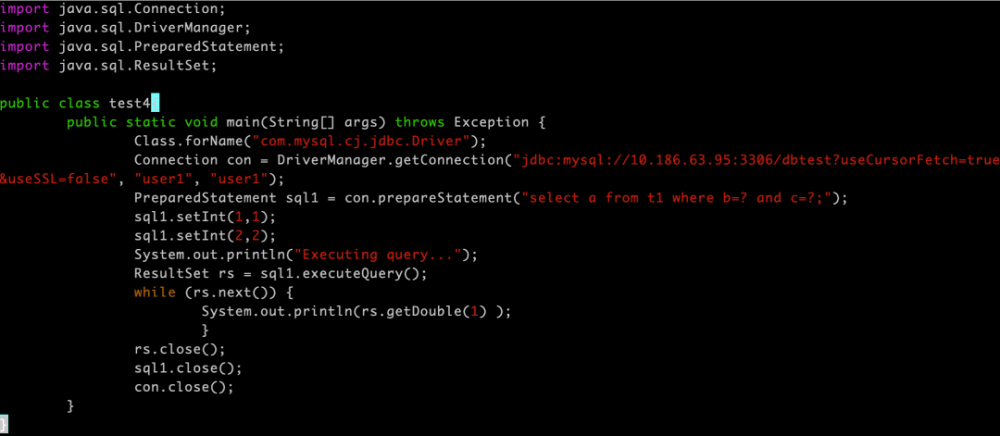
Java通过JDBC连接数据库:1.导入驱动包;2.加载驱动类;3.使用DriverManager.getConnection()方法,传入URL、用户名和
核心依赖与前置条件
1 JDBC架构原理
JDBC本质是Sun公司定义的标准接口规范,通过各厂商提供的驱动程序(Driver)实现具体数据库通信,其四层架构包含:
| 层级 | 作用 | 典型组件 |
|————|———————————————————————-|——————————|
| 应用层 | 调用JDBC API发起请求 | Connection, Statement |
| 驱动管理器 | 动态加载数据库驱动类(Class.forName()) | ServiceLoader机制 |
| 驱动程序 | 将通用API转换为特定数据库协议(如MySQL协议、PostgreSQL协议) | 各厂商实现的xxxDriver.jar |
| 数据库服务 | 最终执行SQL并返回结果 | MySQL/Oracle/SQL Server等 |
2 必备要素清单
JDK版本:需匹配数据库驱动要求的Java版本(如MySQL Connector/J 8.0+支持JDK8及以上)
数据库驱动包:根据目标数据库选择对应JAR文件(例:mysql-connector-java-8.0.33.jar)
数据库服务端:已启动且可网络访问(默认端口:MySQL=3306,PostgreSQL=5432)
权限配置:数据库用户需具备CREATE, SELECT, INSERT等必要权限

标准连接流程详解
1 五步标准操作法
// 1. 加载数据库驱动(新版JDBC可省略此步)
Class.forName("com.mysql.cj.jdbc.Driver"); // 显式注册驱动
// 2. 建立数据库连接(核心参数解析)
String url = "jdbc:mysql://localhost:3306/mydb?useSSL=false&serverTimezone=UTC";
Properties info = new Properties();
info.put("user", "root");
info.put("password", "123456");
Connection conn = DriverManager.getConnection(url, info);
// 3. 创建执行器对象(三种类型对比)
Statement stmt = conn.createStatement(); // 普通语句(存在SQL注入风险)
PreparedStatement pstmt = conn.prepareStatement("SELECT FROM users WHERE id=?"); // 推荐方式
CallableStatement cstmt = conn.prepareCall("{call getUser(?)}"); // 存储过程调用
// 4. 执行SQL并获取结果
ResultSet rs = pstmt.executeQuery(); // 查询操作
int affectedRows = stmt.executeUpdate("UPDATE ..."); // 增删改操作
boolean hasResult = cstmt.execute(); // 存储过程布尔返回值
// 5. 遍历结果集(重要!必须按顺序读取)
while(rs.next()){
String name = rs.getString("username"); // 列名映射
int age = rs.getInt(2); // 列索引映射
}
// 6. 释放资源(严格顺序!)
rs.close();
pstmt.close();
conn.close(); // 最后关闭连接
2 关键参数深度解析
| 参数类型 | 示例值 | 功能说明 |
|---|---|---|
| URL结构 | jdbc:mysql://host:port/db |
协议头+地址+数据库名,附加参数控制行为 |
| 常用参数 | ?useSSL=false |
禁用SSL加密(测试环境可用) |
&serverTimezone=UTC |
解决时区不一致导致的日期转换错误 | |
&characterEncoding=UTF-8 |
确保中文字符正常传输 | |
| 连接池参数 | maximumPoolSize=20 |
商业级应用必配,避免频繁创建连接开销 |
| 超时设置 | socketTimeout=30s |
网络异常时的兜底保护 |
主流数据库适配对照表
| 数据库类型 | 驱动类全名 | 默认端口 | 典型URL格式 | 特殊注意事项 |
|---|---|---|---|---|
| MySQL | com.mysql.cj.jdbc.Driver |
3306 | jdbc:mysql://host:port/db?param=value |
0+版本需添加时区参数 |
| PostgreSQL | org.postgresql.Driver |
5432 | jdbc:postgresql://host:port/db |
自动提交默认为false |
| Oracle | oracle.jdbc.driver.OracleDriver |
1521 | jdbc:oracle:thin:@host:port:SID |
SID需与服务端一致 |
| SQL Server | com.microsoft.sqlserver.jdbc.SQLServerDriver |
1433 | jdbc:sqlserver://host:port;databaseName=db |
需启用TCP/IP协议 |
| DB2 | com.ibm.db2.jcc.DB2Driver |
5000 | jdbc:db2://host:port/db |
区分客户端认证模式 |
工业级最佳实践
1 连接池选型建议
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| HikariCP | 轻量级/高性能/零配置 | 功能相对简单 | Web应用首选 |
| Druid | 监控功能强大/支持SQL防火墙 | JVM内存占用较高 | 复杂业务系统 |
| C3P0 | 历史悠久/社区活跃 | 配置项繁多 | 传统项目维护 |
| Tomcat JNDI | 容器级管理/热部署友好 | 依赖应用服务器 | JavaEE企业级应用 |
2 防错加固策略
️ SQL注入防护:强制使用PreparedStatement,示例:
String sql = "SELECT FROM orders WHERE customer_id = ? AND status = ?"; PreparedStatement pstmt = conn.prepareStatement(sql); pstmt.setLong(1, customerId); // 自动转义特殊字符 pstmt.setString(2, "SHIPPED"); // 字符串参数化
️ 事务控制:显式开启事务保证原子性:
conn.setAutoCommit(false); // 关闭自动提交
try {
// 执行多个操作...
conn.commit(); // 全部成功才提交
} catch (Exception e) {
conn.rollback(); // 出错回滚
throw new RuntimeException(e);
} finally {
conn.setAutoCommit(true); // 恢复默认
}
️ 资源泄露防护:采用try-with-resources语法糖:
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
// 自动关闭资源,无需finally块
} catch (SQLException e) {
// 异常处理
}
完整代码示例(MySQL版)
import java.sql.;
import javax.sql.DataSource;
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
public class JdbcDemo {
private static final String DRIVER_CLASS = "com.mysql.cj.jdbc.Driver";
private static final String DB_URL = "jdbc:mysql://localhost:3306/testdb?useSSL=false&serverTimezone=UTC";
private static final String DB_USER = "dev_user";
private static final String DB_PASSWORD = "securePass123!";
public static void main(String[] args) {
// 方式1:基础单次连接(适合脚本工具类)
basicConnectionExample();
// 方式2:连接池方式(生产环境推荐)
connectionPoolExample();
}
private static void basicConnectionExample() {
try {
Class.forName(DRIVER_CLASS); // Java 6+可省略,但建议保留
try (Connection conn = DriverManager.getConnection(DB_URL, DB_USER, DB_PASSWORD);
PreparedStatement pstmt = conn.prepareStatement(
"SELECT id, name, email FROM users WHERE registration_date > ?")) {
// 设置参数(防止SQL注入)
pstmt.setDate(1, new java.sql.Date(System.currentTimeMillis() 30L 24 60 60 1000));
// 执行查询并处理结果集
try (ResultSet rs = pstmt.executeQuery()) {
while (rs.next()) {
long id = rs.getLong("id");
String name = rs.getString("name");
String email = rs.getString("email");
System.out.printf("ID: %d, Name: %s, Email: %s%n", id, name, email);
}
}
} catch (SQLException e) {
e.printStackTrace();
}
} catch (ClassNotFoundException e) {
System.err.println("找不到JDBC驱动:" + e.getMessage());
}
}
private static void connectionPoolExample() {
// HikariCP配置(生产环境建议外部化配置)
HikariConfig config = new HikariConfig();
config.setJdbcUrl(DB_URL);
config.setUsername(DB_USER);
config.setPassword(DB_PASSWORD);
config.setMaximumPoolSize(10); // 根据CPU核心数调整
config.setConnectionTimeout(30000); // 30秒超时
config.addDataSourceProperty("cachePrepStmts", "true"); // 启用预备语句缓存
config.addDataSourceProperty("prepStmtCacheSize", "250"); // 缓存大小
config.addDataSourceProperty("prepStmtCacheSqlLimit", "2048"); // SQL长度限制
try (DataSource ds = new HikariDataSource(config);
Connection conn = ds.getConnection();
PreparedStatement pstmt = conn.prepareStatement(
"INSERT INTO logs(operation, user_agent) VALUES(?, ?)")) {
pstmt.setString(1, "LOGIN");
pstmt.setString(2, "Mozilla/5.0");
int rowsAffected = pstmt.executeUpdate();
System.out.println("插入日志记录数:" + rowsAffected);
} catch (SQLException e) {
e.printStackTrace();
}
}
}
相关问答FAQs
Q1: 为什么会出现”Communications link failure”错误?
A: 这是最常见的连接异常,主要原因包括:
1️⃣ 网络不通:检查防火墙是否放行数据库端口(如MySQL默认3306),使用telnet host port测试连通性;
2️⃣ 数据库未启动:通过systemctl status mysql(Linux)或服务管理器查看数据库状态;
3️⃣ URL配置错误:确认IP地址、端口号、数据库名称拼写正确;
4️⃣ 驱动不兼容:确保使用的驱动版本与数据库服务端版本匹配(如MySQL 8.0需使用8.0+驱动);
5️⃣ SSL强制验证:若数据库启用了SSL,需在URL中添加useSSL=true并配置证书。
Q2: 如何优化高并发场景下的数据库访问性能?
A: 从以下维度进行优化:
连接池调优:设置合理的maximumPoolSize(通常为CPU核心数×2),启用连接测试(testWhileIdle=true);
批处理操作:使用addBatch()+executeBatch()批量执行相同SQL;
预编译语句复用:通过PreparedStatement的cachePrepStmts=true参数缓存编译后的SQL;
索引优化:对查询条件字段建立索引,避免全表扫描;
分库分表:当单库数据量超过千万级时,采用垂直/水平拆分策略;
读写分离:主库写操作,从库读操作,通过中间件实现负载均衡;
二级缓存:结合Ehcache等缓存框架