上一篇
如何使html不成乱码
HTML文件编码正确,使用UTF-8编码,并在头部
以下是关于如何使HTML不成乱码的详细方法:
设置正确的字符编码
-
选择UTF-8编码:UTF-8是一种通用且兼容性强的编码方式,能涵盖几乎所有语言的字符,在创建HTML文件时,优先使用UTF-8编码保存文件,大多数文本编辑器如Notepad++、Sublime Text等,都允许在保存文件时选择编码格式,确保选择UTF-8。
-
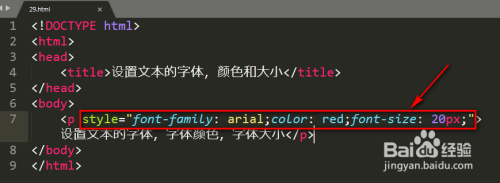
添加meta标签声明编码:在HTML文档的头部区域添加meta标签来指定字符编码,明确告诉浏览器如何解析页面内容,使用 可声明页面采用UTF-8编码,这样浏览器就能正确显示字符。
检查服务器配置
-
Apache服务器:如果在Apache服务器上部署HTML页面,需检查并设置正确的字符编码,可以在Apache的配置文件(如httpd.conf)中添加AddDefaultCharset UTF-8,以确保服务器向浏览器发送的页面内容以UTF-8编码进行传输。

-
Nginx服务器:对于Nginx服务器,可在配置文件(如nginx.conf)的server块中添加charset utf-8;来设置默认的字符编码为UTF-8。
排查BOM和FTP传输模式
-
避免使用BOM:有些文本编辑器在保存文件时会自动添加字节顺序标记(BOM),这可能导致浏览器解析出现问题,进而出现乱码,在保存HTML文件时,尽量选择不使用BOM的保存选项。
-
设置FTP为二进制模式:如果通过FTP上传HTML文件到服务器,要确保FTP客户端设置为二进制模式,因为ASCII模式可能会对文件内容进行转换,从而导致乱码,而二进制模式则会原封不动地传输文件内容,保证文件的完整性和正确性。
其他注意事项
-
检查浏览器编码设置:虽然HTML文件中已声明编码,但有时浏览器的默认编码设置可能与页面编码不一致,导致乱码,在这种情况下,可手动在浏览器中调整编码设置,使其与HTML页面的编码相匹配。
-
统一编码处理混编字符:如果HTML页面中包含了多种语言或不同编码的字符,需要确保所有字符都采用统一的编码进行处理,避免因编码不一致而出现乱码,对于一些特殊字符,可以使用HTML实体来表示,以确保在不同编码环境下都能正确显示。
相关问答FAQs
问:为什么HTML页面会出现乱码?
答:HTML页面出现乱码的原因主要有以下几点:一是文件本身的编码与浏览器解析时使用的编码不一致,比如文件是GBK编码,但浏览器按UTF-8编码来解析;二是服务器配置的字符编码与页面实际编码不符;三是在文件传输过程中,如通过FTP上传时选择了错误的传输模式,导致文件内容被错误转换;四是页面中混用了不同编码的字符,且未进行统一处理。
问:除了UTF-8,还有哪些常见的字符编码?
答:除了UTF-8外,常见的字符编码还有GBK、GB2312、BIG5等,GBK是国标扩展字符集,是在GB2312基础上扩展而来,兼容GB2312,主要用于简体中文环境;GB2312是国标简体中文字符集,收录了常用的简体中文汉字;BIG5则主要用于繁体中文环境,收录了繁体中文汉字以及一些日文和韩文字符等。