
上一篇
MapReduce中的线程管理,如何优化并行处理性能?
MapReduce是一种编程模型,用于处理和生成大数据集。它分为两个阶段:Map(映射)和Reduce(归约)。在Map阶段,输入数据被分割成多个块,每个块由一个线程处理并生成中间键值对。在Reduce阶段,具有相同键的中间键值对被组合在一起,并由另一个线程处理以生成最终结果。
在MapReduce中,线程的使用和控制是一个复杂而重要的问题,MapReduce框架本身是基于多进程模型的,但在实际执行过程中,可以通过多种方式引入多线程机制来提高任务的执行效率,以下是关于MapReduce中线程使用的一些详细讨论:
MapReduce中的多线程使用
1、多进程与多线程的区别
多进程模型:Hadoop MapReduce采用了多进程模型,每个Map Task和Reduce Task都在一个独立的JVM进程中运行,这种模型便于细粒度控制每个任务占用的资源,但会消耗较多的启动时间,不适合运行低延迟类型的作业。
多线程模型:Spark采用了多线程模型,所有任务都运行在一个JVM进程中,每个任务是一个线程,这种模型使得任务启动速度快,适合内存密集型任务,但会出现资源争用问题。
2、MapReduce中的多线程实现
Mapper中的多线程:可以在Mapper中加入多线程来处理数据,在读取关键词文件并搜索图片地址后,可以开启多个线程进行下载和转换,这种方式可以提高Mapper的处理速度,但需要注意线程同步和资源管理。
LevelDB的多线程访问:在使用LevelDB作为本地词典时,每份数据只能同时被一个线程访问,为了避免多线程访问同一数据的问题,可以将词典分发到单机上,每个任务在当前目录下建立一个符号链接指向词典数据。
Fork/Join框架:Java 7提供的Fork/Join框架可以将大任务分割成若干个小任务并行执行,类似于MapReduce中的Map和Reduce过程,这种框架可以用于在MapReduce任务中实现多线程。
MapReduce性能优化
1、操作系统调优
增大文件描述符上限:通过调整内核参数net.core.somaxconn,提高读写速度和网络带宽使用率。
关闭swap:避免内存不足时系统将部分数据写入磁盘,降低进程执行效率。

增加预读缓存区大小:减少磁盘寻道次数和I/O等待时间。
2、Hdfs参数调优
设置临时文件目录:尽量手动配置hadoop.tmp.dir选项,使每个磁盘都设置一个临时文件目录,提高磁盘IO效率。
调整块大小:适当调整dfs.blocksize参数,避免太大或太小的块影响MapReduce任务的执行效率。
3、MapReduce参数调优
合理设置槽位数目:调整mapred.reduce.tasks和mapreduce.job.reduces参数,合理设置Reduce Task的数量。
设置缓冲区大小:调整mapred.child.java.opts参数,设置JVM启动的子线程可以使用的最大内存。
启用批量任务调度:通过调整mapreduce.job.reuse.jvm.num.tasks参数,启用批量任务调度,提高资源利用率。

常见问题解答(FAQs)
问题1:为什么MapReduce任务需要使用多线程?
答案: MapReduce任务使用多线程可以提高任务的执行效率,在Mapper中加入多线程可以加快数据处理速度,特别是在需要同时处理多个独立任务时(如下载和转换图片),多线程能够充分利用系统资源,提高任务的并发性,从而缩短任务的整体执行时间。
问题2:如何在MapReduce中使用LevelDB实现多线程访问?
答案: 在使用LevelDB作为本地词典时,为了避免多线程访问同一数据的问题,可以将词典分发到单机上,每个任务在当前目录下建立一个符号链接指向词典数据,这样可以避免多线程访问同一数据,确保数据的一致性和安全性,具体实现可以参考以下步骤:
1. 将LevelDB词典数据分发到各个计算节点。
2. 在每个任务的当前目录下创建一个符号链接,指向词典数据。
3. 在任务中通过符号链接访问词典数据,实现多线程安全访问。
通过合理使用多线程技术,可以显著提升MapReduce任务的执行效率和系统资源的利用率。

| 项目 | 线程A | 线程B | 线程C | 线程D |
| 任务阶段 | 分区(Map) | 转换(Map) | 聚合(Reduce) | 输出(Reduce) |
| 线程A职责 | 读取输入数据 | 执行Map函数 | 无 | 无 |
| 线程B职责 | 读取输入数据 | 执行Map函数 | 无 | 无 |
| 线程C职责 | 无 | 无 | 对Map输出进行分组 | 无 |
| 线程D职责 | 无 | 无 | 对Map输出进行排序 | 输出结果 |
| 线程同步 | 线程A和B在Map阶段完成后同步 | Map阶段完成后,线程C和D在Reduce阶段开始前同步 | Reduce阶段完成后,线程D输出结果后结束 | 无 |
说明:
线程A和B负责Map阶段的读取输入数据和执行Map函数。
线程C负责Reduce阶段的分组工作。
线程D负责Reduce阶段的排序和输出结果。
线程之间通过MapReduce框架提供的同步机制进行同步。
相关文章
-

MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
-
服务器15核通常指的是拥有15个中央处理器(CPU)核心的服务器。在多核处理器架构中,一个物理处理器可以包含多个核心,每个核心能够独立执行任务。因此,一个15核的服务器意味着它有15个这样的处理单元,可以并行处理任务,提高计算效率和多任务处理能力。,这样的服务器配置适合于需要高计算性能和并行处理能力的应用场景,例如大数据处理、科学模拟、复杂的数据分析、以及为大量用户提供服务的高性能网站和应用等。
-
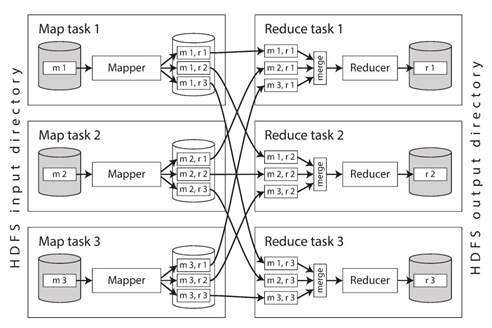
MapReduce中的catchfile_MapReduce是如何优化数据处理的?
-

MapReduce Shuffle调优,如何优化MapReduce中的Shuffle过程?
-

MapReduce文本对处理,探索TextPair_MapReduce的实际应用与挑战
-
如何正确配置mapreduce.map.tasks参数以优化MapReduce作业性能?
-

MRS MapReduce中MapReduce节点如何实现高效数据处理的优化策略?
-
如何优化MapReduce节点以提高MRS MapReduce作业的性能?








