上一篇
html如何保存为pdf
可通过浏览器「打印」功能另存为 PDF;或使用 jsPDF 等 JavaScript 库在前端动态生成;也可借助 Python PyPDF2 等后端方案实现
将 HTML 文件保存为 PDF 是一种常见需求,广泛应用于电子文档归档、报告生成、网页快照留存等场景,以下是完整的技术解析与实践指南,涵盖多种主流方案及其适用场景,并附详细操作步骤和注意事项。
核心原理与技术路径
HTML 转 PDF 的本质是将网页渲染引擎(如 Blink/WebKit)解析后的页面内容,通过虚拟打印机或专用转换引擎输出为 PDF 格式,主要技术路径包括:
| 技术类型 | 典型工具/库 | 特点 |
|—————-|—————————|———————————————————————-|
| 浏览器内置功能 | Chrome/Firefox/Edge | 无需安装插件,适合简单需求 |
| 命令行工具 | wkhtmltopdf/Puppeteer | 支持自动化脚本,可定制参数 |
| 编程语言库 | Python(pdfkit/WeasyPrint) | 深度集成开发流程,适合批量处理 |
| 在线转换服务 | SmallPDF/CloudConvert | 跨平台便捷,但需注意隐私风险 |
| 专业软件 | Adobe Acrobat Pro | 高精度排版控制,支持交互式表单 |
主流实施方案详解
方案1:浏览器直接导出(零门槛)
适用场景:单次快速转换、基础需求
操作步骤(以 Chrome 为例):
- 打开目标 HTML 文件(本地文件或在线页面);
- 按
Ctrl+P(Windows)或Cmd+P(Mac)调出打印对话框; - 在「目标」选项中选择「另存为 PDF」;
- 调整边距、缩放比例等参数后点击「保存」。
️ 关键注意事项:
优势:操作简单,保留基本样式;
局限:无法处理动态内容(JavaScript 生成的元素)、复杂 CSS(如背景图丢失)、分页逻辑异常;
技巧:若出现乱码,尝试切换「头部」和「底部」选项卡中的边距设置。
方案2:wkhtmltopdf 命令行工具(开发者首选)
适用场景:自动化任务、服务器端批量转换
安装与使用:

- 下载预编译包:https://wkhtmltopdf.org/downloads.html;
- 命令示例:
wkhtmltopdf input.html output.pdf; - 高级参数配置(常用):
--page-size A4:设置纸张尺寸;--margin-top 10mm:调整页边距;--enable-javascript:启用 JS 渲染;--no-stop-slow-scripts:防止超时中断。
性能对比表:
| 指标 | wkhtmltopdf | 浏览器原生导出 |
|——————–|————-|—————|
| 执行速度 | | |
| CSS 支持度 | | |
| JavaScript 支持 | ️ | |
| 批量处理能力 | ️ | |
| 跨平台兼容性 | ️ | 依赖浏览器环境 |
方案3:Python 库实现(编程集成)
推荐库:pdfkit(基于 wkhtmltopdf)、WeasyPrint(纯 Python 实现)
代码示例(pdfkit):
import pdfkit
options = {
'page-size': 'A4',
'margin-top': '0.75in',
'encoding': 'UTF-8'
}
pdfkit.from_file('input.html', 'output.pdf', options=options)
优势:可嵌入工作流(如 Django/Flask 后端自动生成报表);
缺陷:依赖系统级库,Windows 需额外配置二进制文件路径。
方案4:在线转换工具(应急方案)
代表平台:SmallPDF、ILovePDF、CloudConvert
操作流程:
- 访问网站 → 上传 HTML 文件;
- 选择转换选项(部分支持 ZIP 压缩包);
- 下载生成的 PDF。
️ 风险提示勿上传公共平台!企业级建议使用私有云部署方案。
高级优化技巧
解决样式错位问题
| 问题现象 | 解决方案 |
|---|---|
| 背景图消失 | 确保 CSS 中 background-attachment: scroll; 或改用 <img> 标签嵌套 |
| 表格跨页断裂 | 添加 page-break-inside: avoid; 到 <table> 样式 |
| 字体替换 | 嵌入 WebFont(@font-face)或改用系统默认字体 |
| 浮动元素错位 | 强制换行:position: static; display: block; |
捕获
对于依赖 JavaScript 加载的内容(如图表、评论框):
- 使用 Headless Chrome + Puppeteer 模拟完整渲染;
- 示例代码片段:
const puppeteer = require('puppeteer'); (async () => { const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto('file://' + __dirname + '/input.html', {waitUntil: 'networkidle2'}); await page.pdf({path: 'output.pdf', format: 'A4'}); await browser.close(); })();
分页控制策略
- CSS 强制分页:
@media print { .page-break { page-break-before: always; } }; - JavaScript 干预:监听
window.matchMedia("print")事件动态调整布局。
常见问题排查手册
Q1: 生成的 PDF 缺少部分内容怎么办?
诊断步骤:
- 检查控制台是否有报错(F12 → Console);
- 确认是否禁用了广告拦截插件;
- 尝试简化 HTML 结构定位冲突元素;
- 使用
--debug-javascript参数查看 JS 错误日志。
Q2: 中文字符显示为方框如何解决?
根本原因:未嵌入中文字体或编码错误。
解决方案:
- 指定字体文件路径:
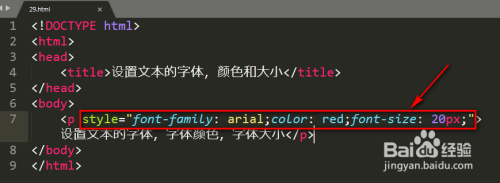
@font-face { font-family: "SimSun"; src: url("simsun.ttf"); }; - 确保 HTML 声明正确编码:
<meta charset="UTF-8">; - 命令行添加参数:
--encoding utf-8。
相关问答 FAQs
Q: 如何将整个网站目录批量转换为 PDF?
A:推荐使用 Python 脚本递归处理文件夹:
import os
import pdfkit
from jinja2 import Environment, FileSystemLoader
env = Environment(loader=FileSystemLoader('templates'))
for filename in os.listdir('html_files'):
if filename.endswith('.html'):
template = env.get_template(filename)
html_out = template.render(data={'title': filename})
pdfkit.from_string(html_out, f'output/{filename[:-5]}.pdf')
此方案可结合模板引擎实现动态内容注入。
Q: 转换后的 PDF 文件过大怎么处理?
A:优化方向及实施方法:
| 优化层级 | 具体措施 | 预期效果 |
|—————-|————————————————————————–|——————————|
| 图片压缩 | 替换高清图为 WebP/AVIF 格式,设置 max-width: 100%; height: auto; | 文件大小减少 30%-70% |
| CSS 精简 | 移除未使用的 CSS 规则,合并重复样式 | 提升渲染效率 |
| 字体子集化 | 仅嵌入文档中使用的 Unicode 字符区间 | 字体文件缩小 50%+ |
| 矢量图优化 | SVG 转 PNG 时降低 DPI,禁用透明通道 | 视觉损失最小化 |
| 压缩算法 | 使用 FlateCompression (Zstandard) 替代传统 DEFLATE | 二次压缩率提升 15%-25%