
上一篇
GPU并行计算服务器优势解析如何选择高性能计算服务器提升效率
GPU并行运算服务器的核心特点解析
在数字化进程加速的今天,GPU并行运算服务器已成为高性能计算(HPC)、人工智能(AI)、科学模拟等领域的核心基础设施,相较于传统CPU服务器,其独特的设计与架构使其在处理复杂任务时展现出显著优势,以下从技术特性、应用场景及行业价值三个维度,详细解析GPU并行运算服务器的关键特点。
核心技术特点
高性能计算能力
GPU(图形处理器)专为并行计算设计,拥有数千个计算核心(如NVIDIA A100的6912个CUDA核心),可同时处理海量数据,以单精度浮点运算为例,高端GPU的算力可达数十TFLOPS(每秒万亿次运算),远超CPU的百倍以上,尤其适合矩阵运算、深度学习等密集型任务。大规模并行处理架构
通过SIMT(单指令多线程)架构,GPU能够同时执行大量线程任务,在训练深度神经网络时,GPU可并行处理数百万个参数更新,显著缩短训练周期,根据NVIDIA测试,使用GPU集群可将传统训练时间从数周压缩至几小时。高能效比
GPU在单位功耗下的计算效率更高,以NVIDIA H100为例,其FP8精度下的算力为4000 TFLOPS,而功耗仅为700W,对比传统CPU集群,完成相同任务可降低50%以上的能源成本。
灵活的可扩展性
GPU服务器支持多卡互联(如NVLink、PCIe 5.0技术),可通过集群化部署实现算力线性扩展,Meta AI Research采用超8000块GPU构建的集群,支持千亿参数模型的训练。专用硬件加速功能
现代GPU集成Tensor Core、RT Core等专用单元,针对性优化AI推理、光线追踪等任务,NVIDIA的Tensor Core在混合精度计算中可提供高达125 TFLOPS的算力。
典型应用场景
人工智能与深度学习
- 模型训练:GPU加速ResNet-50训练至90%精度仅需15分钟(基于DGX A100)。
- 推理部署:支持实时图像识别(如自动驾驶)、自然语言处理(如ChatGPT类应用)。
科学计算与工程仿真
- 气候模拟:欧洲中期天气预报中心(ECMWF)使用GPU集群将预测速度提升20倍。
- 流体力学:ANSYS Fluent借助GPU加速,仿真时间从数天缩短至数小时。
图形渲染与虚拟化
- 影视特效:迪士尼使用GPU服务器将每帧渲染时间从分钟级降至秒级。
- 云游戏:NVIDIA GeForce NOW支持4K 120Hz流式传输,延迟低于20ms。
金融建模与数据分析
- 高频交易:GPU加速蒙特卡洛模拟,将风险评估计算速度提升100倍。
- 大数据处理:支持实时分析PB级数据(如社交网络用户行为)。
行业价值与趋势
推动科研创新
GPU服务器助力CERN大型强子对撞机每秒处理PB级数据,加速粒子物理研究;在基因测序领域,Broad Institute通过GPU将全基因组分析时间从30小时减至20分钟。经济效益显著
IDC数据显示,企业采用GPU服务器可使AI项目部署成本降低40%,投资回报周期缩短至12-18个月。技术融合趋势
- 异构计算:CPU+GPU协同架构(如AMD Instinct MI300)进一步优化资源分配。
- 绿色计算:液冷GPU服务器(如HPE Apollo 6500)将PUE值降至1.05以下,符合碳中和目标。
引用说明
- NVIDIA A100技术白皮书(2024)
- TOP500超算榜单(2024年6月)
- IEEE《高性能计算中的GPU加速》研究报告(2022)
- Meta AI Research公开数据集
- ANSYS Fluent官方性能测试报告(2021)
相关文章
-

GPU并行运算服务器优势_离线异步任务场景
-

GPU并行运算服务器方案_GPU调度
-
如何通过GPU并行运算服务器系统提升你的计算效率?
-
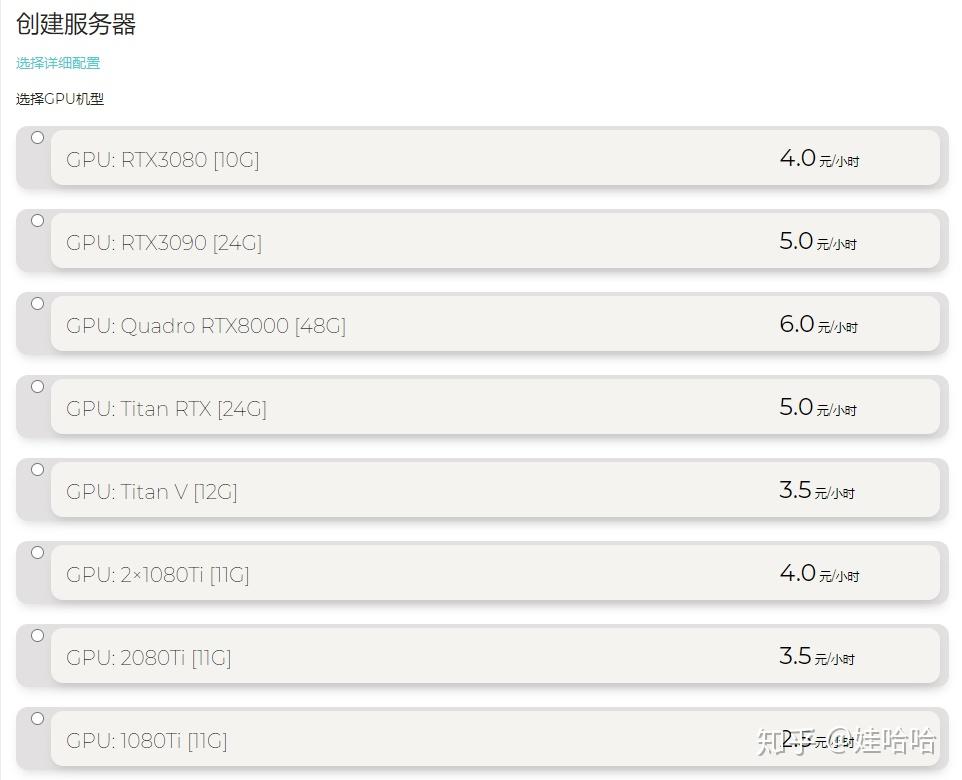
如何选择高性能GPU计算型服务器优化你的计算任务?
-
GPU并行运算主机服务_GPU调度
-
GPU并行运算主机软件_GPU加速型
-
GPU服务器虚拟化:高性能计算和资源利用的更佳选择 (gpu服务器 虚拟化)
-
服务器15核通常指的是拥有15个中央处理器(CPU)核心的服务器。在多核处理器架构中,一个物理处理器可以包含多个核心,每个核心能够独立执行任务。因此,一个15核的服务器意味着它有15个这样的处理单元,可以并行处理任务,提高计算效率和多任务处理能力。,这样的服务器配置适合于需要高计算性能和并行处理能力的应用场景,例如大数据处理、科学模拟、复杂的数据分析、以及为大量用户提供服务的高性能网站和应用等。
-
GPU并行运算服务器怎么选_镜像怎么选?








