上一篇
数据库表如何逐步添加?
设计表结构后,使用
CREATE TABLE语句定义字段和约束,执行该语句即可在数据库中创建新表,成功后需验证表结构和约束是否符合预期。
好的,这是一篇面向网站访客、详细解释“数据库表怎么依次加”的文章,注重实用性、专业性(E-A-T)和搜索引擎友好性:
理解“依次加”的含义
“数据库表怎么依次加”这个表述可能包含两层常见含义:
- 依次创建多个新表: 在数据库中按顺序创建多个新的、结构不同的表。
- 向已有表依次添加字段: 在一个已经存在的数据库表中,按顺序添加多个新的列(字段)。
这两种操作虽然都涉及“添加”,但目的和操作方式不同,下面将分别详细说明这两种场景下的“依次加”操作步骤和注意事项。
核心原则:安全与规划
无论进行哪种“依次加”操作,安全性和事前规划都是重中之重:
- 备份!备份!备份! 在进行任何数据库结构更改(DDL操作)之前,务必对数据库进行完整备份,这是防止操作失误导致数据丢失的最后防线。
- 明确目的: 清楚知道为什么要添加表或字段,它们将存储什么数据?如何与其他表关联?避免创建冗余或无用的结构。
- 设计先行: 对于创建新表,需要仔细设计表结构(字段名、数据类型、约束如主键、外键、唯一性、非空等),对于添加字段,要明确其数据类型、长度、是否允许为空、默认值等。
- 测试环境: 强烈建议先在测试环境或开发环境中执行操作,验证无误后再应用到生产环境。
- 选择合适时机: 数据库结构变更(尤其是添加字段到大型表)可能会锁表,影响线上服务,尽量在业务低峰期或维护窗口进行操作。
- 权限: 确保执行操作的用户账户拥有足够的数据库权限(通常是
CREATE TABLE,ALTER TABLE权限)。
依次创建多个新表

这通常发生在初始化数据库结构或增加新的功能模块时。
操作步骤:
-
设计与规划:
- 确定需要创建哪些表。
- 明确每个表的用途和存储的数据。
- 设计每个表的详细结构:
- 字段名 (Column Name): 清晰、有意义,遵循命名规范(如
user_id,order_date)。 - 数据类型 (Data Type): 选择最合适的数据类型(如
INT,VARCHAR(255),DATE,DECIMAL(10,2),TEXT)。 - 约束 (Constraints):
PRIMARY KEY: 唯一标识表中每行记录的主键(通常一个表一个)。FOREIGN KEY: 定义与其他表的关系,确保数据引用完整性。UNIQUE: 确保字段值在表中唯一(可空)。NOT NULL: 确保字段必须有值,不能为空。DEFAULT: 为字段指定默认值(当插入数据未指定该字段值时使用)。CHECK: 定义字段值必须满足的条件(如age > 0)。
- 字段名 (Column Name): 清晰、有意义,遵循命名规范(如
- 确定表间关系: 明确哪些表之间需要通过外键关联,以及关联的方式(一对一、一对多、多对多)。
- 考虑索引: 对经常用于查询条件(WHERE)、连接(JOIN)或排序(ORDER BY)的字段,考虑创建索引以提高查询性能(通常在表创建后单独添加)。
-
编写 SQL 语句:
- 使用
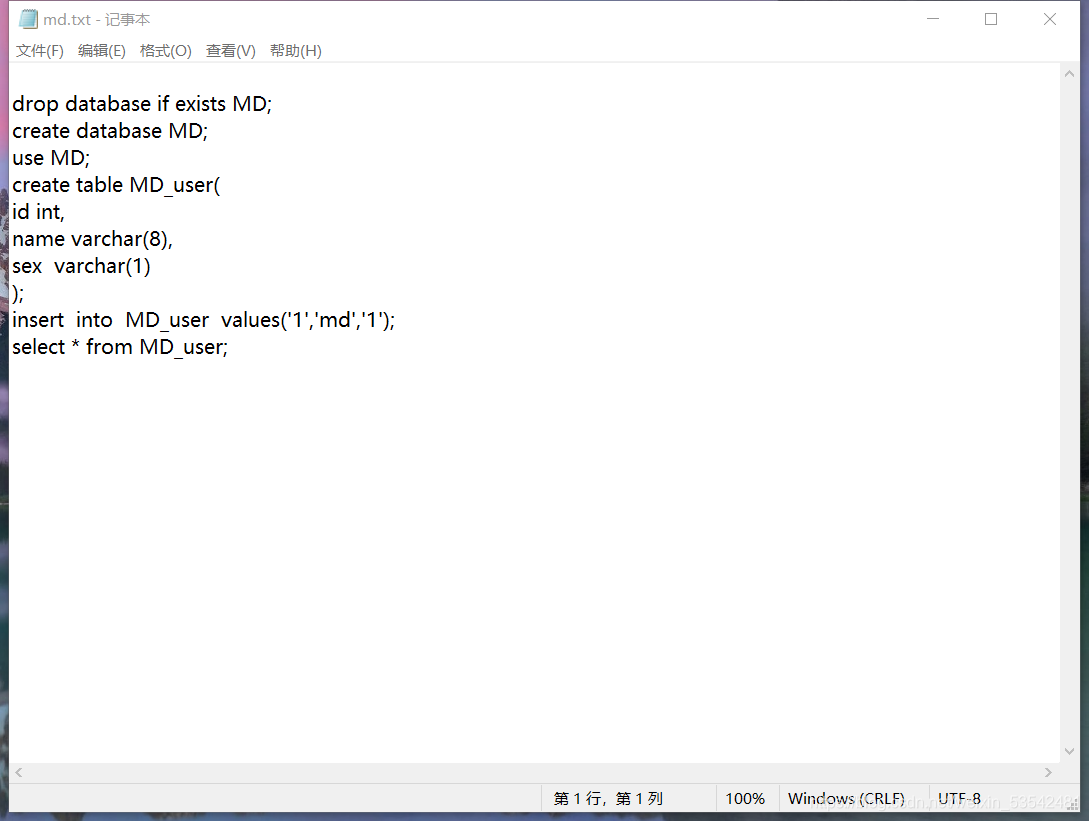
CREATE TABLE语句为每个表编写创建脚本。 - 基本语法:
CREATE TABLE table_name ( column1 datatype [constraints], column2 datatype [constraints], column3 datatype [constraints], ... [table_constraints] -- 如 PRIMARY KEY (column), FOREIGN KEY (column) REFERENCES other_table(column) ); - “依次”执行: 将设计好的多个
CREATE TABLE语句,按照依赖关系(被引用的表需要先创建)或逻辑顺序,在数据库客户端工具(如 MySQL Workbench, pgAdmin, SQL Server Management Studio, DBeaver)或命令行中依次执行。- 示例(简化):
-- 先创建 'users' 表 (被引用) CREATE TABLE users ( user_id INT PRIMARY KEY AUTO_INCREMENT, username VARCHAR(50) NOT NULL UNIQUE, email VARCHAR(100) NOT NULL UNIQUE, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ); -- 再创建 'orders' 表 (引用 users 表) CREATE TABLE orders ( order_id INT PRIMARY KEY AUTO_INCREMENT, user_id INT NOT NULL, order_date DATE NOT NULL, total_amount DECIMAL(10,2) NOT NULL, FOREIGN KEY (user_id) REFERENCES users(user_id) -- 外键约束,依赖于 users 表先存在 ); -- 接着创建 'order_items' 表 (引用 orders 表) CREATE TABLE order_items ( item_id INT PRIMARY KEY AUTO_INCREMENT, order_id INT NOT NULL, product_id INT NOT NULL, -- 假设 products 表已存在或接下来创建 quantity INT NOT NULL CHECK (quantity > 0), price DECIMAL(10,2) NOT NULL, FOREIGN KEY (order_id) REFERENCES orders(order_id) );
- 示例(简化):
- 使用
-
执行与验证:
- 在测试环境依次执行这些 SQL 脚本。
- 使用
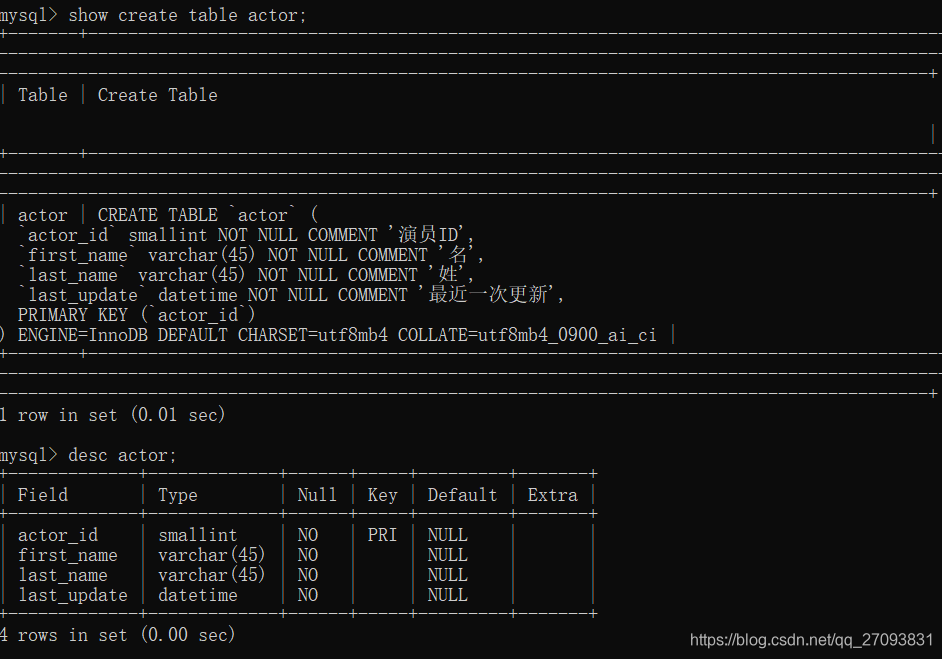
DESCRIBE table_name;(MySQL) 或sp_columns table_name;(SQL Server) 或d table_name(PostgreSQL) 等命令检查表结构是否与设计一致。 - 尝试插入一些测试数据,验证约束(如外键、唯一性)是否生效。
- 检查表关系是否正确建立。
向已有表依次添加多个新字段
这通常是为了扩展已有表的功能,存储新的业务数据。
操作步骤:
-
分析与规划:
- 明确需要向哪个表添加字段。
- 确定需要添加哪些字段。
- 为每个新字段设计:
- 字段名: 清晰、有意义,不与现有字段冲突。
- 数据类型: 选择最合适的数据类型。
- 约束:
NOT NULL,UNIQUE,DEFAULT等。特别注意: 添加NOT NULL约束且没有DEFAULT值时,需要谨慎,因为表中已有数据在该新字段上都是NULL,会导致添加失败,通常先添加为允许NULL,填充数据后再修改为NOT NULL。 - 位置: 新字段默认添加到表结构的末尾,如果需要指定位置(如放在某个字段之后),SQL 语法可能支持(如 MySQL 的
AFTER existing_column),但这并非所有数据库都强制需要,通常不影响逻辑。
-
编写 SQL 语句:
- 使用
ALTER TABLE ... ADD COLUMN语句为每个新字段编写添加脚本。 - 基本语法:
ALTER TABLE table_name ADD COLUMN new_column_name datatype [constraints] [AFTER existing_column]; -- [AFTER ...] 可选,指定位置
- “依次”执行: 将设计好的多个
ALTER TABLE ... ADD COLUMN语句,在数据库客户端工具或命令行中依次执行。- 示例:
-- 向 'products' 表添加字段 -- 先添加 'weight' 字段 (允许为空) ALTER TABLE products ADD COLUMN weight DECIMAL(6,2) NULL COMMENT '产品重量(千克)'; -- 再添加 'is_available' 字段 (不允许空,默认值 true) ALTER TABLE products ADD COLUMN is_available BOOLEAN NOT NULL DEFAULT TRUE COMMENT '产品是否可用'; -- 接着添加 'launch_date' 字段 (允许为空) ALTER TABLE products ADD COLUMN launch_date DATE NULL COMMENT '产品上市日期';
- 示例:
- 使用
-
执行与验证:
- 在测试环境依次执行这些 SQL 脚本。
- 再次使用查看表结构的命令 (
DESCRIBE,sp_columns,d),确认新字段已按预期添加,数据类型和约束设置正确。 - 对于添加了
DEFAULT值的字段,检查现有数据行是否被正确赋予了默认值。 - 对于允许
NULL的字段,插入或更新数据测试NULL值是否被接受。 - 对于
NOT NULL且有DEFAULT的字段,插入数据时不指定该字段,检查默认值是否生效。 - 考虑数据迁移: 如果新字段需要从其他来源填充已有数据,编写数据迁移脚本(
UPDATE语句)并在测试环境验证。
关键注意事项与最佳实践 (适用于两种场景)
- 使用事务 (Transactions): 如果数据库支持(如 PostgreSQL, SQL Server, MySQL InnoDB引擎),并且多个操作是一个逻辑单元(添加字段A后必须紧接着添加字段B),可以将多个
ALTER TABLE或CREATE TABLE语句包裹在一个事务 (BEGIN;…COMMIT;) 中,这确保了要么所有操作都成功,要么全部回滚,保持数据库一致性,但需注意,某些 DDL 操作在某些数据库引擎中可能隐式提交事务。 - 变更管理: 对于生产环境,强烈建议使用数据库迁移工具 (如 Flyway, Liquibase, Alembic, Django Migrations, Rails Migrations),这些工具:
- 将数据库结构变更(Schema Changes)脚本化、版本化。
- 记录变更历史,便于追踪和回滚。
- 确保在不同环境(开发、测试、生产)中变更以完全相同且可控的顺序应用。
- 自动化执行过程,减少人为错误。
- 文档化: 无论是直接执行 SQL 还是使用迁移工具,都要清晰记录每次变更的原因、内容、执行时间和执行人,更新相关的数据字典或ER图。
- 性能影响: 向大型表添加字段(尤其是
NOT NULL且无默认值,或需要填充大量数据时)可能会耗时较长并导致表锁,影响线上服务,务必评估影响并在维护窗口操作,对于海量表,可能需要特殊的在线DDL策略或工具。 - 兼容性: 考虑新添加的表或字段对现有应用程序代码、报表、API 接口的影响,确保应用层能够正确处理新结构或新数据。
- 命名规范: 始终遵循团队或项目的数据库对象命名规范,保持一致性。
“数据库表依次加”的核心在于安全、有序、有计划地扩展数据库结构,无论是创建新表还是添加字段:
- 必须备份。
- 精心设计。
- 在测试环境验证。
- 按依赖关系或逻辑顺序依次执行 SQL 语句 (
CREATE TABLE或ALTER TABLE ... ADD COLUMN)。 - 优先考虑使用数据库迁移工具进行版本控制和自动化。
- 在低峰期操作生产环境,并监控影响。
遵循这些步骤和最佳实践,可以有效地管理数据库结构的演进,确保数据的完整性和系统的稳定性。
引用说明:
- 本文中涉及的 SQL 语法核心概念(
CREATE TABLE,ALTER TABLE,ADD COLUMN, 约束定义)均基于标准 SQL 规范以及主流关系型数据库管理系统(如 MySQL, PostgreSQL, Microsoft SQL Server, Oracle)的通用实现,具体语法细节(如AUTO_INCREMENT,COMMENT子句,AFTER子句)可能因数据库产品略有差异,请务必参考相应数据库的官方文档:- MySQL:
https://dev.mysql.com/doc/ - PostgreSQL:
https://www.postgresql.org/docs/ - SQL Server:
https://docs.microsoft.com/en-us/sql/sql-server/?view=sql-server-ver16 - Oracle:
https://docs.oracle.com/en/database/
- MySQL:
- 关于数据库迁移工具(Flyway, Liquibase 等)的信息,请参考其各自的官方网站和文档。