
上一篇
方言识别的人工智能思路
方言识别的人工智能思路包括:采集方言样本,提取特征,训练模型,识别方言。需考虑方言多样性、口音差异等,以提高识别准确率。
方言识别是人工智能领域中的一个复杂而有趣的挑战,它涉及到语音识别、自然语言处理和机器学习等多个技术方向,以下是对方言识别的人工智能思路的详细阐述:
一、数据收集与预处理
1、数据收集
多源采集:从不同地区、不同年龄段、不同性别的人群中收集方言语音样本,确保数据的多样性和代表性。
高质量录音:使用高质量的录音设备,在安静的环境中录制清晰的方言语音,减少背景噪声的干扰。
标注与分类:对收集到的语音样本进行详细的标注,包括方言种类、发音人信息、语音内容等,并进行分类存储。
2、数据预处理
音频格式转换:将收集到的语音样本转换为统一的音频格式,如WAV或FLAC,以便于后续处理。
降噪处理:利用音频处理技术去除语音中的噪声,提高语音的清晰度和可辨识度。
特征提取:从预处理后的语音中提取关键特征,如梅尔频率倒谱系数(MFCC)、基音周期等,作为后续模型训练的输入。
二、模型选择与训练
1、模型选择
深度学习模型:考虑使用卷积神经网络(CNN)、循环神经网络(RNN)及其变体(如LSTM、GRU)等深度学习模型,这些模型在处理序列数据方面具有强大的能力。

混合模型:结合HMM(隐马尔可夫模型)和DNN(深度神经网络)的优势,构建混合模型以提高识别准确率。
2、模型训练
划分数据集:将预处理后的数据划分为训练集、验证集和测试集,用于模型的训练、调优和评估。
参数调整:通过网格搜索或随机搜索等方法调整模型的超参数,如学习率、批量大小、迭代次数等,以优化模型性能。
训练与验证:使用训练集对模型进行训练,并在验证集上进行验证,根据验证结果调整模型参数,直至达到满意的性能指标。
三、方言识别系统构建
1、前端处理
语音输入:设计友好的用户界面,允许用户通过麦克风或其他输入设备输入方言语音。
实时处理:对接收到的语音进行实时预处理,包括降噪、特征提取等,为后续识别做好准备。
2、后端识别
模型加载:将训练好的方言识别模型加载到系统中,准备进行语音识别。
语音识别:将前端处理后的语音特征输入到模型中,通过模型的推理过程输出识别结果。
结果展示:将识别结果显示在用户界面上,可以包括文本形式、语音播报或可视化图表等多种形式。
四、性能评估与优化
1、性能评估
准确率:计算识别结果与真实标注之间的匹配程度,评估系统的识别准确率。
召回率:衡量系统能够正确识别出的方言样本占所有实际方言样本的比例。
F1分数:综合考虑准确率和召回率,给出一个综合的性能评价指标。
2、系统优化
错误分析:对识别错误的样本进行分析,找出错误原因并针对性地改进模型或预处理方法。
模型更新:随着新数据的增加和对方言变化规律的深入理解,定期更新模型以保持其性能和适应性。
五、FAQs
问:方言识别的人工智能系统在实际应用中面临哪些挑战?
答:方言识别的人工智能系统在实际应用中可能面临以下挑战:一是方言的多样性和复杂性导致数据收集和标注难度大;二是不同方言之间的差异可能使得模型难以泛化;三是实时性和准确性之间的平衡也是一个挑战点;四是对方言变化和新词汇的适应能力需要不断提升。
问:如何提高方言识别系统的鲁棒性和适应性?
答:为了提高方言识别系统的鲁棒性和适应性,可以采取以下措施:一是不断扩充和更新训练数据,覆盖更多的方言种类和变化;二是采用更先进的模型架构和算法,提高模型的泛化能力和学习能力;三是加强错误分析和反馈机制,及时调整模型参数和策略;四是结合其他技术和知识来源(如语言学规则、地理信息系统等),增强系统对方言语境的理解和处理能力。
相关文章
-
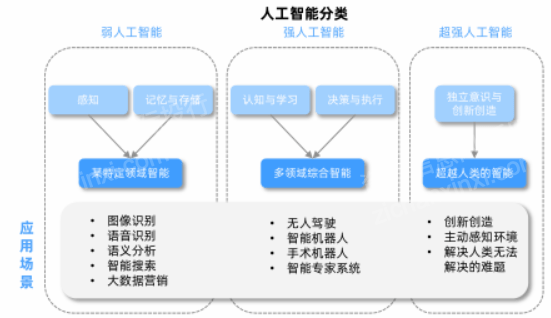
人工智能算法应用,人工智能算法应用领域2022年更新(人工智能算法及应用)
-

由于您没有提供具体的文章或内容,我无法直接为您生成一个原创的疑问句标题。不过,我可以给您一个示例来说明如何根据文章内容生成疑问句标题,,示例文章,,随着科技的发展,人工智能已经逐渐渗透到我们生活的方方面面。从智能语音助手到自动驾驶汽车,AI技术正在改变着世界。然而,这也引发了一些关于隐私和伦理问题的担忧。,生成的疑问句标题,,人工智能的快速发展是否带来了不可忽视的隐私和伦理挑战?,如果您能提供具体的文章或内容,我将能够为您生成更精确、更有针对性的疑问句标题。
-
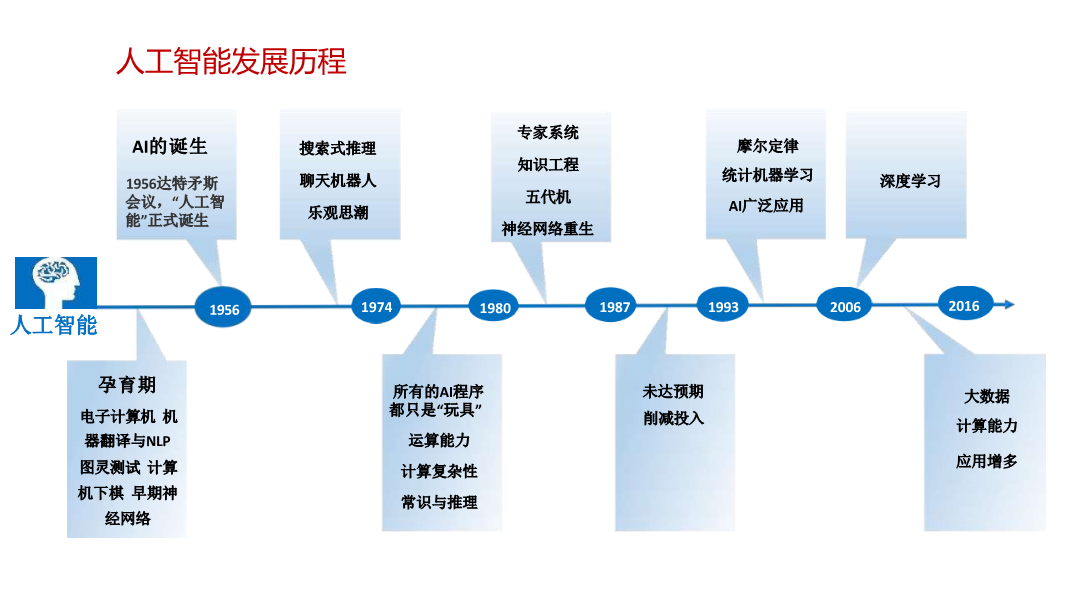
ai人工智能系统_人工智能
-

ai人工智能的发展趋势_人工智能
-

ai人工智能发展趋势_人工智能
-

ai人工智能好学吗_人工智能
-

ai人工智能未来_人工智能
-
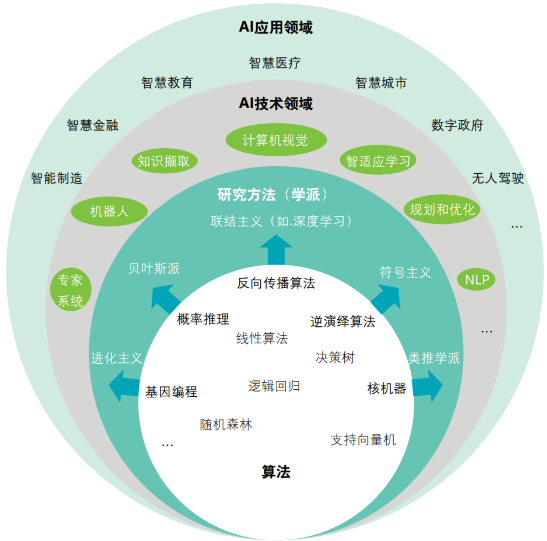
ai人工智能软件开发_人工智能
-

ai人工智能编程培训_华为人工智能工程师培训








