
上一篇
存货初始数据仓库代码
存货初始数据仓库代码主要用于构建企业存货数据存储与分析体系,涵盖数据抽取、清洗转换、加载(ETL)流程,支持多源异构数据整合,核心模块包括数据模型设计(如维度建模)、存储架构优化、历史数据回溯及数据质量校验,为存货管理提供统一、高效的决策支持基础。
存货初始数据仓库代码的设计与实现
在企业数据管理中,存货数据的存储与分析是供应链、财务及运营决策的核心,构建初始数据仓库时,需遵循规范化、可扩展性、高可用性原则,同时结合业务需求设计逻辑模型与物理结构,以下从技术实现、代码示例及最佳实践角度展开说明。
数据仓库设计流程
需求分析
- 明确存货数据的业务场景(如出入库记录、库存量、SKU属性)。
- 确定数据源类型(关系型数据库、Excel、ERP系统)。
逻辑建模
- 星型模型:以“存货事实表”为中心,关联维度表(时间、仓库、产品类别)。
- 字段设计示例:
-- 事实表(Fact_Inventory) CREATE TABLE Fact_Inventory ( InventoryID INT PRIMARY KEY, ProductID INT, WarehouseID INT, DateKey INT, Quantity INT, Cost DECIMAL(10,2), FOREIGN KEY (ProductID) REFERENCES Dim_Product(ProductID), FOREIGN KEY (WarehouseID) REFERENCES Dim_Warehouse(WarehouseID), FOREIGN KEY (DateKey) REFERENCES Dim_Date(DateKey) );
物理建模

- 选择存储引擎(如列式存储优化查询性能)。
- 分区策略:按时间或仓库分区。
核心代码实现
ETL(数据抽取、转换、加载)
Python示例(使用Pandas和SQLAlchemy):
import pandas as pd from sqlalchemy import create_engine # 抽取数据 source_conn = create_engine('mysql://user:pass@source_host/db') df = pd.read_sql("SELECT * FROM raw_inventory", source_conn) # 数据清洗 df['DateKey'] = pd.to_datetime(df['Date']).dt.strftime('%Y%m%d').astype(int) df = df.dropna(subset=['Quantity']) # 加载到数据仓库 dw_conn = create_engine('postgresql://user:pass@dw_host/warehouse') df.to_sql('Fact_Inventory', dw_conn, if_exists='append', index=False)
索引与优化
- 为高频查询字段(如
ProductID、DateKey)创建索引:CREATE INDEX idx_fact_inventory_product ON Fact_Inventory (ProductID); CREATE INDEX idx_fact_inventory_date ON Fact_Inventory (DateKey);
- 为高频查询字段(如
数据治理与安全
数据质量监控
- 通过SQL约束确保数据完整性:
ALTER TABLE Fact_Inventory ADD CHECK (Quantity >= 0);
- 通过SQL约束确保数据完整性:
权限管理
- 按角色分配访问权限(如仓库管理员只读权限):
GRANT SELECT ON Fact_Inventory TO warehouse_manager;
- 按角色分配访问权限(如仓库管理员只读权限):
数据加密
使用TLS传输数据,对敏感字段(如成本价)加密存储。
验证与测试
- 单元测试
验证ETL脚本的输入输出一致性(如记录数、字段映射)。
- 性能测试
模拟高并发查询,优化索引和分区策略。
初始存货数据仓库的代码实现需围绕业务需求与技术规范展开,确保模型清晰、代码可维护、数据安全,定期进行数据质量审查与性能调优,可支撑长期业务分析需求。
引用说明
- 数据仓库设计原则参考《数据仓库工具箱》(Kimball Group)。
- ETL代码示例基于Pandas官方文档与SQLAlchemy最佳实践。
- 安全建议遵循OWASP数据安全指南。
相关文章
-

数据仓库的含义及特点,数据仓库具有哪些特点(数据仓库的含义及特点,数据仓库具有哪些特点呢)
-
以下几个疑问句标题可供选择,,创城数据仓库的工资待遇究竟如何?,创城数据仓库工资待遇怎么样?,谁了解创城数据仓库的工资待遇情况?
-

mysql数据库代码_Mysql数据库这篇文章可能涉及MySQL数据库的编程、管理或优化等方面的内容。根据这些信息,我们可以为文章生成一个原创的疑问句标题,例如,,如何编写高效的MySQL数据库代码以提升性能?,不仅提出了一个问题,而且暗示了文章内容可能包含关于编写高效MySQL代码和提升数据库性能的技巧与建议。
-
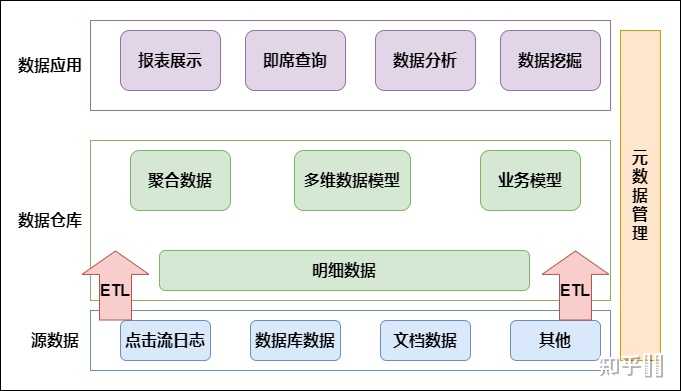
大数据和数据仓库有何区别?探索数据仓库服务的本质
-
大数据是数据仓库么_什么是数据仓库服务
-
大数据就是数据仓库_数据仓库
-
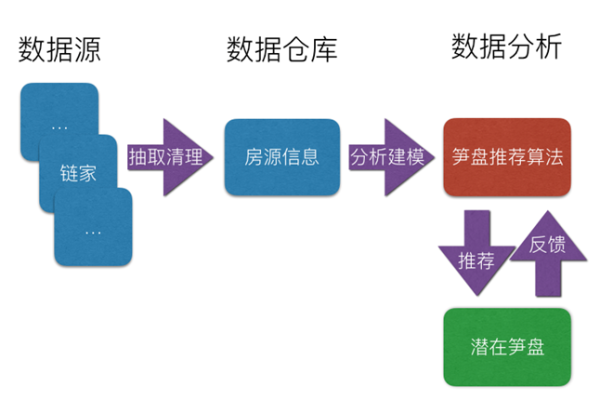
大数据资源数据仓库_数据仓库
-

大数据数据仓库_数据仓库
-
数据仓库真的不会随时间变化吗?——探讨DJ数据仓库的稳定性与动态性








