上一篇
c文字识别源码
请提供具体的内容呀,这样我才能按照要求为你生成相应的简答呢。
在当今数字化时代,文字识别技术(OCR, Optical Character Recognition)已成为信息处理领域的一项关键技术,它能够将图像中的文字转换为计算机可编辑的文本格式,极大地提高了数据处理的效率和准确性,本文将深入探讨C语言实现文字识别的源码,包括其基本原理、关键步骤以及示例代码,旨在为开发者提供一套完整的指南。
一、文字识别技术
文字识别技术主要依赖于模式识别和机器学习算法,通过分析图像中的像素分布来识别字符,C语言因其高效性和灵活性,常被用于开发底层的图像处理和模式识别算法。
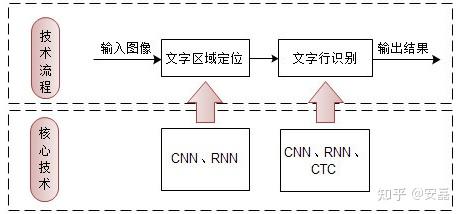
二、C语言实现文字识别的关键步骤
1、图像预处理:
灰度化:将彩色图像转换为灰度图像,减少数据量并简化后续处理。
降噪:应用滤波器去除图像噪声,提高识别准确率。
二值化:根据阈值将图像转换为黑白两色,便于字符分割。
2、字符分割:

利用投影法或轮廓检测算法,将文本图像中的字符逐一分割出来。
3、特征提取:
对每个字符进行特征提取,如笔画宽度、高度、交叉点等,为识别做准备。
4、字符识别:
使用模板匹配、神经网络或支持向量机等算法,将提取的特征与预定义的字符模型进行比对,识别出具体字符。
5、后处理:
校正识别结果,处理可能的误识别,提高整体识别率。
三、示例代码解析
以下是一个简化的C语言实现文字识别的示例代码框架,主要展示图像预处理和字符分割的基本流程。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "cv.h"
#include "highgui.h"
// 灰度化函数
void grayscale(IplImage* src, IplImage* dst) {
CvSize size = cvGetSize(src);
dst = cvCreateImage(size, IPL_DEPTH_8U, 1);
cvCvtColor(src, dst, CV_BGR2GRAY);
}
// 二值化函数
void binarize(IplImage* src, IplImage* dst, int threshold) {
CvSize size = cvGetSize(src);
dst = cvCreateImage(size, IPL_DEPTH_8U, 1);
cvThreshold(src, dst, threshold, 255, CV_THRESH_BINARY);
}
// 主函数
int main() {
IplImage* src = cvLoadImage("text.jpg", CV_LOAD_IMAGE_COLOR);
IplImage* gray = NULL;
IplImage* binary = NULL;
if (!src) {
printf("Error: Image cannot be loaded.
");
exit(1);
}
grayscale(src, gray);
binarize(gray, binary, 128); // 假设阈值为128
// 这里可以添加字符分割和识别的代码...
cvShowImage("Binary Image", binary);
cvWaitKey(0);
cvReleaseImage(&src);
cvReleaseImage(&gray);
cvReleaseImage(&binary);
cvDestroyAllWindows();
return 0;
}
四、FAQs
Q1: 为什么需要对图像进行灰度化和二值化处理?
A1: 灰度化减少了颜色信息,简化了数据处理过程,而二值化则进一步将图像简化为黑白两色,使得字符与背景更加分明,有利于后续的字符分割和识别。
Q2: 如何选择合适的阈值进行二值化?
A2: 阈值的选择通常取决于图像的质量和光照条件,可以通过实验或使用自适应阈值算法来确定最佳阈值,以确保字符和背景的有效分离。
五、小编有话说
文字识别技术作为人工智能领域的重要分支,正不断推动着信息处理技术的革新,虽然C语言在实现复杂算法时可能不如某些高级语言直观,但其高效性和灵活性使其在底层开发中具有不可替代的地位,希望本文能为有意涉足文字识别领域的开发者提供有益的参考和启示,随着技术的不断进步,我们期待看到更多创新和高效的文字识别解决方案涌现。