上一篇
数据库中数据表怎么写
库建表用
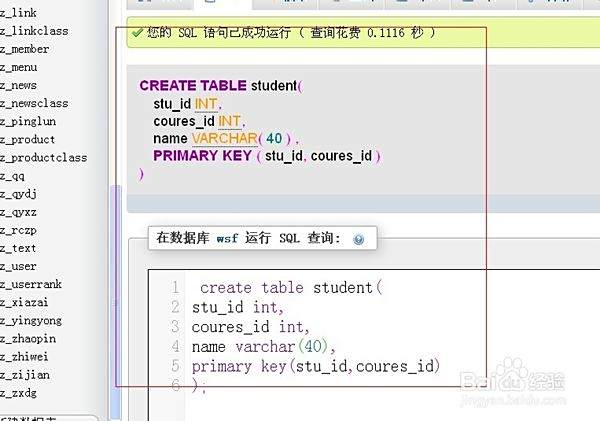
CREATE TABLE 语句,定义字段名、类型、约束等,如
id 设为主键自增。
明确需求与业务逻辑
在创建任何数据表之前,必须首先理解其用途。
- 目标是什么?(如记录用户信息、订单历史或产品库存)
- 需要哪些字段?(每个字段代表一种属性,如姓名、年龄、价格等)
- 数据之间的关系如何?(是否涉及多对一、一对多或多对多关联?)
以“电商平台的用户管理系统”为例,可能需要以下几张表:
| 表名 | 描述 | 关键字段示例 |
|————|————————–|—————————–|
| users | 存储注册用户的基本信息 | user_id, username, email, password_hash |
| orders | 记录用户的购物订单 | order_id, user_id, total_amount, create_time |
| products | 商品目录及详情 | product_id, name, price, stock_quantity |
通过拆分不同主题的数据到独立表中,可以避免冗余并简化维护工作。
定义列(Column)与数据类型
每一列都应有明确的名称、数据类型和约束条件,常见步骤包括:
命名规范
- 使用小写字母加下划线分隔单词(如
first_name),避免空格或特殊字符。 - 前缀可区分类别(如
dt_created表示日期时间型字段)。 - 示例对比:
User Name→user_name
选择合适的数据类型
根据实际存储内容选择最紧凑的类型以节省空间:
| 场景 | 推荐类型 | 说明 |
|——————–|——————-|——————————-|
| 整数计数 | INT/BIGINT | 适用于ID、数量等有限范围的值 |
| 精确小数 | DECIMAL(p,s) | p=总位数,s=小数位数(如货币) |
| 浮点近似值 | FLOAT/DOUBLE | 科学计算时使用,注意精度损失 |
| 定长字符串 | CHAR(n) | 固定长度文本(如邮政编码) |
| 变长字符串 | VARCHAR(maxlen) | 动态长度的内容(如地址描述) |
| 日期与时间 | DATETIME/TIMESTAMP | 包含年月日时分秒的信息 |
| 布尔标志位 | TINYINT(1) | 用0/1代替TRUE/FALSE |
设置默认值与非空约束
NOT NULL:强制用户必须提供该字段的值,用户的邮箱地址不应为空。DEFAULT:当插入新记录未指定某字段时自动填充预设值,将创建时间初始化为当前系统时间:created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP。
主键(Primary Key)的设计原则
- 唯一性:每个记录的唯一标识符,通常采用自增序列(AUTO_INCREMENT)生成。
user_id作为主键确保不会有两个相同的用户条目。 - 外键(Foreign Key)关联:建立表间引用关系,若存在外键约束,则子表中对应列的值必须在父表中存在。
orders.user_id引用users.user_id,保证所有订单都属于有效用户。
索引优化策略
索引能显著加速特定条件的检索速度,但滥用会导致写入性能下降,典型应用场景包括:

- 频繁查询的条件列:如按商品名称搜索时,可在
products.name上建索引。 - 排序操作涉及的列:ORDER BY子句使用的字段适合添加索引。
- 组合索引的顺序很重要:遵循“最左前缀”规则,优先匹配高频过滤条件,对于经常按地区+类别筛选的商品列表,应创建复合索引
(region, category)而非单独的两个单列索引。
️ 注意:过多的索引会增加磁盘占用并影响INSERT/UPDATE/DELETE的效率,需权衡利弊后谨慎添加。
规范化理论的应用
遵循数据库范式可以减少数据异常(插入异常、更新异常、删除异常),常用的三个级别如下:
| 范式等级 | 核心要求 | 示例改进 |
|———-|——————————————-|——————————————–|
| 第一范式(1NF) | 每列都是不可再分的基本单位 | 将嵌套数组拆分成多行 |
| 第二范式(2NF) | 消除部分依赖,所有非主属性完全依赖于主键 | 把与主键无关的属性移到其他表中 |
| 第三范式(3NF) | 去除传递依赖,非主属性间不存在间接联系 | 分离出冗余的描述性信息到专用字典表 |
原始设计可能存在这样的问题:同一个客户的多次购买记录重复保存了其联系方式,通过规范化处理,可以将联系人信息提取到单独的客户表中,仅保留客户ID在订单表中作为外键。
事务控制与并发安全
当多个用户同时修改同一资源时,可能出现脏读、幻读等问题,解决方案包括:
- ACID特性保障:Atomicity(原子性)、Consistency(一致性)、Isolation(隔离性)、Durability(持久化)。
- 锁机制的选择:悲观锁(Pessimistic Locking)适用于高冲突场景;乐观锁(Optimistic Locking)更适合读多写少的情况。
- 版本号机制:每次更新时递增版本号,提交前检查是否已被他人修改过。
扩展性考虑
随着业务增长,可能需要调整现有架构:
- 分区表(Partitioning):按范围、哈希等方式分散大数据量到多个物理文件中,提升查询响应速度。
- 分库分表:垂直分割(按业务模块拆分)或水平分割(按某种规则路由请求至不同服务器集群)。
- 归档策略:定期将历史数据迁移至低成本存储介质,释放主数据库压力。
文档化与团队协作
良好的注释习惯有助于后续维护:
CREATE TABLE IF NOT EXISTS employees (
emp_id INT PRIMARY KEY COMMENT '员工编号', -唯一标识符
full_name VARCHAR(50) NOT NULL COMMENT '全名', -包括姓和名
hire_date DATE NOT NULL COMMENT '入职日期', -格式YYYY-MM-DD
department_id SMALLINT REFERENCES departments(dept_id) -所属部门外键
);
建议使用ER图工具可视化表结构及其相互关系,方便新人快速上手。
相关问答FAQs
Q1: 如果两个表之间存在多对多关系怎么办?
A: 这时需要引入中间表(Junction Table)来桥接双方的主键,学生选课系统中,一个学生可以选择多门课程,一门课程也有多个学生选修,此时应创建第三个表student_course,包含两个外键分别指向students.student_id和courses.course_id,形成复合主键。
Q2: 为什么有时候即使没有显式声明外键也能正常执行SQL语句?
A: 因为外键约束是可选的功能,默认情况下数据库不会自动启用它,只有在创建表时明确指定FOREIGN KEY (...) REFERENCES ...语法,或者后续通过ALTER TABLE命令添加约束后,数据库才会强制执行参照完整性规则,某些开发环境为了追求极致性能可能会关闭此项功能,但这会增加应用程序层面的校验