上一篇
怎么学java内存
学习Java内存需掌握JVM体系结构,重点研究堆、栈、方法区等区域,结合GC原理与性能监控工具实践,推荐《
学习Java内存管理是掌握高性能编程的关键技能之一,以下从底层原理、核心组件、实践技巧、调试方法四个维度展开系统化学习路径,并附实战场景分析和典型问题解决方案。
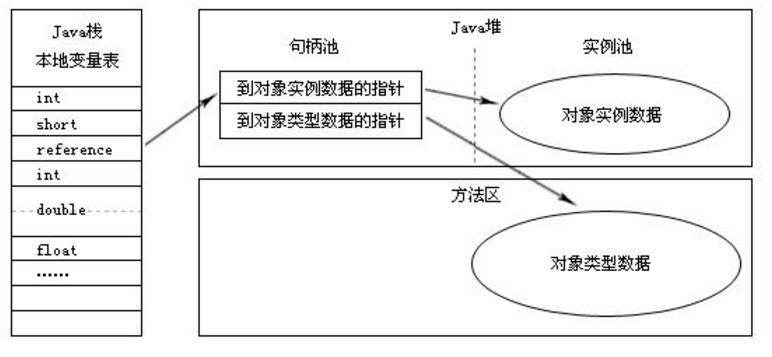
建立认知框架:Java内存模型全景图
JVM运行时数据区划分
| 内存区域 | 作用 | 特点 | 典型异常表现 |
|---|---|---|---|
| 程序计数器 | 记录当前线程执行字节码的位置 | 唯一无OOM风险的区域 | |
| 虚拟机栈 | 存储方法调用时的局部变量表、操作数栈、动态链接等信息 | 线程私有,支持固定大小的栈帧 | StackOverflowError |
| 本地方法栈 | Native方法执行时的内存空间 | 受本地操作系统约束 | |
| 堆 | 存放所有对象实例及数组 | GC主战场,分为新生代/老年代/永久代 | OutOfMemoryError |
| 方法区 | 存储类信息、常量、静态变量(JDK8前称PermGen,现为Metaspace) | 线程共享,GC可回收 | OutOfMemoryError |
| 运行时常量池 | 字面量池+符号引用 | 属于方法区的一部分 | |
| 直接内存 | NIO操作通过Unsafe分配的内存空间 | 不受JVM堆限制,需手动控制释放 | OutOfMemoryError |
关键概念澄清
自动装箱/拆箱:Integer i = 10;实际创建了两个对象(基本类型→包装类),频繁操作会导致额外内存开销
逃逸分析:编译器能识别未逃逸的对象,将其分配在栈上而非堆中(开启-XX:+DoEscapeAnalysis)
TLAB(Thread Local Allocation Block):每个线程独有的分配缓冲区,减少并发竞争
深度解析核心组件
堆内存精细化管理
| 分区 | 默认比例 | 存储对象特征 | GC策略 | 存活周期 |
|---|---|---|---|---|
| Eden区 | 8:1:1中的8份 | 新生成对象 | Minor GC(复制算法) | <15次GC |
| Survivor区 | 8:1:1中的1份 | 经一次Minor GC存活的对象 | From Eden→Survivor→Old | ~15次GC |
| Old区 | 动态扩展 | 长期存活对象/大对象 | Major GC(标记-清除/整理) | 长期存在 |
| Metaspace | 无固定上限 | 类元信息、常量池 | Class Unloading | 随应用生命周期 |
实践要点:

- 通过
-Xms/-Xmx设置初始/最大堆大小,建议设置为物理内存的1/4~1/2 - 使用
jmap -heap查看实时堆使用情况 - 调整
-XX:NewRatio改变新旧生代比例(适用于大量短命对象的业务场景)
垃圾回收器选型指南
| GC类型 | 适用场景 | 优点 | 缺点 | 参数示例 |
|---|---|---|---|---|
| Serial | 客户端模式/单核CPU | 低延迟,简单高效 | 单线程处理 | -XX:+UseSerialGC |
| ParNew | 配合CMS使用 | 多线程并行回收Eden+Survivor | 仍需Stop-The-World | -XX:+UseParNewGC |
| Parallel Scavenge | 吞吐量优先场景 | 多线程并行度高 | 响应时间不稳定 | -XX:+UseParallelGC |
| CMS | 低延迟要求场景(如Web服务) | 并发标记清除,减少停顿 | 浮动垃圾较多,可能触发Full GC | -XX:+UseConcMarkSweepGC |
| G1 | 混合型应用(兼顾延迟和吞吐量) | 可预测停顿时间(<200ms) | 需要较大堆内存 | -XX:+UseG1GC |
| ZGC/Shenandoah | 超大堆内存(>4T) | 超低延迟(<10ms) | 依赖CPU特性,硬件要求高 | -XX:+UseZGC/-XX:+UseShenandoahGC |
配置示例:
# G1垃圾收集器推荐配置 java -Xms4g -Xmx4g -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:InitiatingHeapOccupancyPercent=45 ...
栈内存优化策略
- 递归深度控制:单个线程栈默认1MB,可通过
-Xss调整(最大不超过系统限制) - 局部变量作用域:及时将不再使用的局部变量置为null,加速GC
- 逃逸分析验证:编译时添加
-XX:+PrintCompilation观察是否发生栈上分配 - 线程池大小:每个线程默认占用1MB栈空间,过大线程池会导致交换分区压力
实战场景与性能调优
内存泄漏排查流程
- 定位阶段:
- 使用
jvisualvm监控堆增长趋势 - 执行
jmap -dump:format=b,file=heapdump.bin <pid>生成堆转储文件 - 用MAT(Memory Analyzer Tool)分析支配树(Dominator Tree)
- 使用
- 根因分析:
- 检查是否存在长生命周期对象持有短生命周期对象引用(如静态集合缓存)
- 确认第三方库是否关闭资源(如数据库连接池、IO流)
- 验证单例模式实现是否正确(双重校验锁需加volatile)
- 修复方案:
- 改用弱引用/软引用(
WeakReference/SoftReference) - 显式调用
System.gc()测试(仅用于验证,生产环境慎用) - 重构代码消除循环引用
- 改用弱引用/软引用(
大对象处理技巧
- 避免频繁创建大对象:使用对象池复用技术(如Apache Commons Pool)
- 分段处理大数据:将大集合拆分为多个小块处理
- 启用HUGE_PAGES:对Linux系统配置大页内存提升性能
# 查看大页内存状态 cat /proc/meminfo | grep HugePages_Total # 分配大页内存给JVM java -XX:+UseLargePages -XX:LargePageSizeInBytes=2M ...
堆外内存管理
- DirectByteBuffer使用规范:
- 必须手动调用
cleaner().clean()释放资源 - 避免跨进程共享时的内存拷贝开销
- 必须手动调用
- Netty内存分配优化:
- 根据业务特点选择PooledAllocator或UnpooledAllocator
- 调整
maxOrder参数控制内存块大小层级
高级工具链应用
| 工具名称 | 功能 | 常用命令示例 |
|---|---|---|
| jstat | JVM统计信息采集 | jstat -gcutil <pid> 1000 |
| jmap | 生成堆转储/查看对象实例数 | jmap -histo <pid> |
| jconsole | JMX可视化监控 | 连接localhost:<rmi_port> |
| VisualVM | 集成式性能分析 | 插件安装后自动关联目标JVM |
| Arthas | 在线诊断无需重启应用 | curl -L arthas-boot.jar | java -jar arthas-boot.jar |
| YourKit Java Profiler | CPU/内存火焰图分析 | 附加到运行中的JVM进程 |
常见误区与解决方案
误区1:认为所有对象都会被立即回收
真相:对象只有在成为垃圾(不可达)后才会被回收,强引用对象永远不会被回收。
解决方案:对不再需要的大对象显式设为null,打破引用链。
误区2:过度依赖System.gc()
真相:JVM的GC策略比手动触发更高效,强制GC反而可能增加停顿时间。
解决方案:仅在调试时使用,生产环境应信任JVM的自适应机制。
误区3:忽略本地变量表的大小
真相:每个方法调用都会创建包含局部变量的栈帧,复杂递归可能导致栈溢出。
解决方案:简化递归逻辑,必要时改为迭代实现。
相关问答FAQs
Q1: 为什么明明设置了足够的堆内存,仍然报OutOfMemoryError?
A: 可能原因包括:① 堆外内存(DirectMemory)耗尽;② 元空间(Metaspace)不足;③ 线程数过多导致栈内存溢出,解决方法:① 使用-XX:MaxDirectMemorySize限制直接内存;② 添加-XX:MaxMetaspaceSize参数;③ 通过jstack分析线程栈使用情况。
Q2: G1垃圾收集器相比CMS有什么优势?
A: G1采用基于Region的堆结构,将堆划分为多个大小相等的区域,通过预测停顿时间目标(MaxGCPauseMillis)动态调整GC频率,相比CMS的并发标记-清除算法,G1具有以下优势:① 可预测的停顿时间;② 更好的内存碎片率控制;③ 支持并行全量GC;④ 更适合现代多核服务器环境,但需要注意G1对堆大小的最低要求(通常