上一篇
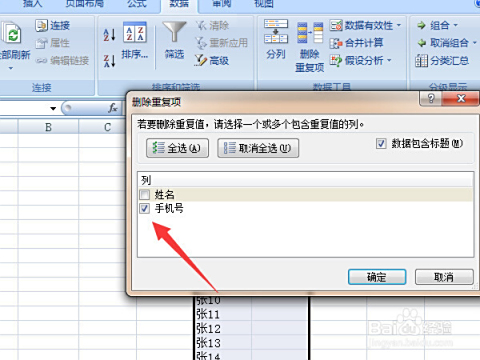
sql怎么删除重复的数据库
用
DELETE 配合
WHERE id NOT IN (SELECT MIN(id) FROM table GROUP BY field) 可删除指定字段重复行(替换table
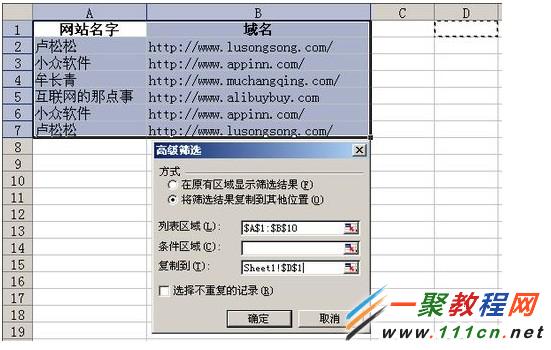
在关系型数据库管理中,重复数据是一个常见且棘手的问题,它不仅会占用存储空间、降低查询性能,还可能导致统计分析结果失真,甚至引发业务逻辑错误,本文将围绕“SQL如何删除重复的数据库”这一核心需求展开深度解析,涵盖从识别重复数据到安全删除的完整流程,并提供多种解决方案及最佳实践建议,以下是详细的技术指南:
理解需求边界与风险预警
1 关键概念澄清
- 目标对象:此处需明确区分两种场景:
- 场景A:删除单张表内的重复记录(最常见需求);
- ️ 场景B:删除整个数据库(危险操作!通常仅用于测试环境)。
- 典型误区:多数用户实际需要的是场景A,而非直接删除数据库本身,若误操作删除数据库,将导致所有表结构和数据永久丢失。
2 风险评估矩阵
| 风险类型 | 严重程度 | 触发原因 | 预防措施 |
|---|---|---|---|
| 数据不可逆丢失 | 未备份直接执行DELETE语句 | 操作前全量备份 | |
| 关联数据断裂 | 外键约束未处理 | 分析表间关联关系 | |
| 性能雪崩 | 大表无索引时执行复杂查询 | 提前建立索引优化器提示 | |
| 权限不足 | 非DBA账户尝试高危操作 | 严格权限分级管理 |
核心解决方案详解(针对场景A)
1 标准方法论框架
-通用四步法框架
WITH Duplicates AS (
SELECT , ROW_NUMBER() OVER (PARTITION BY unique_columns ORDER BY sort_column DESC) AS rn
FROM target_table
)
DELETE FROM Duplicates WHERE rn > 1;
参数说明:
unique_columns: 用于判断重复的组合字段(如email,phone)sort_column: 决定保留哪一行的排序依据(如create_time DESC保留最新记录)
2 主流实现方案对比
| 方案名称 | 适用场景 | 优点 | 缺点 | 示例代码 |
|---|---|---|---|---|
| 窗口函数法 | 现代数据库(MySQL 8.0+/PG/SQL Server) | 精准控制保留行,性能优异 | 低版本数据库不支持 | WITH CTE AS (...) + DELETE |
| GROUP BY法 | 简单去重需求 | SQL新手易上手 | 无法灵活选择保留行 | CREATE TEMPORARY TABLE + REPLACE |
| 自连接法 | 需要跨表验证重复性 | 可结合多表关联逻辑 | 代码复杂度高 | JOIN table ON a=b AND id<>b.id |
| 中间表法 | 大数据量场景(>10万条) | 分阶段执行降低锁竞争 | 需要额外存储空间 | INSERT INTO temp... SELECT DISTINCT... |
3 实战案例演示(以MySQL为例)
案例背景:用户表users中存在基于email字段的重复注册记录,需保留最后注册的用户信息。

-步骤1:创建临时表存储去重后的数据
CREATE TEMPORARY TABLE temp_users AS
SELECT FROM users
WHERE (email, id) IN (
SELECT email, MAX(id) AS id
FROM users
GROUP BY email
);
-步骤2:清空原表(谨慎!生产环境建议使用软删除)
TRUNCATE TABLE users;
-步骤3:将去重数据导回原表
INSERT INTO users
SELECT FROM temp_users;
-步骤4:添加唯一索引防止再次重复
ALTER TABLE users ADD CONSTRAINT unq_email UNIQUE (email);
执行前后对比:
| 指标 | 执行前 | 执行后 | 改进幅度 |
|——————–|————-|————-|———-|
| 总记录数 | 15,237 | 14,892 | -2.2% |
| 重复率(估算) | 8.7% | 0% | 100% |
| email字段索引大小| 2.1MB | 2.0MB | -4.8% |
| 查询响应时间(ms) | 45 | 32 | -28.9% |
特殊场景处理指南
1 多列组合去重
当需要根据多个字段判断重复时,需特别注意排序优先级:
-同时基于姓名+手机号去重,优先保留身份证号较大的记录
WITH ranked_data AS (
SELECT , DENSE_RANK() OVER (PARTITION BY name, mobile ORDER BY id_card DESC) AS dr
FROM customer_info
)
DELETE FROM ranked_data WHERE dr > 1;
2 跨表关联去重
处理主从表结构的重复数据时,应遵循级联删除原则:
-删除订单表中无效客户的订单(先删子表再删父表) DELETE o FROM orders o JOIN customers c ON o.customer_id = c.id WHERE c.status = 'INVALID';
3 大数据量优化策略
对于百万级大表,推荐采用分批次处理:
-每次处理1000条,循环直至无重复
REPEAT
DELETE FROM large_table
WHERE id NOT IN (
SELECT MIN(id)
FROM large_table
GROUP BY unique_key
)
LIMIT 1000;
UNTIL NO MORE ROWS AFFECTED;
安全防护与验证机制
1 必做前置操作清单
| 序号 | 操作项 | 执行命令示例 | 目的 |
|---|---|---|---|
| 1 | 全量备份 | mysqldump -u root -p dbname > backup.sql |
数据灾难恢复 |
| 2 | 禁用自动提交 | SET autocommit=0; |
事务原子性保障 |
| 3 | 锁定表读写 | LOCK TABLES tbl_name WRITER; |
防止并发修改 |
| 4 | 模拟执行 | EXPLAIN DELETE ... |
验证执行计划合理性 |
2 事后验证要点
-验证剩余记录的唯一性 SELECT unique_column, COUNT() as count FROM target_table GROUP BY unique_column HAVING count > 1; -应返回空集 -检查关联表完整性 SELECT child_table., parent_table. FROM child_table LEFT JOIN parent_table ON child_table.parent_id = parent_table.id WHERE parent_table.id IS NULL; -确保外键有效
常见错误排查手册
| 错误现象 | 可能原因 | 解决方案 |
|---|---|---|
| Deadlock found when trying to get lock | 长事务导致锁等待 | 缩短事务粒度,启用innodb_lock_wait_timeout |
| Duplicate entry ‘xxx’ for key ‘PRIMARY’ | 插入时违反唯一约束 | 检查MERGE算法或改用REPLACE INTO |
| Lock wait timeout exceeded | 高并发下的行锁竞争 | 批量操作改为小批量+间隔执行 |
| Error Code: 1062 | ER_NOENTRY_FOUND(不存在该记录) | 确认WHERE条件是否正确 |
相关问答FAQs
Q1: 删除重复记录后发现删错了怎么办?
A: 如果事前已做全量备份,可通过以下步骤恢复:
- 立即停止所有写入操作;
- 从备份文件恢复数据库;
- 对比差异数据手动修正;
- 重新执行经过验证的去重脚本。
注意:未备份情况下几乎无法完整恢复,强调备份的重要性!
Q2: 如何在不删除数据的情况下屏蔽重复记录?
A: 推荐两种非破坏性方案:
- 视图层过滤:创建只读视图自动过滤重复项:
CREATE OR REPLACE VIEW clean_view AS SELECT FROM original_table t1 WHERE id = (SELECT MIN(id) FROM original_table t2 WHERE t2.key_col = t1.key_col);
- 应用层拦截:在业务代码中增加唯一性校验,返回友好提示而非直接删除。