-
 行业动态
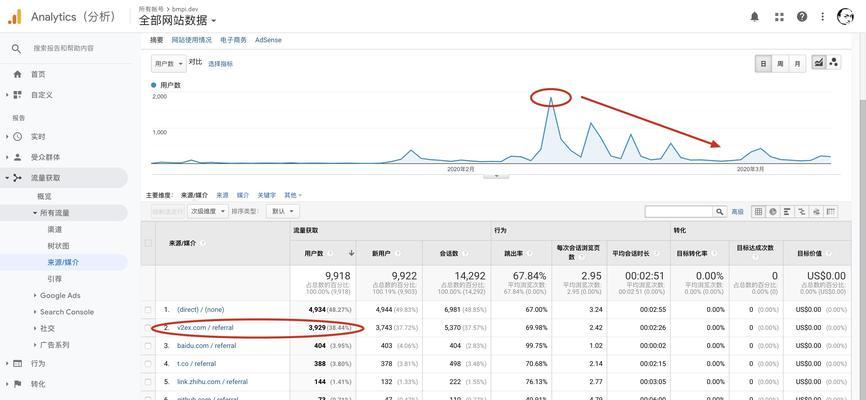
行业动态 如何通过分析网站日志提升搜索引擎爬虫抓取效率?
通过解析网站日志中的用户代理、IP地址及访问特征,可有效识别搜索引擎爬虫流量,区分正常抓取与反面扫描,帮助优化服务器负载分配、提升SEO...
 admin 2025-04-17 12 0
admin 2025-04-17 12 0 -
 行业动态
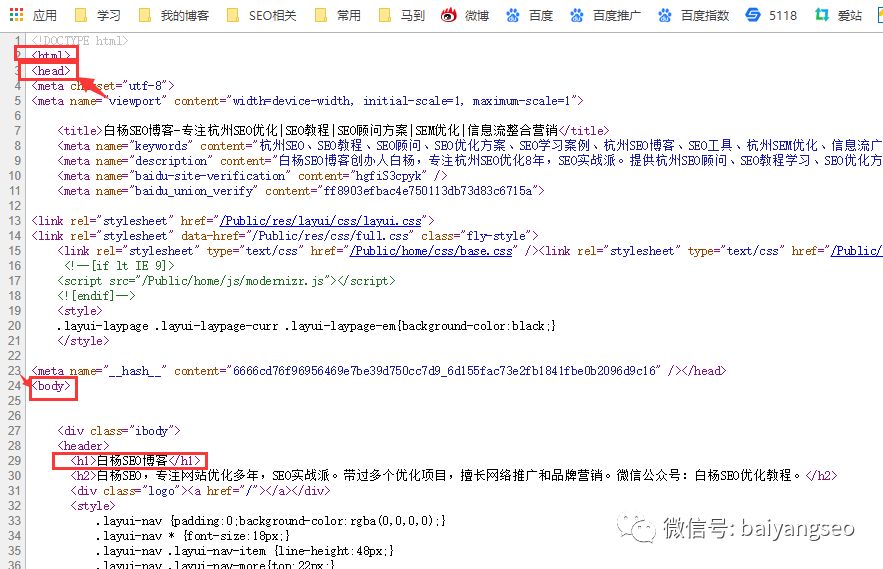
行业动态 为什么掌握基础的HTML代码对SEO优化至关重要?
SEO(搜索引擎优化)是提升网站在搜索引擎结果页中的自然排名的一系列技术和策略,虽然精通代码对于深入理解SEO的工作原理非常有帮助,但许...
admin 2024-11-01 11 0 -
如何理解搜索引擎爬虫的工作原理及个人对其的看法?
admin 2024-10-23 6 0搜索引擎爬虫的理解与观点搜索引擎爬虫的基本概念1. 定义与功能搜索引擎爬虫(Spider或Crawler)是用于自动抓取互联网上网页信息...
-
 行业动态
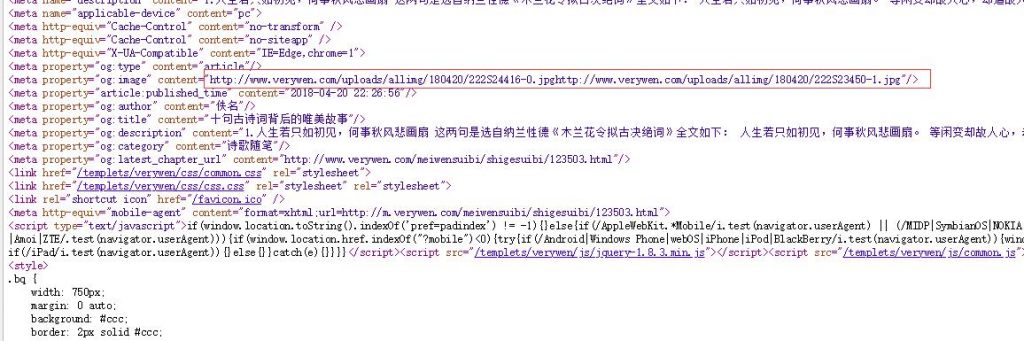
行业动态 如何优化织梦dedecms网站的robots文件设置以更好地引导搜索引擎爬虫?
【织梦dedecms的robots文件设置看法】概述robots文件是网站管理员用来告诉搜索引擎爬虫哪些页面可以抓取,哪些页面不可以抓取...
admin 2024-10-07 5 0 -
 行业动态
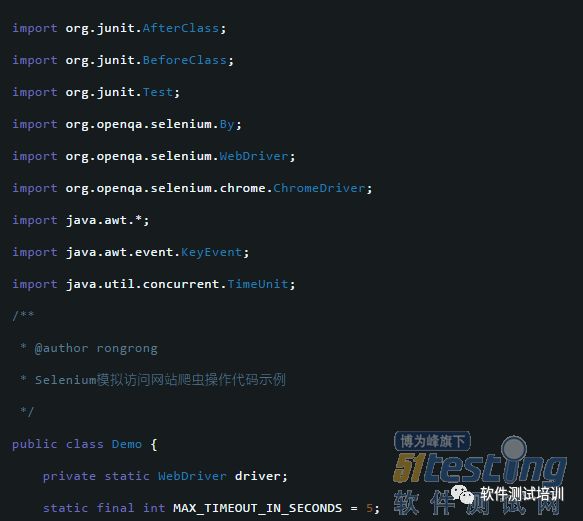
行业动态 如何通过服务器爬虫高效抓取数据库数据?
服务器爬虫可通过模拟请求调用数据库接口获取数据,或利用破绽直接访问数据库,常用方式包括API调用、SQL注入、绕过验证等,需注意目标系统...
admin 2025-04-19 3 0 -
 行业动态
行业动态 Google搜索引擎营销如何高效提升网络流量?
Google搜索营销的核心优势智能算法驱动精准流量Google RankBrain人工智能系统可解析200多种搜索意图信号,通过深度学习...
admin 2025-04-17 4 0 -
 行业动态
行业动态 Python爬虫零基础入门教程,10分钟搞定数据采集与可视化实战指南
本文介绍从零开始利用Python爬虫技术采集网络数据,通过Requests/BeautifulSoup解析网页并存储至数据库,结合Pan...
admin 2025-04-15 5 0 -
服务器爬虫windows
在Windows服务器环境下部署网络爬虫需结合Python框架(如Scrapy)及多线程技术,通过任务调度实现自动化采集,需注意IIS配...
admin 2025-04-14 6 0 -
 行业动态
行业动态 服务器爬虫淘宝
服务器爬虫可用于自动化采集淘宝商品数据,通过模拟浏览器行为或API接口实现信息抓取,需处理反爬机制如IP限制、验证码等,通常配合代理IP...
admin 2025-04-14 3 0 -
 行业动态
行业动态 万网cdn搜索引擎回源
万网CDN(现阿里云CDN)的搜索引擎回源功能通过智能识别爬虫请求,自动将搜索引擎流量导向源站服务器,确保抓取内容实时更新,该机制有效避...
admin 2025-04-13 8 0 -
 行业动态
行业动态 服务器爬虫监控软件
服务器爬虫监控软件用于实时追踪和管理服务器端网络爬虫运行状态,具备异常行为检测、资源消耗分析及自动拦截功能,通过可视化报表与告警机制,协...
admin 2025-04-12 6 0 -
服务器爬虫流程
服务器爬虫流程通常包括明确目标网站、发送HTTP请求获取页面、解析提取数据、存储至数据库或文件,同时处理反爬机制如IP限制或验证码,并定...
admin 2025-04-11 7 0 -
c网络爬虫源码
admin 2025-04-01 8 0``python,import requests,from bs4 import BeautifulSoupurl = "http://...







没有更多内容








