
上一篇
Dataphin 智能数据构建与管理使用指引
Dataphin是阿里云提供的智能数据构建与管理平台,支持企业一站式完成数据集成、开发、质量监控及资产治理,通过规范化建模与自动化流程,助力用户高效管理数据资产,提升数据价值与安全性,降低运维成本,为业务决策提供可靠数据支撑。
Dataphin 智能数据构建与管理使用指引
在数据驱动的时代,企业高效管理数据资产、实现数据价值转化的需求愈发迫切,阿里云推出的 Dataphin 作为智能数据构建与管理平台,通过标准化、自动化的能力,帮助企业快速搭建数据中台,提升数据治理效率,以下从功能、使用场景、操作流程及最佳实践等维度为您提供详细指引。
Dataphin 的核心功能
智能数据建模
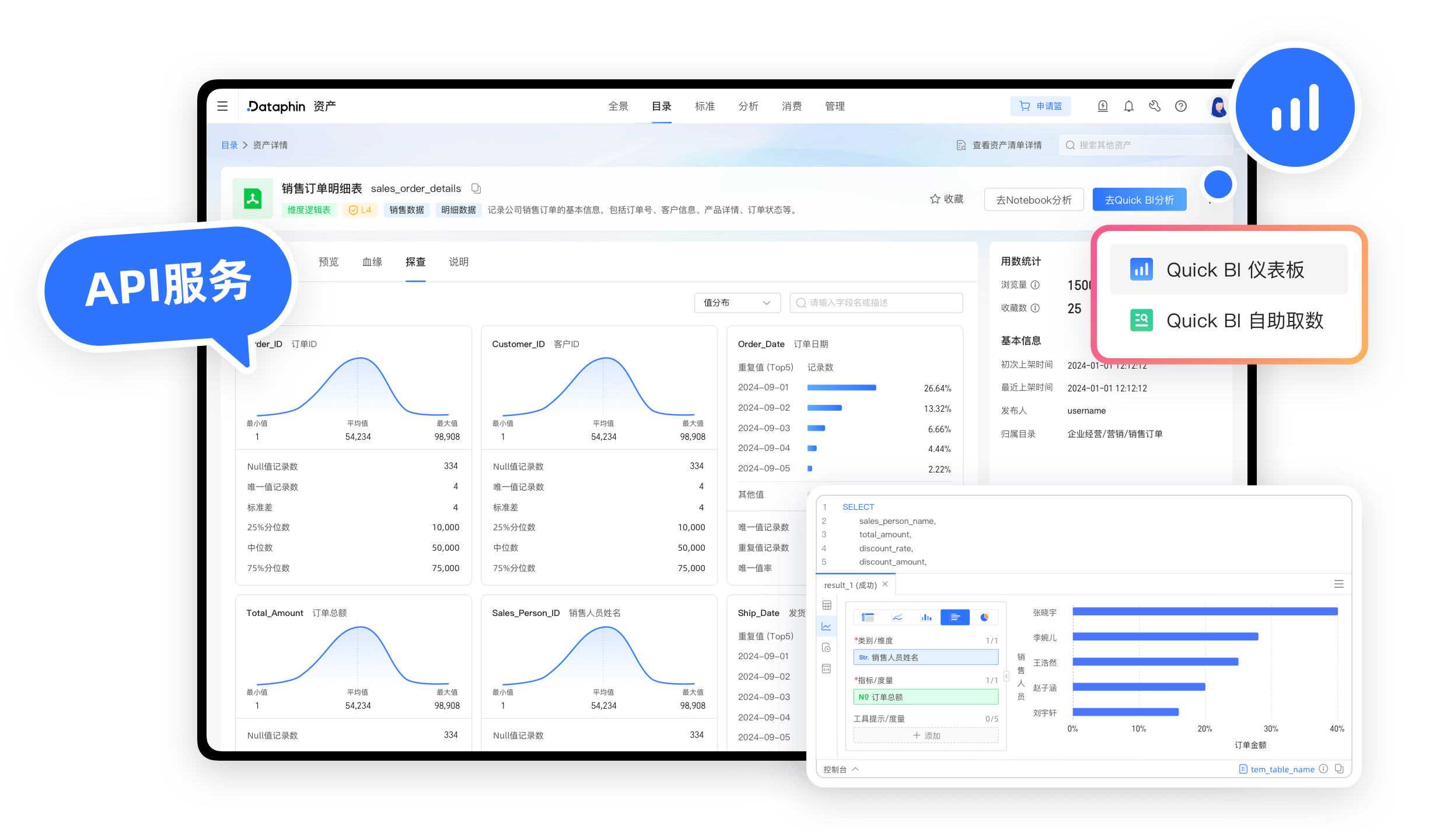
基于行业标准(如维度建模、数据仓库 3.0),提供可视化建模工具,支持从业务场景出发定义数据模型,自动生成表结构与ETL逻辑,降低技术门槛。- 示例:通过拖拽方式构建“用户行为分析模型”,自动生成用户画像表与关联规则。
一站式数据集成
支持 50+ 数据源(如 MySQL、Kafka、API 等)的实时/离线数据同步,内置数据清洗、去重、转换规则,确保数据入湖的准确性与一致性。自动化数据治理
- 数据质量监控:自定义校验规则(如空值率、唯一性),实时告警异常数据。
- 元数据管理:自动追踪数据血缘关系,快速定位问题源头。
- 敏感数据脱敏:通过规则引擎实现隐私字段加密,满足 GDPR 等合规要求。
数据服务化输出
将处理后的数据封装为 API 或数据服务,供下游业务系统(如 BI 工具、营销平台)调用,缩短数据到应用的链路。
典型使用场景
企业级数据中台搭建
跨部门整合分散的业务系统数据,构建统一的数据资产目录,解决“数据孤岛”问题。
实时分析场景支持
电商大促期间,通过实时数据同步与计算,实现库存监控、流量预警等场景的秒级响应。数据资产价值挖掘
结合机器学习算法,基于历史数据生成用户分群模型,赋能精准营销。
Dataphin 操作流程
创建项目与数据源
- 登录 Dataphin 控制台,新建项目并绑定计算引擎(如 MaxCompute)。
- 配置数据源连接,测试连通性后完成接入。
数据建模与开发
- 步骤 1:在“数据架构”模块定义主题域(如交易、用户)。
- 步骤 2:通过“维度建模”设计事实表与维度表,配置字段类型及关联关系。
- 步骤 3:系统自动生成代码,提交至调度系统执行。
数据质量配置
- 在“运维中心”设置表级/字段级质量规则,如“订单金额不得为负”。
- 设置告警方式(邮件/钉钉),配置触发阈值。
数据服务发布
- 在“数据服务”模块创建 API,选择输出表或 SQL 查询结果。
- 配置鉴权方式(如 AppKey),发布至 API 网关供外部调用。
最佳实践与优化建议
模型设计规范
- 遵循“高内聚、低耦合”原则,避免宽表冗余。
- 使用分层设计(ODS → DWD → DWS → ADS),提升复用性。
性能优化策略
- 分区设置:按日期、地域分区,减少全表扫描。
- 生命周期管理:自动清理过期冷数据,降低存储成本。
安全与权限管控
- 通过“角色-项目-表”三级权限体系,限制敏感数据的访问范围。
- 定期审计操作日志,防范数据泄露风险。
Dataphin 的优势对比
| 对比维度 | 传统数据开发 | Dataphin 方案 |
|---|---|---|
| 开发效率 | 手动编写 SQL/ETL,耗时易错 | 可视化建模,代码生成效率提升 70% |
| 数据质量 | 依赖人工校验,滞后性强 | 实时监控 + 自动化修复 |
| 协作能力 | 多团队协作困难 | 支持角色分工(开发、运维、分析师) |
常见问题解答
Q1:如何解决数据同步延迟?
- 检查源端数据库负载,优化增量同步策略(如基于 Binlog 的实时捕获)。
- 调整任务并发度,或联系阿里云技术支持进行链路诊断。
Q2:能否自定义数据质量规则?
- 支持 SQL 自定义规则,用户年龄字段需在 1-100 之间”。
Q3:是否支持私有化部署?
- 提供公有云、混合云、专有云(Apsara Stack)多种部署模式。
引用说明 参考阿里云官方文档《Dataphin 技术白皮书》及行业实践案例,数据来源于 Gartner 2024 年数据管理领域报告。
通过以上指引,企业可快速掌握 Dataphin 的核心能力,实现数据资产的标准化管理与智能化应用,为业务决策提供坚实支撑。
相关文章
-

Dataphin 智能数据构建与管理详细介绍
-
Dataphin智能数据构建与管理支持免费试用吗
-

如何高效掌握Dataphin智能数据构建与管理技巧?
-
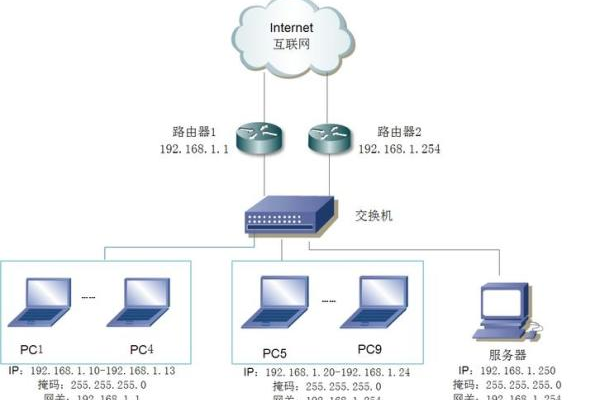
网络服务器搭建与管理技巧分享 (网络服务器搭建与管理)
-

processes_镜像保存时报错“there are processes in 'D' status, please check process status using 'ps aux' and kill all the 'D' status processes”或“Buildimge,False,Error response from daemon,Cannot pause container xxx”如何解决?
-
大数据智能分析_使用智能分析助手进行智能数据分析
-

ai 智能 大数据 分析_使用智能分析助手进行智能数据分析
-

What are the key features and benefits of using a MySQL database for data management?
-
微信隐私保护指引是什么?微信隐私保护指引内容解答








