上一篇
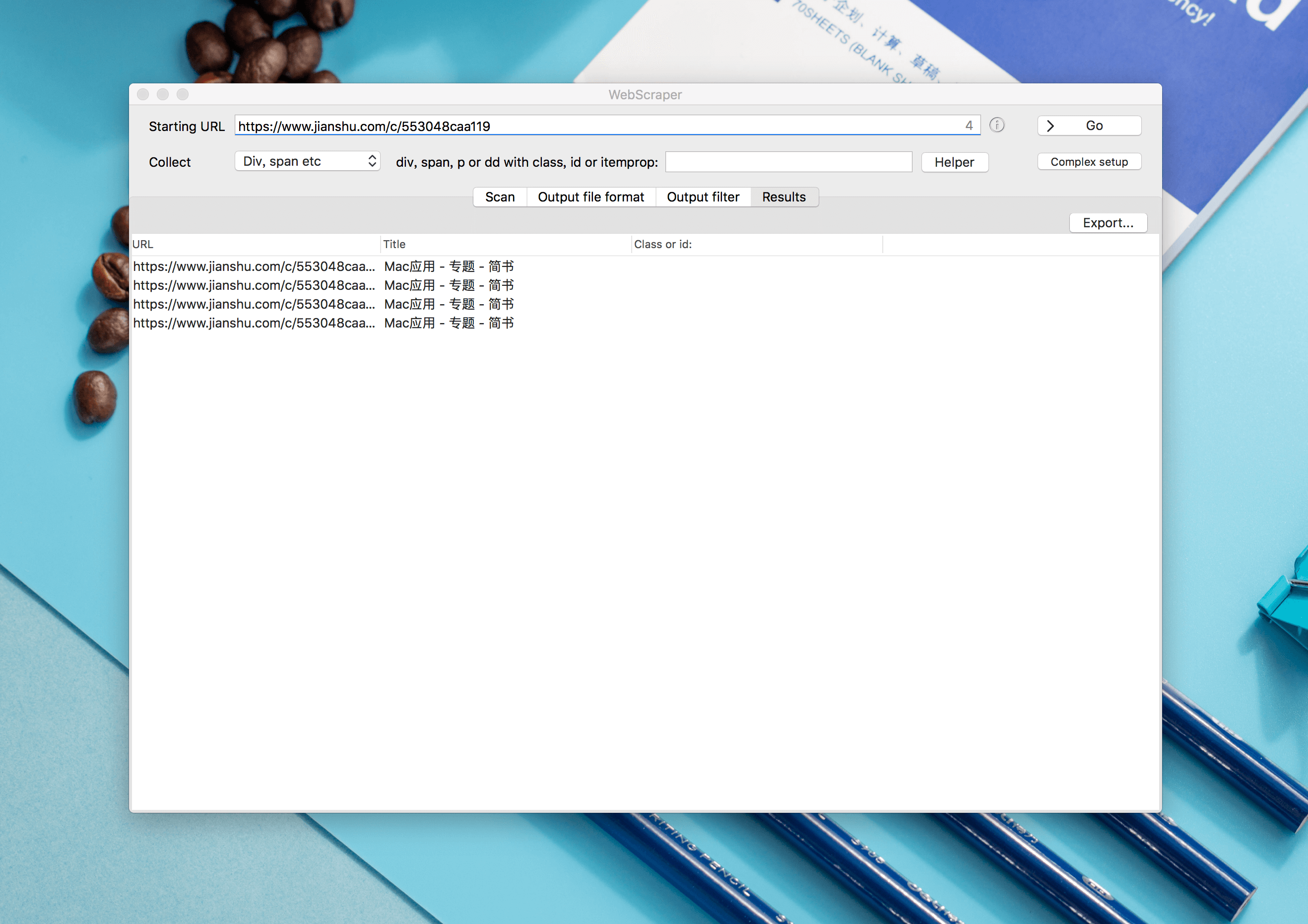
从网站抓取数据
从网站抓取数据是通过自动化工具或编程脚本提取网页信息的过程,常用于市场分析、研究或商业决策,技术涉及模拟浏览器访问、解析HTML结构及处理反爬机制,需遵守目标网站的使用条款与法律法规,确保数据获取合法合规,高效抓取通常依赖Python库或专业爬虫框架实现。
网站数据抓取的合法性与技术实践指南
在数字化时代,数据已成为企业和个人的重要资产,通过抓取公开网站数据,可以辅助市场分析、竞品研究或内容聚合等需求,这一行为需严格遵循法律法规与平台规则,以下从合规性、技术实现及优化建议三方面展开说明,帮助用户安全高效地完成数据抓取。
法律合规性:避免触碰红线
遵守《网络安全法》与《数据安全法》
- 明确禁止抓取涉及个人隐私、商业秘密或国家机密的数据。
- 抓取前需确认目标数据的公开范围,例如用户未登录即可访问的内容通常视为可抓取。
尊重Robots协议
- 网站的
robots.txt文件规定了爬虫的访问权限,例如禁止抓取某些目录或限制频率。 - 违反协议可能被网站封禁IP,甚至面临法律风险。
- 网站的
规避反爬机制时的底线
- 禁止破解验证码、伪造用户身份(如模拟登录)或高频请求导致服务器瘫痪。
- 建议设置合理抓取间隔(如每秒1-2次),并标注爬虫身份(User-Agent)。
技术实现:高效且低风险的抓取方案
工具选择与示例
基础抓取:Python的
Requests库+BeautifulSoup,适合静态页面。import requests from bs4 import BeautifulSoup response = requests.get("https://example.com") soup = BeautifulSoup(response.text, 'html.parser')= soup.find('h1').text动态页面:使用
Selenium或Playwright模拟浏览器行为,抓取JavaScript渲染内容。大规模抓取:分布式框架如
Scrapy,支持自动处理并发、去重和存储。
数据清洗与存储
- 去除HTML标签、过滤重复项,使用正则表达式或
Pandas库结构化数据。 - 存储方案:MySQL/MongoDB(数据库)、CSV/JSON(轻量级文件)或云服务(如AWS S3)。
反反爬策略
- IP代理池:通过轮换IP(如使用付费代理服务)避免被封禁。
- 请求头伪装:模拟真实浏览器的Headers(Referer、Accept-Language等)。
- 分布式延迟:不同IP的爬虫节点设置随机请求间隔。
数据使用与SEO优化建议
内容发布的合规性
- 抓取的数据需经二次加工(如分析、整合),避免直接复制原站内容,防止侵权。
- 若涉及用户生成内容(UGC),需获得原作者授权。
符合百度算法的核心要点
- E-A-T原则(专业性、权威性、可信度):
- 标注数据来源,引用权威机构或研究报告(如“根据国家统计局数据显示”)。
- 聘请领域专家审核内容,或添加作者资质说明(如“本文由数据分析师团队编撰”)。 价值**:提供独家解读、趋势分析或可视化图表(如用Tableau生成),避免单纯堆砌数据。
- 用户体验:确保页面加载速度(压缩图片、懒加载)、适配移动端,并添加交互功能(数据筛选、下载)。
长期SEO维护
- 定期更新数据,例如月度行业报告,吸引搜索引擎重复抓取。
- 通过内部链接将数据页面与相关文章关联,提升权重。
- 使用百度站长平台提交链接,监控索引覆盖率与流量异常。
风险警示与伦理建议
- 禁止行为:突破付费墙、抓取社交平台用户非公开信息、干扰网站正常运行。
- 伦理责任:抓取数据用于公益研究(如疫情趋势分析)时,需平衡公共利益与隐私保护。
引用说明
- 《中华人民共和国网络安全法》第二十七条、第四十四条
- 百度搜索《网站SEO优化指南》2024版
- 欧盟《通用数据保护条例》(GDPR)第七条
- 示例代码参考Python官方文档(requests.readthedocs.io)