
上一篇
datav支持哪些数据源类型全面解析
DataV支持多种数据源,包括MySQL、PostgreSQL、SQL Server等关系型数据库,CSV/Excel文件,以及API接口、JSON数据等,兼容阿里云生态的MaxCompute、AnalyticDB、HBase等云服务,同时可接入Kafka、WebSocket等实时数据流,满足多样化的可视化需求。
数据库类数据源
关系型数据库
- MySQL:通过JDBC或API直接连接,支持实时查询与更新。
- PostgreSQL:兼容性强,适用于复杂查询场景。
- SQL Server:支持Windows生态下的无缝集成。
- Oracle:提供高安全性配置,适配企业级数据仓库。
NoSQL数据库
- MongoDB:适用于非结构化数据(如JSON格式)的快速接入。
- Redis:支持缓存数据的实时可视化,提升大屏展示效率。
云服务与API数据源
主流云平台
- 阿里云(MaxCompute、RDS、Table Store等):原生兼容,支持一键授权访问。
- AWS(Redshift、S3):通过API或SDK实现跨平台数据拉取。
- 酷盾(CDB、COS):提供标准化接口,减少配置成本。
第三方API
- 支持RESTful API、GraphQL等多种协议,可接入天气数据、社交媒体统计、物联网设备数据等。
- 内置JSON/XML解析功能,自动将返回数据映射为可视化组件所需格式。
文件与静态数据
本地文件

- Excel/CSV:上传后自动解析为结构化数据,支持定时更新。
- JSON文件:适配复杂嵌套结构,适合自定义数据场景。
在线文件
支持通过URL链接加载云端存储的静态文件(如OSS、GitHub文件等)。
大数据与实时数据流
流式计算引擎
- Apache Kafka:实时消费消息队列数据,用于动态监控大屏。
- Flink/Spark Streaming:对接实时计算结果,展示秒级更新。
数据仓库
- Hive:支持海量离线数据分析结果的可视化。
- HBase:适配高并发读写场景,如用户行为日志展示。
其他数据源
自建服务
通过自定义接口(如企业内部系统)接入数据,需配置IP白名单或Token鉴权。
公共数据集
内置公开数据样例(如人口统计、经济指标),便于快速搭建原型。
数据源的安全性保障
- 访问控制:支持HTTPS加密传输、数据库账号权限隔离、IP访问限制等。
- 数据脱敏:敏感字段(如手机号、身份证)可在可视化前自动掩码处理。
- 审计日志:记录数据源的连接与操作历史,便于追溯与管理。
如何选择适合的数据源?
- 实时性要求高:优先选择数据库直连或实时数据流(如Kafka)。
- 数据量庞大:使用云数据仓库(MaxCompute、Redshift)或Hive。
- 快速原型验证:从Excel/CSV文件或公共数据集入手。
通过灵活的数据源支持,DataV能够覆盖从传统数据库到现代云服务的多样化场景,满足不同行业对数据可视化的深度需求,如需进一步了解某类数据源的配置细节,可访问DataV官方文档或参考阿里云技术指南。
引用说明参考DataV官方技术文档及阿里云产品白皮书,数据源支持列表以最新版本为准。
相关文章
-

MySQL表格数据库数据类型支持哪些数据源版本?
-
MySQL 2.9.3.300支持哪些数据源进行表格数据类型的导出?
-

MySQL仓库数据库支持哪些数据源版本?
-
VPS类型全解析:从共享型到独立型,不同类型如何选择? (vps类型)
-

MySQL属于哪种类型的数据库?它支持哪些数据库类型?
-
MySQL支持哪些数据库类型?如何查看当前使用的数据库类型?
-
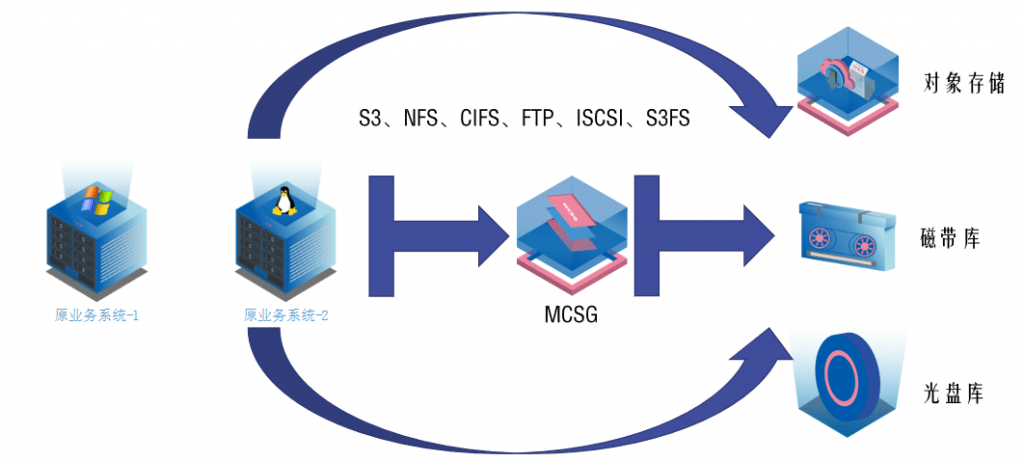
存储网关支持哪些协议?全面解析其兼容性与应用场景
-

Java switch语句支持哪些数据类型?
-

What are the key features and benefits of using a MySQL database for data management?








