上一篇
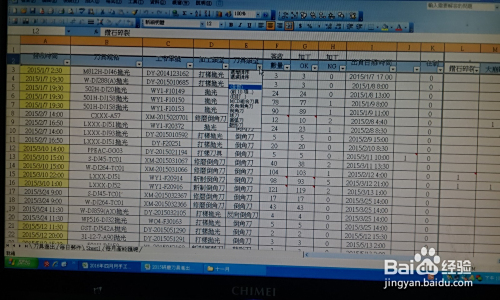
怎么筛选两个表格重复的数据库
过对比两表数据,将相同字段内容一致的记录筛选出来即为重复
处理数据库时,筛选两个表格中重复的数据是一个常见的需求,无论是为了数据清洗、去重还是进行数据分析,掌握有效的方法来识别和提取重复记录都是非常重要的,下面将详细介绍几种常用的方法和步骤,帮助你高效地完成这一任务。
理解问题背景
假设我们有两个表格(或称为数据集),它们可能包含相似的结构,比如相同的字段名,但数据内容有所不同,我们的目标是找出这两个表格中完全相同的记录,即那些在所有关键字段上都一致的数据行,这些重复的记录可能是由于数据录入错误、系统同步问题或其他原因造成的。
准备工作
- 确认字段匹配:确保两个表格中的字段是对应的,如果一个表格有“姓名”、“年龄”和“地址”,另一个表格也应该有相同的字段,以便进行比较。
- 数据类型一致性:检查每个字段的数据类型是否一致,比如都是文本、数字或日期格式。
- 清理数据:去除空格、统一大小写、处理缺失值等,以确保比较的准确性。
使用SQL查询筛选重复数据
如果你使用的是关系型数据库(如MySQL、PostgreSQL等),可以利用SQL语句来查找重复的记录,以下是一个基本的示例:

SELECT a. FROM table1 a INNER JOIN table2 b ON a.id = b.id AND a.name = b.name AND a.age = b.age
这个查询会返回两个表格中id、name和name都相同的记录,你可以根据实际需要调整连接条件,比如只比较特定的几个字段。
使用Excel或Google Sheets进行筛选
对于小型数据集,或者不熟悉SQL的用户,可以使用电子表格软件如Excel或Google Sheets来手动筛选重复项。
- 合并表格:将两个表格的数据复制到同一个工作表中,但放在不同的列旁。
- 添加辅助列:创建一个辅助列,用于标记是否存在于另一个表格中,使用
VLOOKUP函数检查第一个表格中的记录是否出现在第二个表格里。 - 筛选重复项:基于辅助列的值,筛选出标记为存在的记录,即为重复项。
使用Python进行数据处理
对于更复杂的场景或更大的数据集,可以使用编程语言如Python结合Pandas库来处理,以下是一个简单的例子:
import pandas as pd
# 读取两个表格
df1 = pd.read_csv('table1.csv')
df2 = pd.read_csv('table2.csv')
# 找出重复的记录
duplicates = pd.merge(df1, df2, on=['id', 'name', 'age'])
# 查看结果
print(duplicates)
这段代码首先加载了两个CSV文件,然后通过指定的关键字段(这里是id、name和age)进行合并,最终得到的duplicatesDataFrame包含了两个表格中共有的记录。
注意事项
- 性能考虑:当处理非常大的数据集时,应考虑查询效率和资源消耗,优化SQL查询、合理索引以及分批处理都是提高性能的有效手段。
- 数据隐私:在处理敏感信息时,确保遵守相关的数据保护法规,避免泄露个人隐私。
- 自动化流程:对于定期需要执行的任务,可以考虑编写脚本或使用ETL工具自动化整个过程,减少人工干预。
筛选两个表格中的重复数据是一个涉及多个步骤的过程,包括前期的数据准备、选择合适的工具和方法、执行具体的操作以及后期的结果验证,根据数据的规模、来源和个人熟悉程度的不同,可以选择最适合自己情况的方法,无论是使用SQL、电子表格软件还是编程语言,关键在于准确定义什么是“重复”,并确保比较的过程中数据的一致性和完整性,希望以上介绍能帮助你有效地解决这一问题。
FAQs
Q1: 如果两个表格的字段不完全匹配怎么办?
A1: 如果字段不完全一致,你需要先确定哪些字段是用于匹配的关键字段,只对这些关键字段进行比较即可,如果有必要,还可以对非关键字段进行部分匹配或忽略不计,也可以在比较之前对数据进行预处理,例如填充缺失值、转换数据类型等,以提高匹配的准确性。
Q2: 如何处理大量数据时的筛选效率问题?
A2: 当面对大规模数据时,提升筛选效率的关键在于优化查询方式和利用适当的技术手段,对于SQL查询,确保相关字段已经建立了索引,这可以显著加快查找速度,在编写SQL语句时,尽量避免全表扫描,而是利用JOIN操作基于索引进行快速匹配,如果是使用Python等编程语言处理,可以考虑分批次读取和处理数据,或者利用多线程/多进程来并行处理数据,选择高效的算法和数据结构也非常重要,例如使用哈希表来存储其中一个表格的内容,然后在另一个表格中进行查找,这样可以将时间复杂度从O(n^2)降低到接近O(n)。