上一篇
html如何挖数据
浏览器开发者工具(F12)查看HTML结构并复制元素;或借助Python的HTMLParser库、正则表达式及R语言html_table函数等实现自动化提取
是关于如何使用HTML进行数据挖掘的详细指南,涵盖多种方法和工具:
浏览器开发者工具基础操作
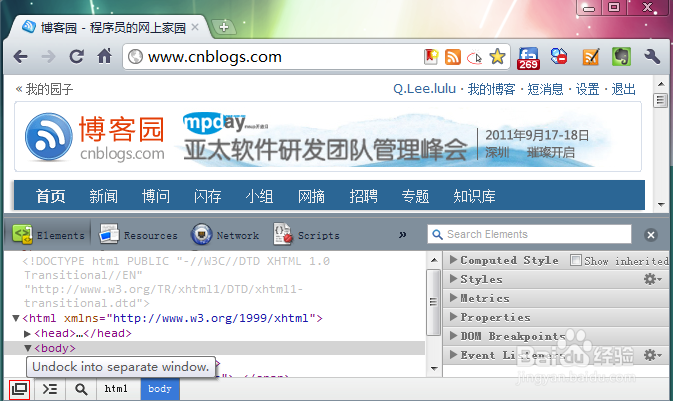
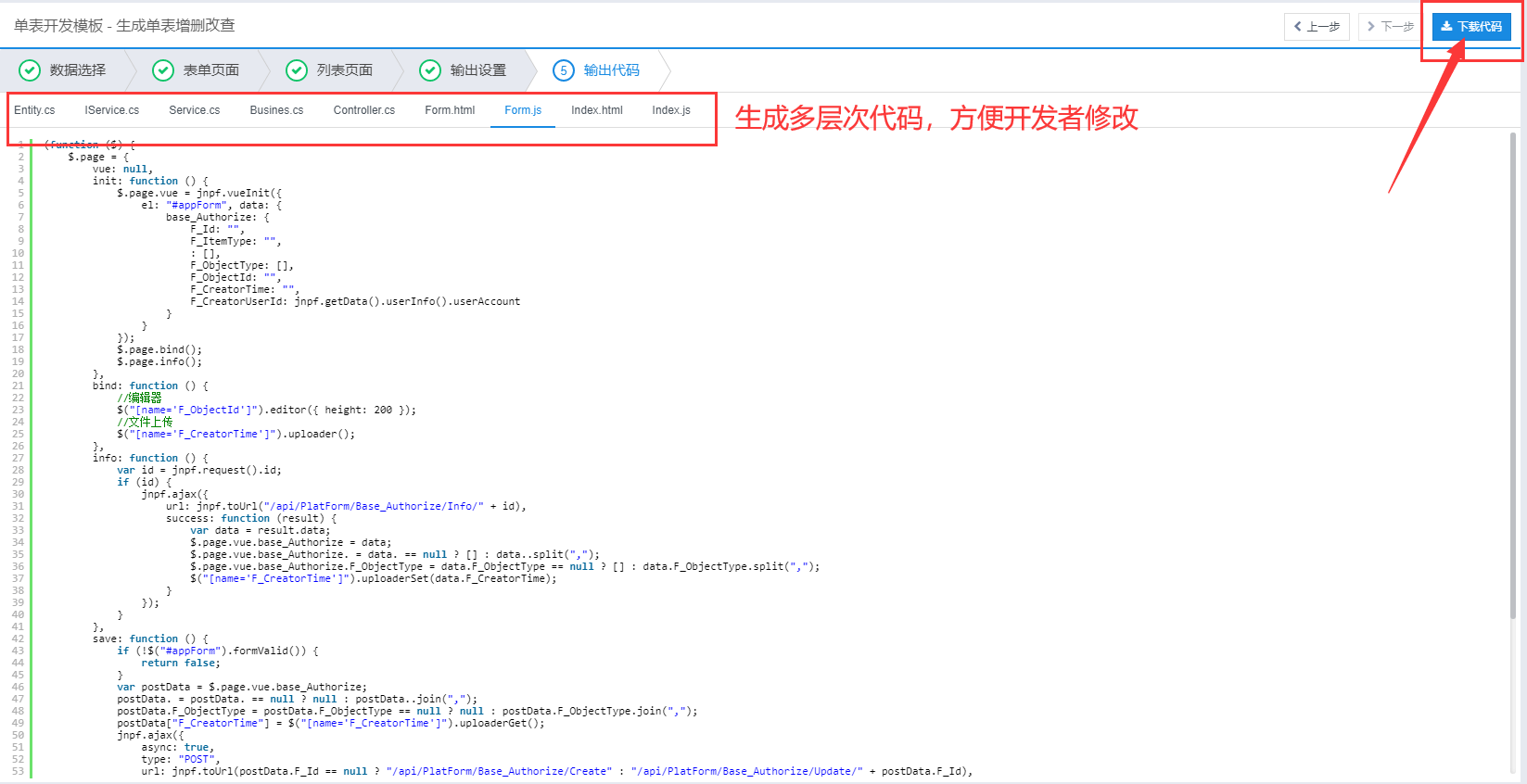
- 启动方式:打开目标网页后按下F12键或右键选择“检查”,进入开发者模式,界面分为两部分:左侧显示实时渲染效果,右侧呈现源代码结构,重点查看“元素”标签页下的DOM树形层级。
- 定位目标内容:通过鼠标悬停在页面元素上可高亮对应代码块;双击任意节点能快速编辑属性值,例如要提取商品价格时,找到包含数字的
<span class="price"> 复制技巧:右键点击所需节点→“复制”→可选“外部HTML”(完整片段)、“选择器”(CSS路径)或“文本内容”,这种方式适合少量数据的手动采集。
功能选项
适用场景
输出示例
外部HTML
保留标签结构的区块
<div id="box">...</div>
选择器
CSS路径定位
#main .item > p:nth-child(3)
编程库实现自动化抽取
Python方案
- BeautifulSoup解析器:配合requests库获取网页源码后,用soup.find_all()方法按标签名、类名等条件筛选元素,如
soup.select('table tr td')可遍历表格所有单元格。
- HTMLParser标准库:创建继承自该类的子类并重写handle_starttag等回调函数,适合处理复杂嵌套关系的数据流,例如遇到特定标签时触发事件记录日志。
- 正则表达式辅助:当目标数据分布在非标准位置时,可用re模块匹配模式,比如从混杂字符中提取手机号
r'(d{3})d{4}(d{4})'。
R语言方案
使用rvest包中的html_table()函数直接将整个表格转为data.frame格式,针对动态加载的内容,建议设置user_agent伪装浏览器访问头,避免被反爬机制拦截。

结构化数据处理策略
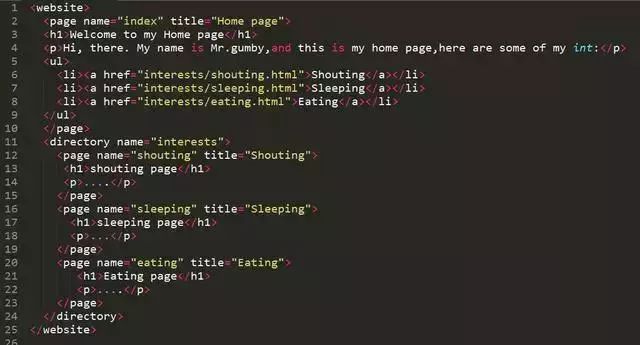
- 表格型数据优先:多数网站采用
<table>展示规整信息(如财报、榜单),通过tr/td层级关系构建二维数组存储每行记录,注意合并单元格需特殊处理。
- 列表项循环提取:对于重复出现的模块(如电商商品列表),先定位父容器再迭代子元素,例如京东手机详情页中,每个li标签代表一款机型参数集合。
- 属性值挖掘:除文本外还需关注src(图片地址)、href(跳转链接)、data-自定义属性等隐藏字段,这些往往携带关键元数据。
进阶技巧与注意事项
- 应对动态渲染页面:部分数据由JavaScript异步生成,此时需结合Selenium模拟人工操作,等待AJAX请求完成后再抓取结果集。
- 编码问题解决:指定response.encoding='utf-8'防止乱码;遇到GBK编码时可用chardet自动检测字符集。
- 法律合规性审查:遵守robots协议,不抓取敏感隐私信息;合理设置爬取频率避免给服务器造成压力。
FAQs
Q1: 为什么用开发者工具复制的数据粘贴到Excel会出现格式错乱?
A: 因为直接复制的是HTML源代码而非结构化数据,解决方法是先用编程方式解析成规范化格式(如CSV),再导入Excel,或者使用浏览器插件如Web Scraper预格式化导出。
Q2: 遇到加密的JSON数据该怎么解析?
A: 观察XHR网络请求中找到返回JSON的那个接口URL,直接请求该API获取明文数据,若参数加密过,则需要逆向分析加密算法