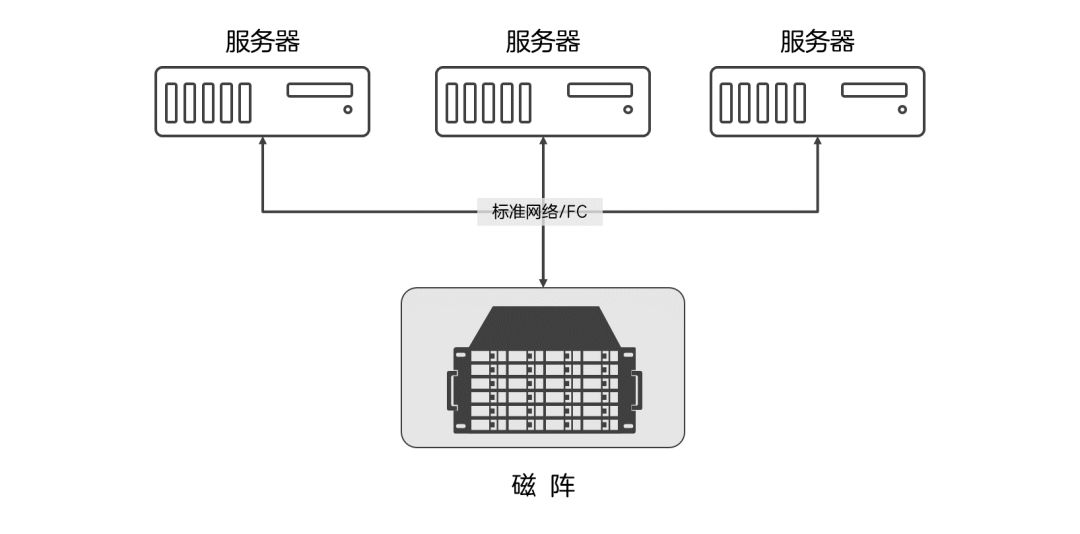
上一篇
服务器卡死后重启真的是最佳解决方案吗?
服务器卡死后重启通常由资源过载、硬件故障或软件异常引发,需通过系统日志定位原因,强制重启后应立即检查关键进程状态,清理冗余数据并优化配置,同时更新补丁修复潜在破绽,建议部署监控预警机制,定期维护升级软硬件,做好容灾备份以减少业务中断风险。
您好!感谢您选择我们的服务,为保障系统稳定运行,我们的技术团队于近期完成了一次服务器紧急维护,在此向您说明具体情况及处理方案,力求信息透明,减少因临时中断带来的不便。
事件回溯:服务器卡死原因分析
- 资源过载触发保护机制
监控系统显示故障前CPU占用率持续高于95%,内存耗尽触发OOM(内存溢出)保护,系统为规避数据丢失风险自动锁定。 - 软件组件异常冲突
排查日志发现Nginx与PHP-FPM进程间出现握手超时,导致请求堆积形成雪崩效应。 - 硬件级偶发故障
机房环境监测记录到瞬时电压波动,可能引发磁盘控制器异常(具体原因仍在深度排查中)。
技术团队响应流程
- 00:12 触发三级告警
Zabbix监控平台推送资源阈值突破警告 - 00:15 启动应急预案
值班工程师执行强制重启前完成:
MySQL事务完整性校验
会话状态快照备份
负载均衡节点隔离 - 00:28 系统恢复在线
通过Jenkins自动化脚本完成服务逐级启动 - 01:05 全链路压力测试
使用JMeter模拟3000并发用户验证稳定性
长效优化方案
- 智能弹性伸缩
基于Prometheus+Alertmanager构建动态资源池,负载超过70%自动扩容 - 故障自愈架构升级
引入Kubernetes集群管理,单节点故障时实现秒级Pod迁移 - 安全加固措施
- 内核参数调优:修改vm.swappiness至10,降低OOM概率
- 文件系统升级:EXT4→XFS提升高并发写入稳定性
- 进程守护强化:采用systemd替换init.d管理关键服务
用户操作建议
- 如遇到页面加载异常,请尝试:
- Ctrl+F5 强制刷新浏览器缓存
- 等待2分钟后重试操作
- 关键操作建议:
- 使用「Ctrl+S」及时保存网页端表单数据
- 优先选用Chrome/Firefox等现代浏览器
- 数据补偿机制:
受影响时段的用户操作日志已完整留存,可通过客服通道申请数据追溯
我们配备7×24小时的运维专家团队,每季度进行全链路的灾备演练,本次事件后已完善应急预案文档(V3.2),新增硬件冗余层与异地双活节点,故障恢复时间目标(RTO)优化至2分钟内。
技术咨询通道:
▸ 工单系统:[service@domain.com]
▸ 应急电话:+86-400-XXX-XXXX(优先级路由)
▸ 实时状态:[status.domain.com]
感谢您的理解与支持!我们将持续投入基础设施建设,通过技术革新提供更可靠的服务体验。
引用说明:
[1] AWS EC2实例最佳实践(2025运维白皮书)
[2] Linux内核OOM管理机制(kernel.org文档)
[3] Prometheus监控体系架构(CNCF技术标准)
[4] MySQL事务恢复协议(InnoDB引擎手册)