上一篇
bp神经网络泛化
BP神经网络通过误差反向传播算法调整网络参数,其泛化能力指模型对未知数据的预测性能,泛化效果受训练数据质量、网络结构复杂度及正则化方法影响,合理设计隐藏层节点和采用交叉验证可避免过拟合,提升模型在分类、回归等任务中的实际应用表现。
在人工智能和机器学习的快速发展中,BP神经网络(误差反向传播神经网络)因其强大的非线性拟合能力被广泛应用于图像识别、自然语言处理等领域,如何确保训练好的模型在未知数据上也能保持高精度(即泛化能力),是算法工程师和研究者关注的焦点,以下从原理、挑战到实践方法,全面解析BP神经网络的泛化问题。
什么是BP神经网络的泛化能力?
泛化能力指模型对未见过的数据的预测能力,一个识别猫狗的神经网络,如果在训练集上准确率99%,但对新图片的准确率骤降至70%,说明其泛化能力不足,BP神经网络的泛化能力直接决定了模型的实用价值。
关键公式:
神经网络的输出误差 ( E ) 可表示为:
[
E = frac{1}{2N} sum_{i=1}^{N} (y_i – hat{y}_i)^2
]
( y_i ) 为真实值,( hat{y}_i ) 为预测值,泛化能力的核心在于控制误差 ( E ) 在训练集和测试集上的差异。

影响泛化的四大核心因素
数据质量与分布
- 数据量不足:样本过少会导致模型“记忆”而非“学习”。
- 噪声干扰:标注错误或数据采集误差会误导权重更新。
- 分布偏移:训练集与真实场景的数据分布差异(例如训练数据中猫图片多为室内,而实际需要识别户外猫)。
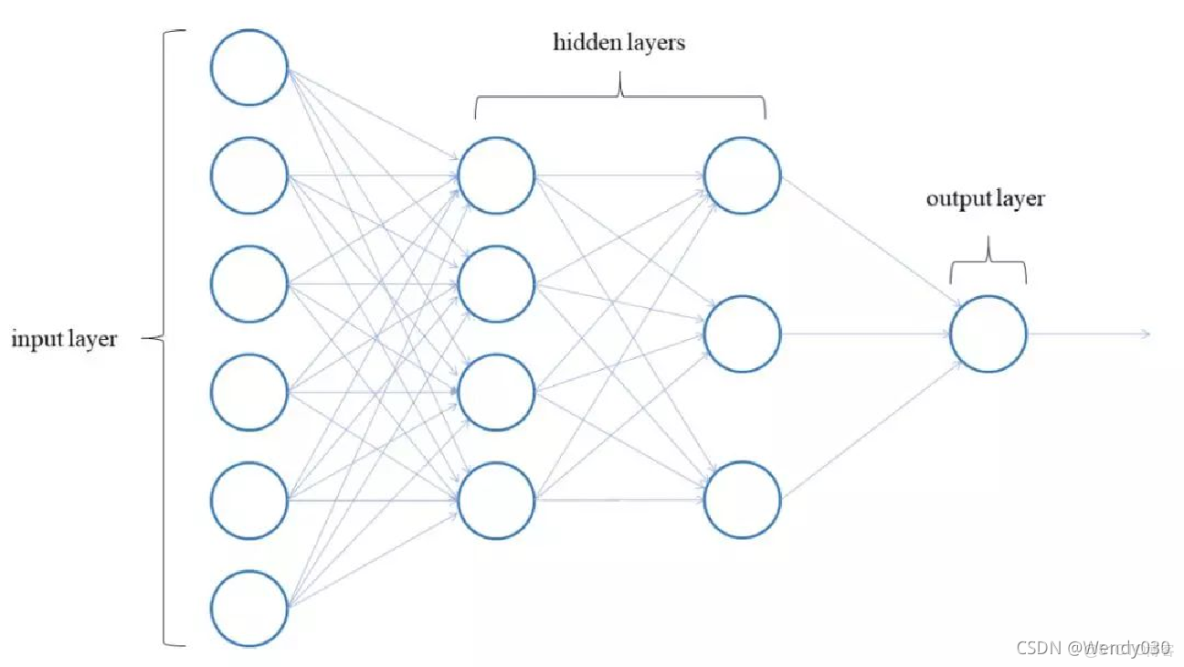
模型复杂度
- 过拟合:网络层数过多或神经元数量过大时,模型会过度拟合训练数据中的噪声。
- 欠拟合:模型结构过于简单时,无法捕捉数据中的有效特征。
训练策略
- 学习率设置不当(过高导致震荡,过低收敛缓慢)。
- 未使用正则化或早停(Early Stopping)机制。
评估方法缺陷
仅依赖训练集准确率评估模型,忽略验证集或交叉验证(Cross-Validation)。
提升泛化能力的6大实践方法
| 方法 | 原理 | 应用示例 |
|---|---|---|
| 数据增强 | 扩大数据集多样性,模拟真实场景 | 图像旋转、裁剪;文本同义词替换 |
| 正则化 | 限制权重幅度,防止过拟合 | L2正则化(权重衰减)、Dropout层 |
| 早停法 | 在验证集误差上升时终止训练 | 监测验证集Loss曲线 |
| 交叉验证 | 充分利用数据,评估模型稳定性 | K折交叉验证(K=5或10) |
| 网络结构优化 | 平衡模型复杂度与任务需求 | 使用残差连接(ResNet)减少梯度消失 |
| 集成学习 | 结合多个模型的预测结果,降低方差 | Bagging、Stacking |
泛化能力的评估指标
- 测试集准确率:最直观的指标,但需确保测试集与真实场景一致。
- 混淆矩阵:分析分类错误的具体类型(如假阳性、假阴性)。
- ROC曲线与AUC值:评估模型在不同阈值下的泛化性能,适用于类别不平衡数据。
示例:
某医疗影像诊断模型中,若测试集AUC值为0.92,但实际部署时发现对低分辨率图片识别率低,说明数据分布假设存在偏差。
行业案例:泛化能力的关键作用
- 自动驾驶:特斯拉的神经网络需适应不同光照、天气条件下的道路识别,通过合成雨雾图像增强泛化性。
- 金融风控:蚂蚁金服使用对抗训练(Adversarial Training),让模型抵抗反面伪造的交易数据。
BP神经网络的泛化能力是模型成功落地的“生死线”,通过数据优化、正则化技术、科学评估等手段,可显著提升模型在未知场景中的表现,工程师需始终遵循“奥卡姆剃刀原则”——在满足任务需求的前提下,选择最简单的模型结构。
引用说明
- 周志华. 《机器学习》. 清华大学出版社, 2016.
- Goodfellow I, Bengio Y, Courville A. Deep Learning. MIT Press, 2016.
- TensorFlow官方文档:https://www.tensorflow.org/
- Krizhevsky A, Sutskever I, Hinton G E. ImageNet Classification with Deep Convolutional Neural Networks. NIPS 2012.