上一篇
c网络爬虫源码
“
python,import requests,from bs4 import BeautifulSoupurl = "http://example.com",response = requests.get(url),soup = BeautifulSoup(response.text, "html.parser"),print(soup.prettify()),“
C语言编写网络爬虫是一个复杂但有趣的过程,它涉及到网络编程、数据解析和多线程等多个方面,下面将详细阐述如何使用C语言编写一个简单的网络爬虫,包括其基本结构、关键代码片段以及可能遇到的问题和解决方案。
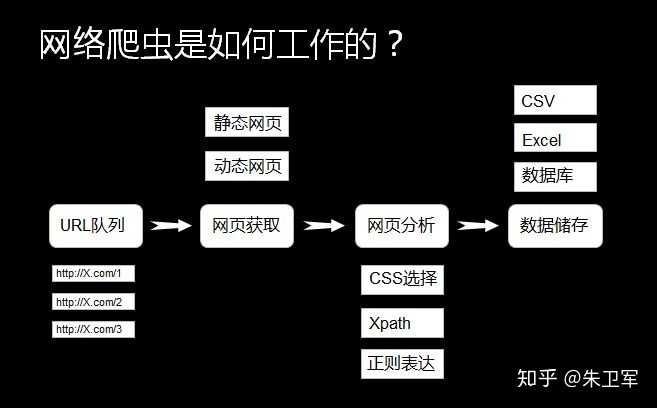
基本结构
1、初始化:设置必要的库和变量,如初始化libcurl库(如果使用的话),定义URL、代理服务器等。
2、发送HTTP请求:使用libcurl或其他网络库向目标网站发送HTTP请求,获取网页内容。

3、解析网页内容:根据网页的结构和所需数据,使用正则表达式或HTML解析库(如libxml2)来提取有用信息。
4、处理数据:对提取的数据进行进一步处理,如存储到文件、数据库或进行其他分析。
5、错误处理:添加必要的错误处理逻辑,确保程序在遇到异常情况时能够稳定运行。

6、多线程/异步处理:为了提高爬取效率,可以采用多线程或异步IO来同时处理多个请求。
关键代码片段
以下是使用libcurl库发送HTTP请求并获取网页内容的示例代码:

#include <stdio.h>
#include <curl/curl.h>
// 回调函数,用于处理接收到的数据
size_t write_data(void ptr, size_t size, size_t nmemb, FILE stream) {
size_t written = fwrite(ptr, size, nmemb, stream);
return written;
}
int main(void) {
CURL curl;
FILE fp;
CURLcode res;
char url = "http://example.com"; // 目标URL
char outfilename[FILENAME_MAX] = "output.html"; // 输出文件名
curl = curl_easy_init();
if (curl) {
fp = fopen(outfilename,"wb");
curl_easy_setopt(curl, CURLOPT_URL, url);
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, write_data);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, fp);
res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
fclose(fp);
if(res != CURLE_OK) {
fprintf(stderr, "curl_easy_perform() failed: %s
", curl_easy_strerror(res));
}
}
return 0;
}
数据解析与提取
一旦获取了网页内容,接下来就是解析和提取所需数据,这里以提取网页中的所有链接为例,使用正则表达式进行匹配:
#include <regex.h>
#include <string.h>
void extract_links(const char html, const char pattern) {
regex_t regex;
regmatch_t pmatch[1];
const size_t nmatch = 1;
char cursor;
if (regcomp(®ex, pattern, REG_EXTENDED)) {
fprintf(stderr, "Could not compile regex
");
return;
}
cursor = (char )html;
while (!regexec(®ex, cursor, nmatch, pmatch, 0)) {
char match[1024];
strncpy(match, cursor + pmatch[0].rm_so, pmatch[0].rm_eo pmatch[0].rm_so);
match[pmatch[0].rm_eo pmatch[0].rm_so] = '