上一篇
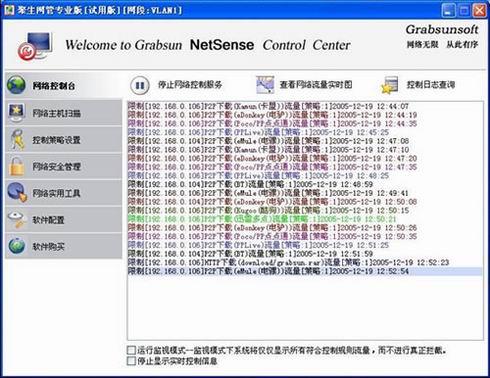
抓取ng各虚拟主机使用的流量
监控并统计各NG虚拟主机的流量使用情况,精准掌握资源
抓取目的与背景
在网络服务运维中,监控各虚拟主机(VPS/云服务器等)的流量使用情况至关重要,通过精准获取流量数据,可评估资源分配合理性、优化成本支出(如按流量计费场景)、排查异常访问或攻击行为,并为容量规划提供依据,本文将详细说明如何实现这一目标。
不同操作系统下的抓取方法
(一)Linux系统(以CentOS/Ubuntu为例)
-
工具选择:常用命令行工具包括
iftop(实时流量监控)、nload(可视化带宽统计)、sar(系统活动报告)及直接读取/proc/net/dev文件。/proc/net/dev是内核提供的原始网络接口统计路径,包含发送(tx)和接收(rx)字节数。- 示例命令:
cat /proc/net/dev | grep -E 'eth0|ens33'(替换为实际网卡名),输出类似:Interface RxBytes TxBytes ... eth0: 123456789 987654321 ...
此处“RxBytes”为接收总字节数,“TxBytes”为发送总字节数,单位均为字节(Byte),若需转换为MB,可除以
10241024。
- 示例命令:
-
脚本自动化:编写Shell脚本定时采集数据并存储至日志文件,每分钟记录一次某网卡的流量增量:
#!/bin/bash INTERFACE="eth0" # 目标网卡名 LOG_FILE="/var/log/traffic.log" while true; do CURRENT=$(cat /sys/class/net/$INTERFACE/statistics/rx_bytes) SLEEP 60 # 等待1分钟 NEXT=$(cat /sys/class/net/$INTERFACE/statistics/rx_bytes) DIFF=$((NEXT CURRENT)) echo "$(date '+%Y-%m-%d %H:%M:%S') $DIFF" >> $LOG_FILE done该脚本通过读取
/sys/class/net/[接口]/statistics/rx_bytes(接收)和tx_bytes(发送)实现高精度计时差统计。 -
第三方工具扩展:对于多台服务器集中管理场景,可使用Prometheus+Node Exporter组合,部署步骤如下:
- 安装Node Exporter服务端;
- 配置Prometheus的
prometheus.yml文件,添加目标地址; - 通过Grafana可视化展示各虚拟主机的
node_network_receive_bytes_total(总接收量)、node_network_transmit_bytes_total(总发送量)指标。
(二)Windows Server系统
Windows默认提供性能计数器(Performance Counters),可通过PowerShell或任务管理器查看,具体操作:
- PowerShell命令:
Get-Counter -Counter "Network Interface()Bytes Received/sec" -SampleInterval 5,其中匹配所有网络适配器,Bytes Received/sec表示每秒接收字节速率,若需累计总量,可结合时间积分计算。 - 任务管理器:切换至“性能”标签页→“网络”,勾选“查看详细统计数据”,即可看到每个进程的网络占用情况及总带宽利用率。
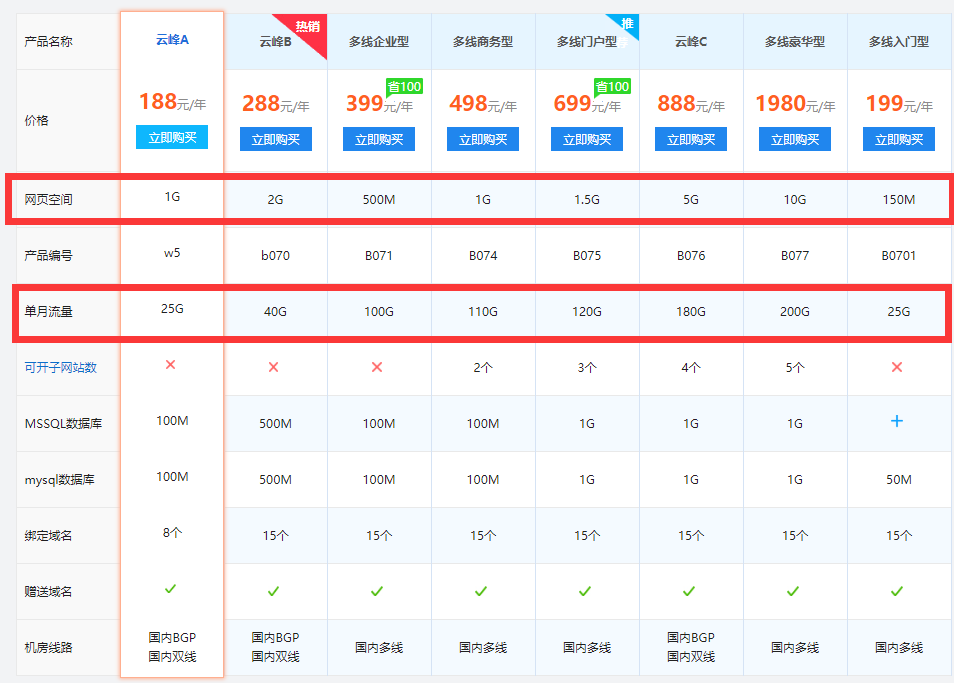
数据整理与展示示例表
以下为某日3台虚拟主机的流量汇总表(单位:GB):
| 主机ID | IP地址 | 接收流量(GB) | 发送流量(GB) | 总流量(GB) | 备注 |
|——–|————–|—————-|—————-|————–|———————-|
| VPS001 | 192.168.1.10 | 8.2 | 5.7 | 13.9 | Web服务主节点 |
| VPS002 | 192.168.1.11 | 2.1 | 3.4 | 5.5 | 数据库备份机 |
| VPS003 | 192.168.1.12 | 0.8 | 0.3 | 1.1 | 测试环境 |
注:表中数据基于当日24小时统计,可通过日志回溯任意时间段内的明细。
注意事项
- 单位一致性:确保所有数据统一为字节(Byte)、千字节(KB)或兆字节(MB),避免因单位混淆导致误差,部分工具默认显示KB/s,而日志可能记录的是Byte总量。
- 峰值与均值差异:突发流量(如大文件上传)可能导致瞬时速率远超平均值,需结合时间维度分析趋势,建议同时记录最大值、最小值及标准差。
- 跨地域影响:若虚拟主机分布在不同数据中心,需考虑网络延迟对流量统计的干扰(如TCP重传会增加实际传输量)。
- 权限限制:部分云服务商(如AWS Lightsail)仅提供接口级别的流量概览,无法细粒度到协议或端口,此时需依赖厂商API获取更详细信息。
相关问题与解答
Q1:为什么实际观察到的流量比应用层日志记录的大很多?
A:网络层统计的是原始数据包大小(含IP头、TCP/UDP头等开销),而应用层日志通常只计算有效载荷(Payload),一个HTTP请求的数据包总大小可能是1500字节,其中IP头占20字节、TCP头占20字节,实际业务数据仅1460字节,网络层流量会显著高于应用层感知的流量。
Q2:如何区分不同应用占用的流量?
A:可通过以下方法实现:
- Linux下使用
nethogs工具,按进程实时显示带宽占用; - Windows通过任务管理器的“详细信息”标签页,查看各进程的网络利用率;
- 企业级方案可部署深度包检测(DPI)设备或软件(如Zeek),解析数据包内容并标记应用类型(HTTP/HTTPS、FTP等)。