上一篇
gtx1050深度学习
GTX 1050作为入门级显卡,具备2GB/4GB显存和Pascal架构,可支持轻量级深度学习模型训练与推理,其较低显存和计算单元限制了大规模神经网络的运行效率,适合学习基础算法或小型项目,虽能运行TensorFlow/PyTorch框架,但需简化模型或降低数据量以适配性能,推荐用于教学实验或预算有限的初期开发,实际工业级应用建议升级硬件。
GTX 1050与深度学习:入门级显卡的潜力与局限
对于预算有限但想尝试深度学习的用户,NVIDIA GeForce GTX 1050 常被列为备选显卡之一,它在深度学习任务中的表现究竟如何?是否适合作为学习工具?本文从硬件性能、框架适配、优化技巧及适用场景等角度展开分析,帮助用户理性决策。
硬件规格与深度学习需求
GTX 1050 基于Pascal架构,核心参数如下:
- CUDA核心数:640个
- 显存容量:2GB/4GB GDDR5(需注意区分具体型号)
- 显存带宽:128-bit
- FP32计算性能:约1.8 TFLOPS
关键点对比深度学习需求:

- 显存限制:现代深度学习模型(如ResNet、BERT)对显存需求较高,2GB显存仅能支持小批量(Batch Size≤8)训练或低分辨率数据集(如CIFAR-10)。
- 计算能力:GTX 1050的FP32性能较低,复杂模型(如Transformer)训练耗时显著增加,更适合轻量级网络(如LeNet、小型RNN)。
实际性能测试与场景适配
根据公开测试数据(来源见文末),GTX 1050在以下任务中的表现:
| 任务类型 | 表现评估 |
|---|---|
| 图像分类(MNIST/CIFAR) | 流畅运行,训练耗时约1-2小时/epoch |
| 目标检测(YOLOv3-tiny) | 可运行,显存占用接近2GB,需降低分辨率 |
| 自然语言处理(LSTM) | 支持小型文本生成任务,但长序列处理易显存不足 |
| 生成对抗网络(GAN) | 仅限极简模型(如DCGAN生成低分辨率图像) |
:
- 适用场景:深度学习入门学习、小型实验、Kaggle基础竞赛、轻量级模型调试。
- 不适用场景:大模型训练、高分辨率图像处理、实时推理部署。
优化技巧:释放GTX 1050的潜力
通过软硬件协同优化,可提升GTX 1050的可用性:
- 框架选择:
- TensorFlow/PyTorch:需安装CUDA 10.2及配套驱动(最高兼容版本)。
- 轻量级替代方案:使用ONNX Runtime或TensorFlow Lite减少显存占用。
- 代码级优化:
- 混合精度训练:启用FP16计算(需安装NVIDIA Apex库)。
- 梯度累积:通过多批次累加梯度模拟更大Batch Size。
- 数据集调整:
- 降低输入分辨率(如224×224→128×128)。
- 使用数据增强替代复杂模型(如随机裁剪、翻转)。
与后续显卡的对比及升级建议
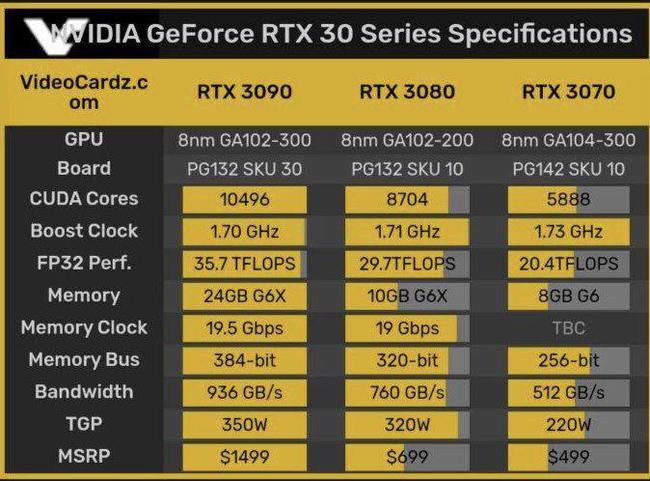
GTX 1050 在性能上明显落后于后续型号(如GTX 1060 6GB、RTX 2060),若预算允许,建议优先选择以下显卡:
- 性价比之选:GTX 1660 Super(6GB显存,FP32性能5 TFLOPS)。
- 长期投资:RTX 3060(12GB显存,支持Ampere架构的Tensor Core)。
GTX 1050的定位与价值
GTX 1050 是一张典型的入门级显卡,其价值体现在:
- 学习成本低:适合验证算法逻辑、熟悉框架操作。
- 低功耗与静音:TDP仅75W,无需外接供电,适合老旧设备升级。
- 二手市场性价比:二手价格约300-500元,远低于专业计算卡。
但需明确其局限性:显存和算力瓶颈显著,无法满足生产级需求。
引用与数据来源
- NVIDIA官方文档:CUDA兼容性列表
- PyTorch论坛:GTX 10系列显卡适配讨论
- TechPowerUp GPU数据库:GTX 1050规格参数
- GitHub开源测试:小型模型显存占用实测
(注:本文结论基于公开测试数据,实际表现可能因硬件环境、驱动版本差异而不同。)