上一篇
从零学习深度学习
深度学习是机器学习的重要分支,通过构建多层神经网络模拟人脑机制实现复杂数据建模,学习路径涵盖数学基础、神经网络原理、反向传播算法及常用框架(如TensorFlow/PyTorch),需结合理论理解与实践项目(如图像识别、自然语言处理),逐步掌握模型设计、训练调优及工程部署能力。
什么是深度学习?
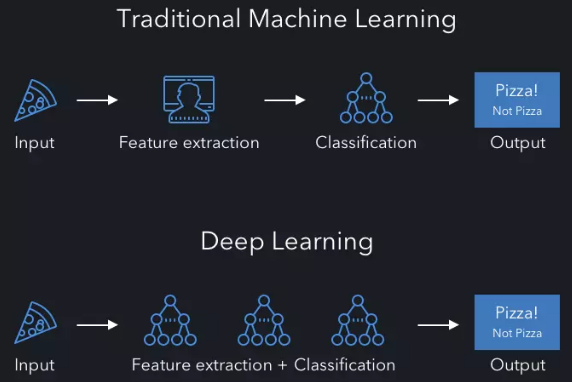
深度学习是人工智能(AI)的一个子领域,属于机器学习的范畴,它通过模拟人脑神经网络的运作方式,构建多层次的“神经网络”模型,从数据中自动提取特征并完成复杂任务,如图像识别、语音处理、自然语言理解等,与传统的机器学习相比,深度学习能处理更大规模的数据,并具备更强的特征学习能力。
为什么选择深度学习?
- 广泛应用:从医疗诊断到自动驾驶,深度学习技术已渗透到各行各业。
- 自动化特征提取:无需人工设计特征,模型能从数据中直接学习规律。
- 高性能:在图像、语音等领域,深度学习模型的表现远超传统算法。
从零开始的学习路径
第一步:掌握基础知识
数学基础
- 线性代数:矩阵运算、向量空间是理解神经网络的核心。
- 微积分:梯度下降等优化算法依赖导数知识。
- 概率统计:理解数据分布、损失函数设计的关键。
推荐资源:《深度学习》(花书)第2章、3Blue1Brown的数学视频。
编程基础
- Python:深度学习的主流语言,需熟悉NumPy、Pandas等库。
- 框架入门:PyTorch或TensorFlow,优先选择社区活跃的PyTorch。
第二步:理解核心概念
神经网络基础

- 神经元与激活函数:如Sigmoid、ReLU,决定神经元的输出。
- 前向传播与反向传播:数据如何流过网络并更新权重。
- 损失函数:衡量模型预测值与真实值的差距(如交叉熵、均方误差)。
经典模型架构
- CNN(卷积神经网络):专为图像处理设计,含卷积层、池化层。
- RNN(循环神经网络):处理序列数据(如文本、时间序列)。
- Transformer:当前自然语言处理的主流模型(如GPT、BERT)。
第三步:动手实践
从小项目开始
- 使用MNIST数据集训练手写数字识别模型。
- 用预训练模型(如ResNet)完成图像分类任务。
参与竞赛
- Kaggle:通过真实数据集的竞赛提升实战能力(如房价预测、图像分割)。
- 天池/AI Studio:国内平台,适合中文学习者。
复现论文
从经典论文(如AlexNet、Transformer)入手,理解模型细节。
第四步:深度学习进阶
优化技巧
- 正则化:防止过拟合(如Dropout、L2正则化)。
- 超参数调优:学习率、批量大小的调整方法。
领域拓展
- 计算机视觉:目标检测(YOLO)、图像生成(GAN)。
- 自然语言处理:文本生成、情感分析。
常见误区与避坑指南
- 忽视数学基础:跳过理论直接调参,可能导致无法理解模型原理。
- 盲目追求新模型:从基础模型(如全连接网络)开始更易掌握核心逻辑。
- 忽视调试工具:使用TensorBoard或WandB可视化训练过程。
推荐学习资源
- 课程:Andrew Ng《深度学习专项课程》(Coursera)、李沐《动手学深度学习》。
- 书籍:《Python深度学习》《深度学习入门:基于Python的理论与实现》。
- 社区:Stack Overflow、知乎专栏、GitHub开源项目。
引用说明
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
- LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep Learning. Nature, 521(7553), 436-444.
- PyTorch官方文档:https://pytorch.org/
- Kaggle竞赛平台:https://www.kaggle.com/
通过系统学习与实践,即使是零基础的学习者也能逐步掌握深度学习的核心技能。理论是基石,代码是工具,项目是试金石。