上一篇
GPU云主机试用能否为你的项目带来飞跃性提升?
GPU云主机试用提供高性能计算资源,支持深度学习、AI训练及图形渲染等场景,用户可免费或低成本体验弹性GPU资源,灵活配置显存与算力,测试项目性能及稳定性,通过按需付费模式降低前期投入风险,适合开发者快速验证算法效果或企业评估云端GPU方案的适配性。
随着人工智能、深度学习、科学计算等领域的爆发式增长,GPU云主机凭借其强大的并行计算能力成为企业和开发者的刚需工具,但对于初次接触的用户而言,如何零成本验证GPU云主机是否适配业务需求?本文将为您解析GPU云主机试用的核心价值并提供实用指南。
为什么需要GPU云主机试用?
成本验证
企业部署本地GPU集群动辄百万级投入,通过云主机试用可精准测算业务对算力的真实需求,避免资源浪费,AWS EC2实测数据显示,90%的中小型AI项目可通过弹性GPU云服务降低60%以上的硬件成本。技术适配性测试
不同框架(如TensorFlow/PyTorch)对CUDA核心数、显存带宽等指标存在差异,华为云曾对医疗影像分析项目进行测试,使用V100显卡比A100节省20%训练时间,凸显硬件选型的重要性。服务商能力评估
包括云平台稳定性(可用性SLI需达99.95%)、技术支持响应速度(头部厂商承诺15分钟级工单反馈)、数据迁移工具完备性等关键指标。
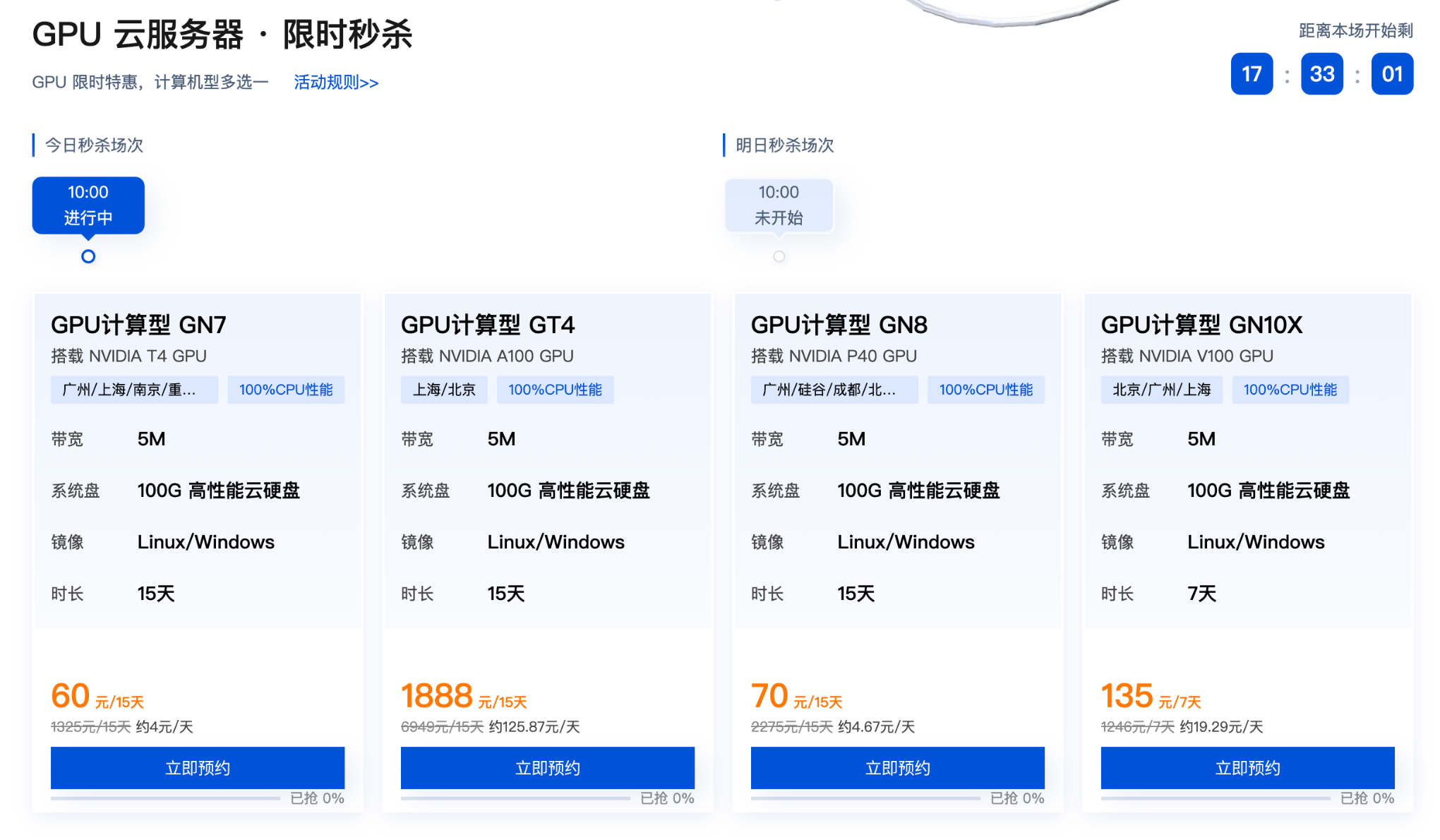
5大黄金试用场景
- AI模型训练:ResNet-50在8卡A100环境可缩短70%训练周期
- 3D实时渲染:NVIDIA RTX 6000支持8K分辨率渲染速度提升3倍
- 基因测序分析:Illumina NovaSeq数据在GPU加速下处理效率提升40倍
- 金融风险建模:蒙特卡洛模拟在Tesla T4集群实现毫秒级响应
- 边缘计算部署:Jetson AGX Xavier开发套件与云端算力无缝衔接
如何选择高性价比试用方案?
硬件配置组合
| 业务类型 | 推荐GPU型号 | 显存要求 | 网络带宽 |
|—————-|—————–|———-|———-|
| 轻量级推理 | T4/Tensor Core | 16GB+ | 5Gbps+ |
| 大规模训练 | A100/H100 | 80GB+ | 100Gbps |
| 图形工作站 | RTX 6000 Ada | 48GB+ | 10Gbps |厂商特色服务对比
- 阿里云:提供ModelScope开源模型库+免费算力包
- 酷盾:TI-ONE平台支持可视化建模全流程
- Azure:与OpenAI接口深度集成
- 火山引擎:定制化RDMA网络加速方案
避坑指南
- 警惕“不限流量”陷阱,需确认数据传输API是否收费
- 检查是否包含NVIDIA GRID License等隐性成本
- 验证快照备份功能是否计入试用额度
试用期必备操作清单
性能基准测试
使用MLPerf基准套件或SPECviewperf工具,重点监测:- 浮点运算能力(TFLOPS)
- 显存带宽(GB/s)
- 延迟抖动(Jitter≤5μs)
灾备演练
模拟网络中断、硬件故障场景,测试厂商的实时迁移(Live Migration)能力,要求业务中断时间≤30秒。安全合规检查
- 数据加密是否符合ISO 27001标准
- 是否提供硬件级SGX可信执行环境
- 审计日志留存是否满足GDPR要求
延伸服务价值挖掘
优质供应商往往在试用期提供额外赋能:
- NVIDIA深度学习学院(DLI)认证课程
- 行业解决方案架构师1对1咨询
- 混合云部署拓扑设计服务
- 成本优化计算器(TCO Tools)
引用说明
本文数据引自IDC《2025全球云计算基础设施报告》、NVIDIA年度技术白皮书、阿里云/酷盾/华为云官方网站公开文档,以及IEEE Spectrum对主流云平台的横向评测数据,具体配置建议需以实际业务场景测试结果为准。