
上一篇
datahub数据类型
DataHub是一种数据管理平台,支持多种数据类型,包括数据集、表格、仪表板、数据管道、标签及元数据等,其核心功能覆盖结构化数据存储、可视化分析、流程自动化及协作管理,帮助用户实现高效数据治理、跨团队协作与实时监控,提升企业数据资产的可发现性和可用性。
在数据管理领域,理解平台支持的数据类型是构建高效数据生态系统的关键,DataHub作为当前主流的元数据管理工具,其数据类型设计体现了对现代企业需求的深度洞察,以下内容基于DataHub官方技术文档及实际应用场景整理,为从业者提供专业参考。
核心数据类型体系
DataHub通过实体(Entity)模型构建数据类型框架,每个实体代表一类元数据对象,主要实体类型包括:
- 数据集(Dataset)
- 结构化数据表(Tables):支持关系型数据库(MySQL/Oracle等)、数据仓库(Snowflake/Redshift)
- 文件存储(Filesets):包含HDFS目录、S3存储桶等非结构化数据载体
- 流式数据(Streams):Kafka Topic、Kinesis Stream等实时数据管道
- 数据资产(Data Assets)
- 机器学习模型(ML Models):TensorFlow、PyTorch等框架生成的模型文件
- 仪表盘(Dashboards):Tableau、Looker等BI工具产物
- 数据流水线(Pipelines):Airflow DAG、Spark作业等加工逻辑
元数据扩展类型
通过Schema Registry机制,DataHub支持用户自定义类型扩展:

- 技术元数据
- 字段级血缘(Column Lineage)
- 分区信息(Partition Spec)
- 存储格式(Parquet/ORC/AVRO)
- 业务元数据
- 数据域(Domain)
- 术语表(Glossary Terms)
- 数据质量规则(Data Quality Rules)
关系型数据类型
通过元数据图谱(Metadata Graph)建立关联:
| 关系类型 | 说明 | 示例场景 |
|---|---|---|
| 血缘关系 | 数据加工链路可视化 | 报表字段溯源到原始表 |
| 归属关系 | 资产组织架构映射 | 表所属数据库→集群→部门 |
| 使用关系 | 数据消费追踪 | BI看板→SQL查询→底层表 |
数据类型选择建议
结构化优先原则
建议将核心业务数据建模为结构化数据集,便于实施数据治理(Data Governance)和访问控制(Access Control)动态扩展考量
对于实验性数据资产,建议采用半结构化(JSON Schema)或非结构化(Fileset)类型,保留灵活演进空间元数据完整度
关键业务表应包含至少三层元数据:
- 技术属性(存储格式/分区方式)
- 业务属性(负责人/敏感等级)
- 运营属性(访问频次/存储成本)
技术演进趋势
2024年DataHub新增支持的特征类型显示:
- 向量数据库(VectorDB)嵌入类型
- LLM模型元数据标准(Model Cards)
- 实时数据血缘(Streaming Lineage)
这些演进反映出数据平台正在向AI就绪(AI-Ready)架构迈进,数据类型体系逐步覆盖从传统结构化数据到新兴AI资产的完整生命周期管理。
来源:*
- DataHub官方文档(2024年11月版)
- ACM数据管理国际会议论文《Metadata Architecture in Modern Data Stack》
- Gartner《2024数据管理技术成熟度报告》
相关文章
-
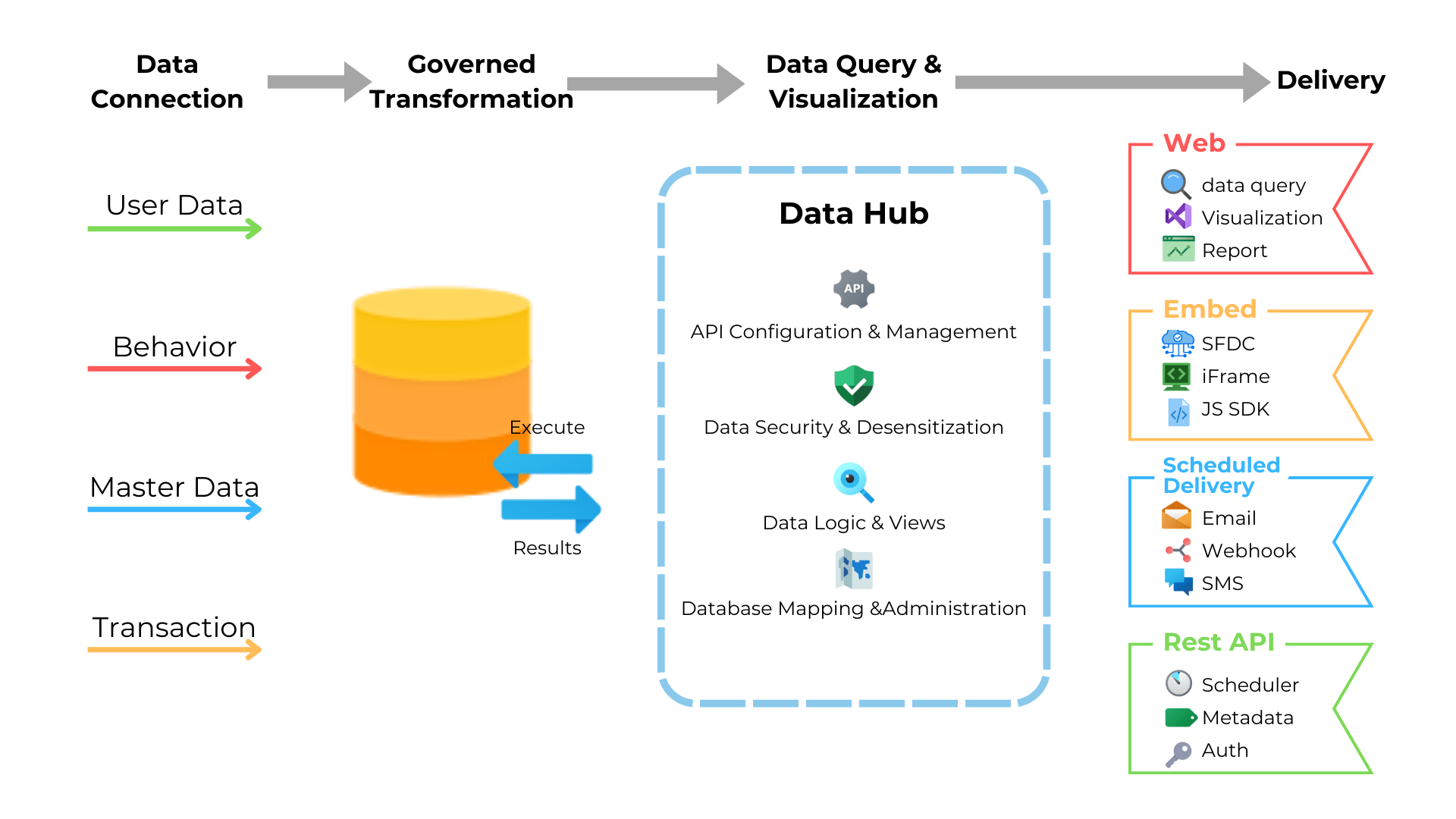
如何高效实现DataHub数据写入?
-
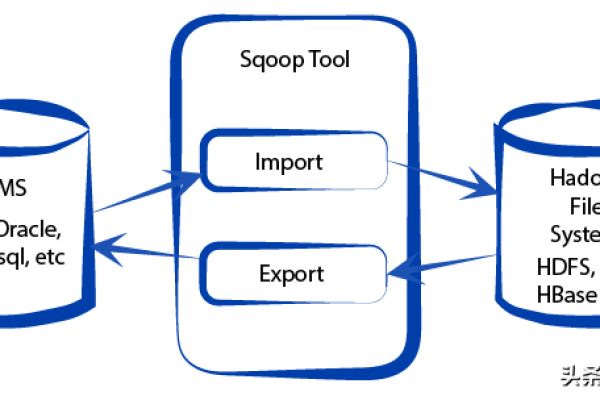
如何实现从PolarDB MySQL到Datahub的数据同步?
-
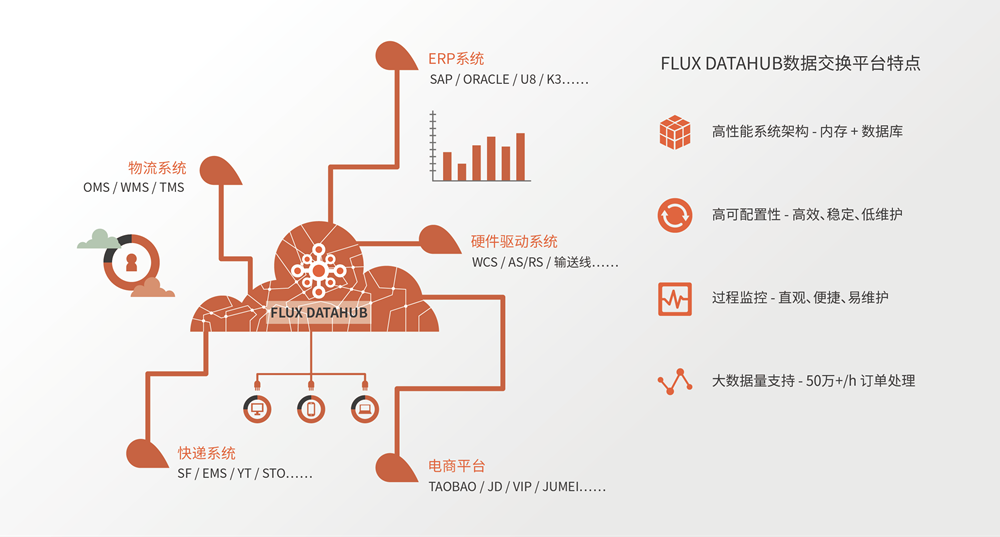
datahub实时数据仓库
-
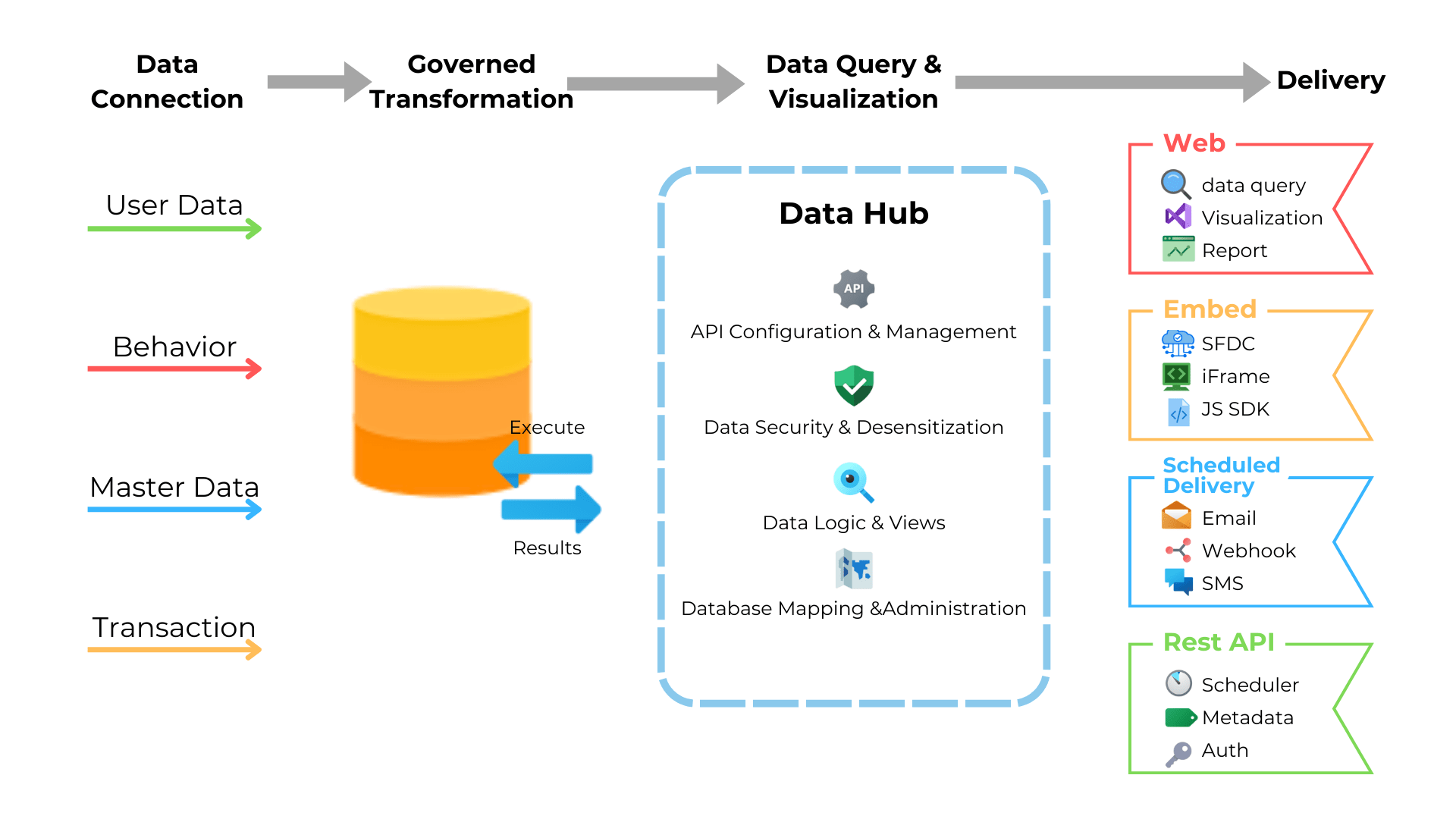
如何利用DataHub高效获取数据?
-
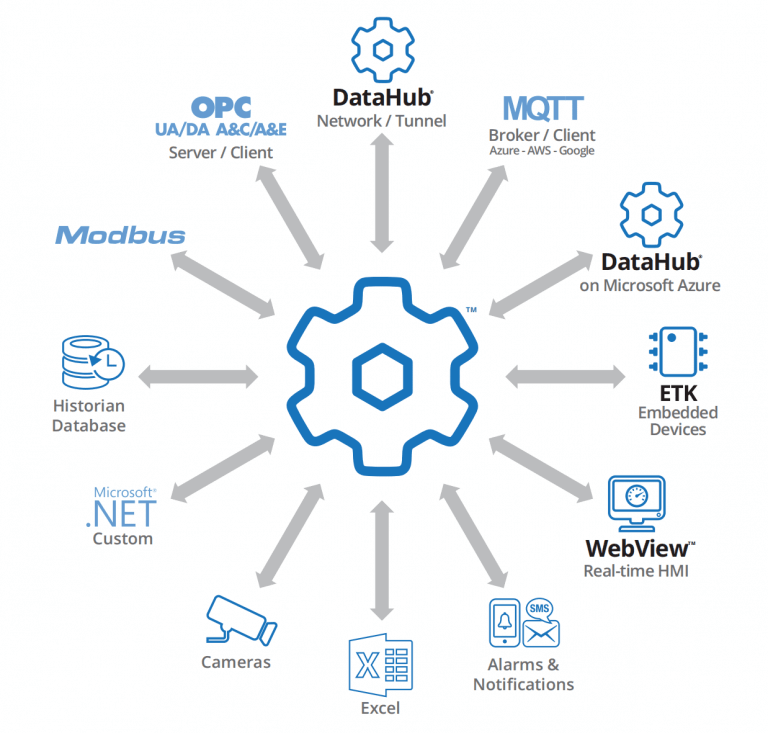
datahub接入iot
-

What are the key features and benefits of using a MySQL database for data management?
-

processes_镜像保存时报错“there are processes in 'D' status, please check process status using 'ps aux' and kill all the 'D' status processes”或“Buildimge,False,Error response from daemon,Cannot pause container xxx”如何解决?
-
探索DataType,数据类型的奥秘与应用








