上一篇
安卓图片文字识别代码大全
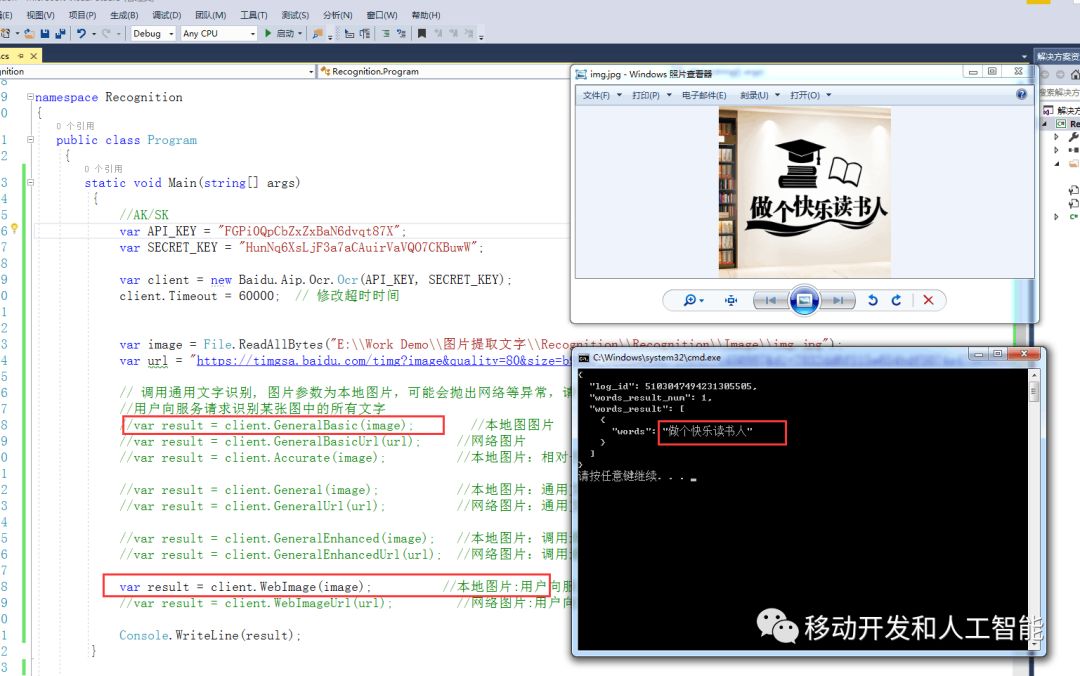
安卓图片文字识别可通过集成ML Kit或Tesseract库实现,需配置存储权限,调用CameraX采集图像,经灰度处理、二值化预处理后,调用OCR引擎解析文本,最终通过TextView展示识别结果
依赖配置
Google ML Kit OCR
// 在项目 build.gradle 中添加
dependencies {
implementation 'com.google.mlkit:text-recognition:17.0.2'
}
Tesseract OCR
// 添加 Tesseract 依赖(需自行编译或使用第三方封装库) implementation 'com.rmtheis:tess-two:2.3.2'
PaddleOCR(百度飞桨)
// 添加 PaddleOCR 依赖
dependencies {
implementation 'com.baidu.paddle:paddle-ocr:1.0.0'
}
权限处理
AndroidManifest.xml 配置
<uses-permission android:name="android.permission.CAMERA" /> <uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE" /> <uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" />
运行时权限申请(Kotlin)
// 在 Activity 中申请权限
private fun checkPermissions() {
val permissions = arrayOf(
android.Manifest.permission.CAMERA,
android.Manifest.permission.READ_EXTERNAL_STORAGE,
android.Manifest.permission.WRITE_EXTERNAL_STORAGE
)
ActivityCompat.requestPermissions(this, permissions, REQUEST_CODE_PERMISSION)
}
核心代码实现
Google ML Kit OCR
// 1. 初始化 ML Kit
val firebaseVisionTextRecognizer = FirebaseVision.getInstance()
.getOnDeviceTextRecognizer()
// 2. 处理图片并识别文字
fun recognizeText(image: Bitmap) {
val image = FirebaseVisionImage.fromBitmap(image)
firebaseVisionTextRecognizer.processImage(image)
.addOnSuccessListener { text ->
// 处理识别结果
text.textBlocks.forEach { block ->
Log.d("OCR", "${block.text}")
}
}
.addOnFailureListener { e ->
e.printStackTrace()
}
}
Tesseract OCR
// 1. 初始化 Tesseract
BaseAPI baseApi = new TessBaseAPI();
baseApi.init(context.getFilesDir().absolutePath, "chi_sim"); // 中文简体
// 2. 识别文字
public String recognizeImage(Bitmap bitmap) {
baseApi.setImage(bitmap);
return baseApi.getUTF8Text();
}
// 3. 释放资源
baseApi.end();
PaddleOCR
// 1. 加载模型
OCRModel model = new OCRModel(context, "ch_PP-OCRv3"); // 中文模型
// 2. 识别文字
public String recognizeImage(Bitmap bitmap) {
List<String> results = model.detectText(bitmap);
return String.join("
", results);
}
注意事项
| 方案 | 是否需要网络 | 支持语言 | 准确率 | 集成难度 |
|---|---|---|---|---|
| Google ML Kit | 离线优先 | 多语言(需下载) | 高 | 低 |
| Tesseract | 完全离线 | 依赖训练数据包 | 中等 | 中 |
| PaddleOCR | 离线优先 | 多语言(需配置) | 高 | 中 |
相关问题与解答
问题1:如何提高文字识别准确率?
解答:
- 图片预处理:调整对比度、灰度化、去噪(如使用 OpenCV)。
- 选择高质量模型:优先使用基于深度学习的模型(如 PaddleOCR)。
- 适配语言包:确保 OCR 引擎加载了正确的语言包(如中文需
chi_sim)。 - 优化输入图片:文字清晰、无倾斜、背景均匀。
问题2:如何处理多语言混合场景?
解答:
- Google ML Kit:通过
FirebaseVisionTextRecognizer自动检测语言。 - Tesseract:手动加载多个语言包(如
eng+chi_sim)。 - PaddleOCR:选择支持多语言的模型(如
multi_language