上一篇
大端小端存储方式差异如何影响数据存储?
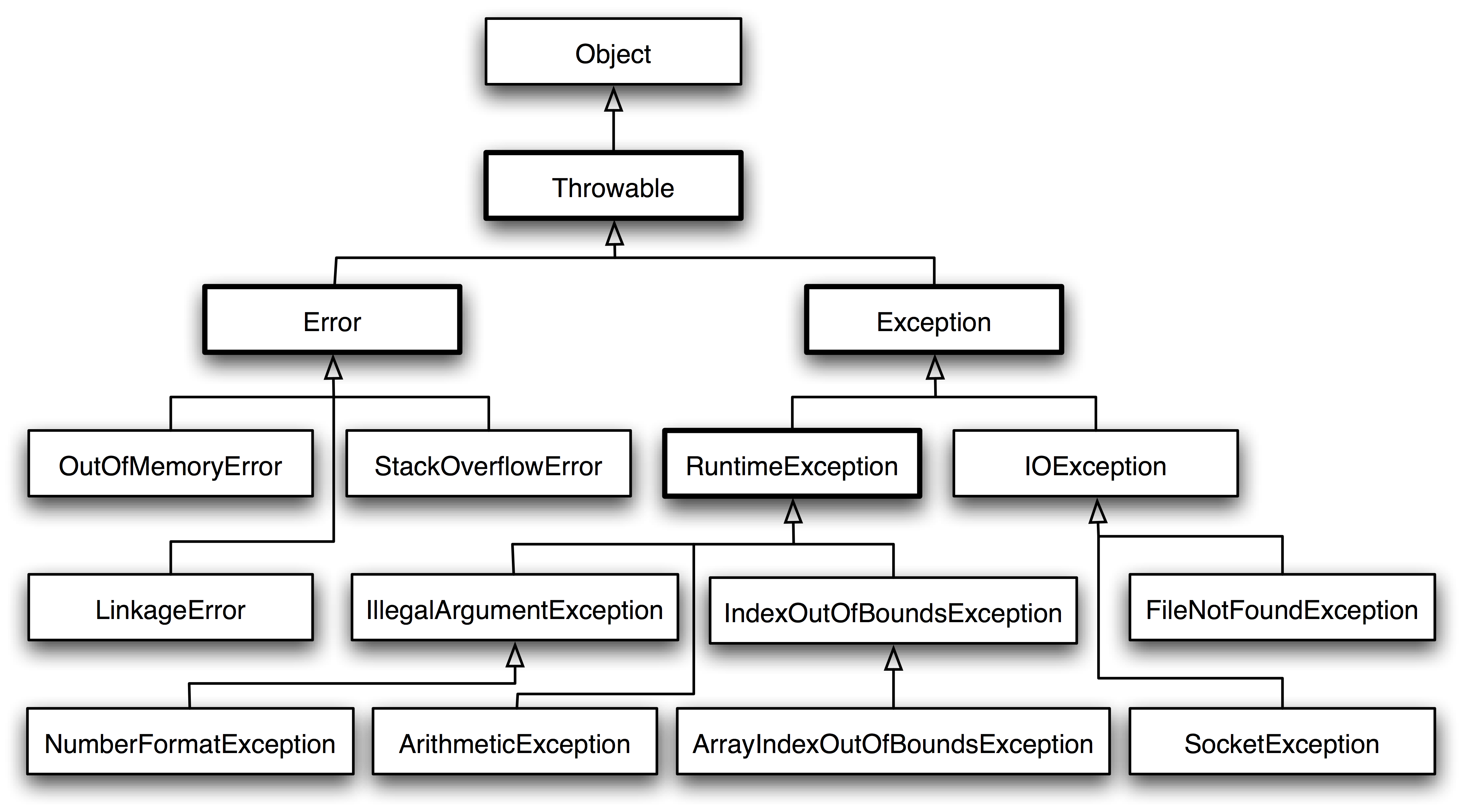
存储器的大小端模式决定了多字节数据的存储顺序,大端模式将高位字节存入低地址,符合人类阅读习惯,常用于网络传输;小端模式将低位字节存于低地址,利于计算机逐位处理,x86等处理器采用此模式,两种模式需通过转换实现数据兼容。
在计算机系统中,数据存储的字节顺序(Byte Order)是一个容易被忽视但至关重要的概念。大端模式(Big-Endian)和小端模式(Little-Endian)是两种截然不同的存储方式,直接影响数据的读写效率和跨平台兼容性,理解它们的区别与适用场景,对开发者、硬件工程师甚至网络安全从业者都具有重要意义。
什么是大小端模式?
字节顺序指的是多字节数据(如整数、浮点数)在内存中的存储顺序,以32位整数 0x12345678(16进制表示)为例:
- 大端模式(Big-Endian):
高位字节存储在低地址,低位字节存储在高地址。
内存布局:12 34 56 78(地址递增方向:左→右)。 - 小端模式(Little-Endian):
低位字节存储在低地址,高位字节存储在高地址。
内存布局:78 56 34 12(地址递增方向:左→右)。
为什么需要两种模式?
硬件设计差异
早期的处理器架构(如Motorola 68000、SPARC)采用大端模式,而Intel x86、ARM(可配置)等则使用小端模式,不同的设计哲学导致存储方式的差异。数据访问效率
小端模式中,低地址存放数据的低位字节,适合直接截取低位数据(如将32位整数转为16位整数时无需调整地址)。网络传输标准
网络协议(如TCP/IP)规定使用大端模式(网络字节序),确保不同设备间的数据解析一致性。
实际应用中的影响
跨平台数据传输
若未统一字节序,不同设备间传输数据会导致解析错误。
- 一个使用小端的设备向大端设备发送数据
0x12345678,接收方会错误解析为0x78563412。 - 解决方案:传输前转换为网络字节序(大端),使用
htonl()、ntohl()等函数(C语言标准库)。
文件格式与协议解析
- 文件格式:JPEG、PNG等图像文件使用大端模式存储数据。
- 通信协议:Modbus、HTTP/2等协议严格规定字节序,解析错误可能导致协议失效。
调试与内存分析
通过内存地址查看数据时,需明确当前系统的字节序。
- 在GDB调试器中查看内存值
0x78 0x56 0x34 0x12,若系统是小端,实际表示的整数是0x12345678。
如何判断当前系统的字节序?
通过简单的代码即可检测:
#include <stdio.h>
int main() {
int num = 1;
char *ptr = (char*)#
printf(*ptr == 1 ? "Little-Endian" : "Big-Endian");
return 0;
}
如果输出Little-Endian,则低地址存放的是低位字节(小端);反之则为大端。
大小端的优缺点对比
| 特性 | 大端模式 | 小端模式 |
|---|---|---|
| 可读性 | 内存值与书写顺序一致,便于人工解析 | 内存值与书写顺序相反 |
| 数据截取效率 | 需计算偏移量获取低位数据 | 直接取低地址获得低位数据 |
| 硬件设计复杂度 | 电路设计相对复杂 | 电路设计简单,适合低功耗场景 |
| 主流应用场景 | 网络协议、部分嵌入式系统 | x86/x64处理器、大多数现代操作系统 |
常见误区与注意事项
字符顺序 ≠ 字节顺序
大小端仅影响多字节数据的存储顺序,字符串(字符数组)的存储始终按写入顺序排列。编程语言中的处理差异
- C/C++等底层语言需要开发者显式处理字节序。
- Java、Python等高级语言屏蔽了字节序差异,但在跨语言交互时仍需注意。
浮点数的特殊问题
浮点数的存储不仅涉及字节序,还与IEEE 754标准相关,需同时考虑尾数、指数位的解析。
大小端模式的选择是计算机系统设计的经典权衡问题,没有绝对优劣之分,理解其原理后,开发者可以:
- 避免跨平台数据传输时的错误
- 优化内存敏感型应用的性能
- 正确解析复杂文件格式或通信协议
在实际项目中,建议通过标准化数据格式(如JSON、Protobuf)或显式转换函数规避字节序问题,提升代码的健壮性。
引用说明
- 《深入理解计算机系统》(原书第3版),Randal E. Bryant, David R. O’Hallaron 著
- IEEE 754-2008 浮点数算术标准
- RFC 1700 – 网络字节序定义